
3 ключові інструменти дата-інженера
Big Data Consultant Антон Бондар — про Apache Hadoop, Apache Spark та Apache Airflow
Якщо обсяг даних перевищує десяток гігабайтів, то варто використовувати спеціальні технології для обробки, зберігання та управління дата-пайплайнами. Ключова навичка дата-інженера — знання цих технологій.
Антон Бондар, Big Data Consultant у Cognizant розповідає про три основні інструменти дата-інженера.
Незнання застосовуваних технологій призводить до:
- Невиконання потрібних SLA (service-level agreement). Дата-інженерам встановлюють терміни: як швидко потрібно обробити дані та надати внутрішнім і зовнішнім користувачам. Ще важливіше це у випадках, коли real-time аналітика — ключовий елемент бізнесу.
- Збільшення витрат на інфраструктуру. Data Engineering рухається в бік cloud. Оскільки вартість використання та підтримки on-premises Big Data інфраструктури є досить високою, а обробляти великі обсяги даних зараз можуть навіть маленькі компанії, хмарні провайдери залучають Pay-as-you-Go модель тарифікації: ви сплачуєте лише за ті ресурси, які задіюєте. У такій ситуації неефективне застосування інструментів призведе до перевитрати обчислювальних ресурсів. А це виллється в додаткові десятки тисяч доларів витрат.
Розберемо найпопулярніші інструменти дата-інженерії, здатні обробляти будь-які доступні обсяги даних.
Apache Hadoop
Технологія, що з’явилася 2006 року, дала змогу зберігати, обробляти й аналізувати дуже великі обсяги даних. Big Data у сучасному розумінні почалася з цієї технології.
Apache Hadoop — набір бібліотек і фреймворк для виконання розподілених програм на кластерах, що складаються із сотень і тисяч серверів. Hadoop натхненний Google MapReduce — моделлю програмування, що розбиває завдання на однакові підзадачі, які розподіляються за нодами кластера.
З Apache Hadoop починається історія Data Lake. Hadoop демократизував використання обчислювальних потужностей, дедалі більше і більше компаній могли собі дозволити аналізувати й писати запити до великих обсягів даних, горизонтально масштабуючи свої обчислювальні потужності.
Крім Hadoop Common (набору сервісів, бібліотек і утиліт, які підтримують роботу інших модулів Hadoop), Apache Hadoop складається з трьох модулів:
- HDFS (відповідає за розподілене зберігання даних на кластері);
- MapReduce (рушій обробки даних);
- YARN (використовують для управління ресурсами кластера і планування завдань).
Data Engineer найчастіше працює з HDFS і MapReduce.
HDFS (Hadoop Distributed File System)
Зовні HDFS схожа на будь-яку іншу POSIX-файлову систему, ми можемо бачити список файлів і директорій, давати користувачам права на застосування певних папок і встановлювати заборону на інші, а також завантажувати файли до кластера Hadoop і вивантажувати з нього.
З першого погляду можливості HDFS не вражають, але тут важливо, як дані зберігаються «під капотом», адже саме HDFS дав поштовх підходу Data Lake і досі залишається одним з небагатьох способів імплементації Data Lake on-premises.
Нагадаємо, який вигляд має архітектура Apache Hadoop.
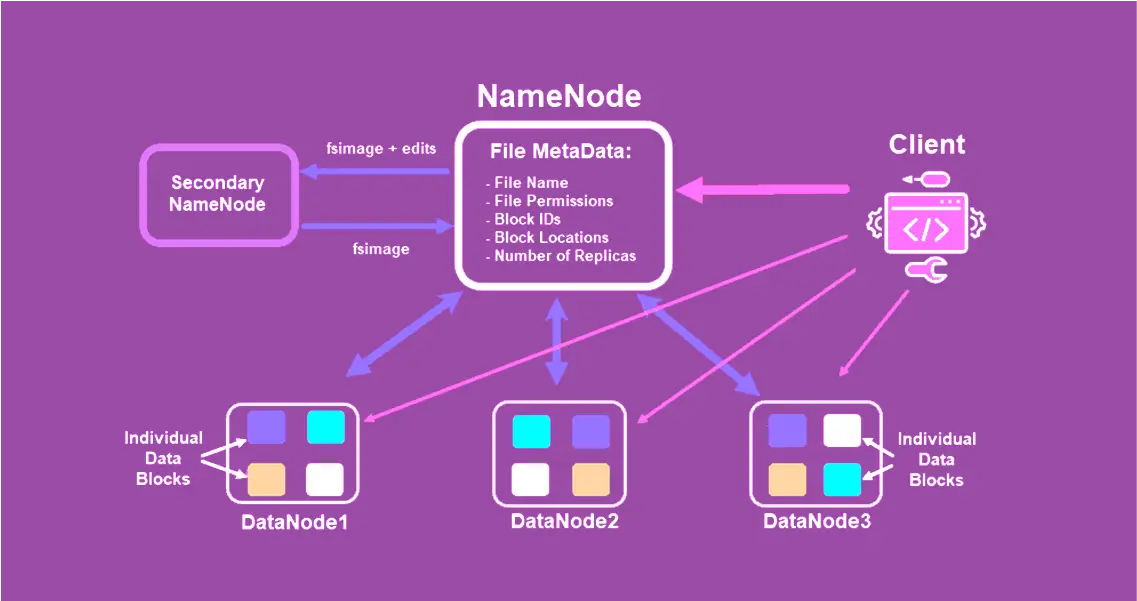
Дані/файли в HDFS зберігаються на Data Nodes, але не в чистому вигляді. Коли користувач/програма завантажують файл у Hadoop, то надсилають файл на Name Node (усе спілкування між кластером Hadoop і зовнішнім світом відбувається через Name Node). Він розбиває вхідний файл на кілька блоків (по 128 Мб кожен) і розсилає на різні Data Nodes.
Логіка в тому, щоб блоки одного файлу обов’язково перебували на різних Data Nodes і, відповідно, різних серверах Hadoop-кластера. Після кожен блок файлу копіюється двічі, і ці дві копії початкового блоку копіюються на будь-які інші дві Data Nodes. З’ясуємо, для чого.
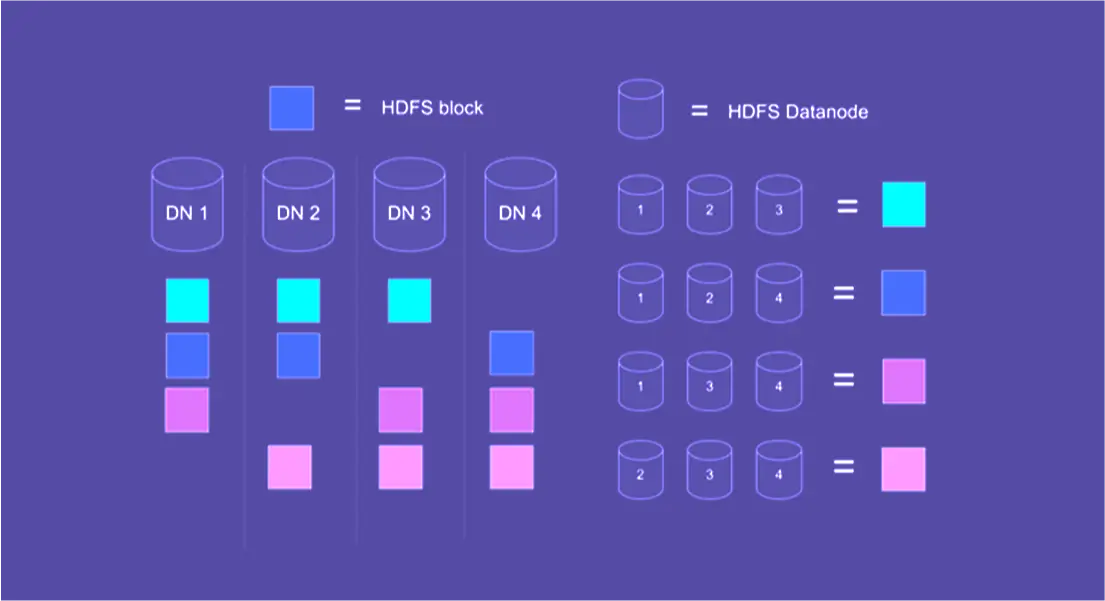
Як показано на малюнку, вхідний файл розбили на 4 блоки й кожен блок скопіювали два рази. Якщо впаде одна або навіть дві (!) Data Nodes, файл все одно залишиться доступним. Падіння одиничних серверів у великому навантаженому кластері — звичайна справа.
Інший важливий плюс у тому, що ми можемо вивантажувати великий файл з HDFS не послідовно, а паралельно — викачуючи різні його блоки одночасно з декількох серверів Hadoop-кластера. Це дає прискорення вивантаження, кратне кількості Data Node, на яких розташовані блоки файлу.
Такий підхід дає змогу практично безмежно горизонтально масштабуватися. Закінчується місце в Data Lake? Додайте новий сервер у кластер і призначте його Data Node.
MapReduce
Це рушій (processing engine) для паралельного опрацювання великих датасетів. Розберемо на прикладі, як він влаштований.
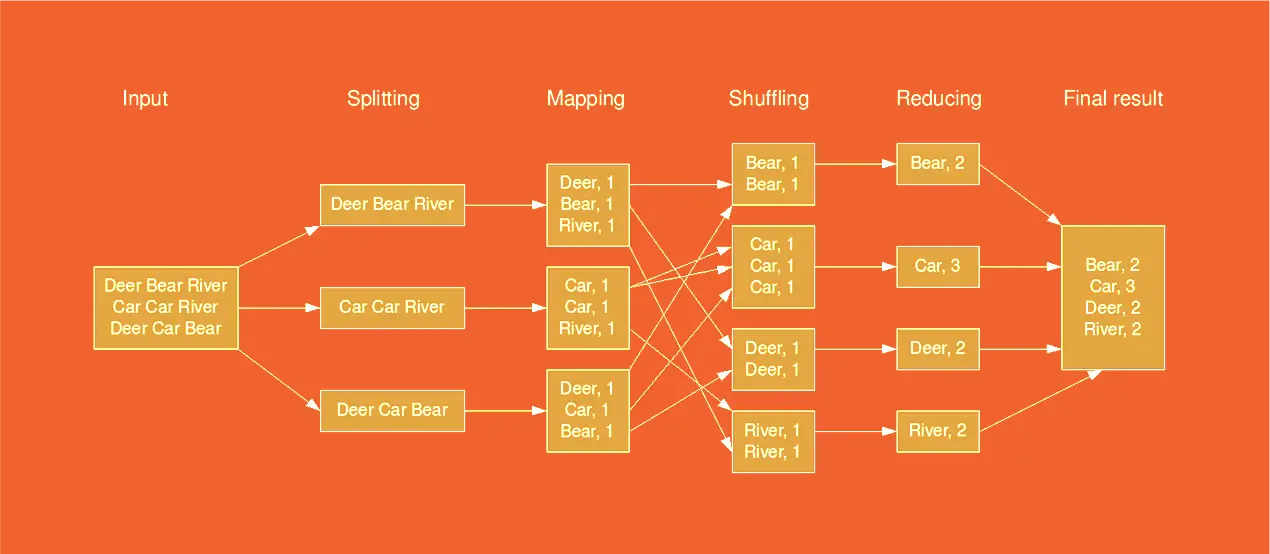
Процес підрахунку слів MapReduce
Вхідний файл — текст у форматі .txt, який ми завантажили в Hadoop, і зараз він, розбитий на блоки, лежить у HDFS. Наше завдання — проаналізувати файл, склавши список унікальних слів і встановивши, скільки разів кожне з них трапляється в цьому тексті.
Спочатку виконується операція mapping. Hadoop MapReduce бере кожен блок і присвоює кожному слову значення 1. Виходить список у форматі «ключ — значення», де ключ — слово, і воно не є унікальним у межах списку, а значення — одиниця.
Потім відбувається shuffling: Data Node починають обмінюватися парами «ключ — значення» так, щоб наприкінці операції однакові ключі були поруч. Відразу після цього починається операція reducing: значення однакових ключів підсумовуються. На виході формується файл зі списком унікальних слів та їхньою кількістю в тексті.
Операції map і reduce виконуються окремо для кожного блоку на кожній Data Node.
// Функція, що використовується робочими нодами на Map-кроці
// для обробки пар ключ-значення із вхідного потоку
void map (String name, String document):
// Вхідні дані:
// name - назва документа
// document - вміст документа
for each word w in document:
EmitIntermediate(w, "1");
// Функція, що використовується робочими нодами на Reduce-кроці
// для обробки пар ключ-значення, отриманих на Map-кроці
void reduce(String word, Iterator partialCounts):
// Вхідні дані:
// word - слово
// partialCounts - список групованих проміжних результатів. Кількість записів у partialCounts
і є
// необхідне значення
int result = 0;
for each v in partialCounts:
result += parseInt(v);
Emit(AsString(result));
Так відбувається розподілена обробка даних у Hadoop. Бракує потужності, джоби відпрацьовують повільно, а код і так максимально оптимізований? Додаємо новий сервер у Hadoop-кластер і призначаємо його Data Node — так ми зможемо виконувати більше операцій Map або Reduce паралельно.
MapReduce — дуже живучий підхід для обробки даних. Якщо під час виконання MapReduce впала третина кластера, то він, хоч і з затримками, успішно завершить джобу.
Головний недолік Hadoop MapReduce — низька ефективність. Багато технологій можуть здійснювати ті самі операції, що й MapReduce, в рази швидше. Наприклад, Apache Spark, Apache Impala, Apache Mahout.
Крім того, MapReduce підтримує не всі види операцій над даними. На малюнку вище видно, що блоки з даними розділені й обробляються незалежно один від одного. За допомогою MapReduce неможливо проаналізувати взаємини між елементами, він підтримує тільки послідовні аналітичні операції.
Проте у MapReduce є вагомий плюс. Зазвичай, коли ми хочемо обробити дані, то приносимо їх до обчислювальних потужностей. Але з Hadoop MapReduce все навпаки: дані й так лежать у HDFS, який виступає Data Lake’ом. Перша операція Map виконується на тих самих Data Nodes, де лежать блоки з даними.
Apache Spark
Це Big Data фреймворк для розподіленого оброблення даних в оперативній пам’яті. Spark підтримує обробку і структурованих даних (у вигляді таблиць), і напівструктурованих (json, yaml, xml тощо), і неструктурованих (тексти та інші медіаформати).
Spark — частина Hadoop Ecosystem, але може як взаємодіяти з Hadoop-кластером, брати й зберігати дані на HDFS і виконуватися на тих самих серверах кластера, що й Hadoop, так і працювати незалежно від Hadoop.
В Apache Spark є API (не Web-API) для чотирьох мов програмування: Python, Java, Scala, R.
Оскільки Spark здебільшого написаний на Scala, для досягнення максимальної ефективності краще використовувати Scala і (меншою мірою) Java.
Але найпопулярніша мова для написання Spark Job — Python. Вона надає просте і зрозуміле API для взаємодії зі Spark, яке підвищує читабельність коду і спрощує його підтримку. Також Python додає безліч опцій для візуалізації даних, застосування яких неможливе в Scala або Java.
PySpark (інтерфейс Spark для Python) за використання основного модуля Spark SQL зазвичай дає таку саму продуктивність, як і будь-яка інша мова програмування. Apache Spark дає змогу ефективно обробляти дані. Наприклад, програма WordCount, про яку ми говорили вище, виконується в ньому в 100 разів швидше, ніж у Hadoop MapReduce. Це можливо завдяки розподіленій архітектурі та in-memory розрахункам.
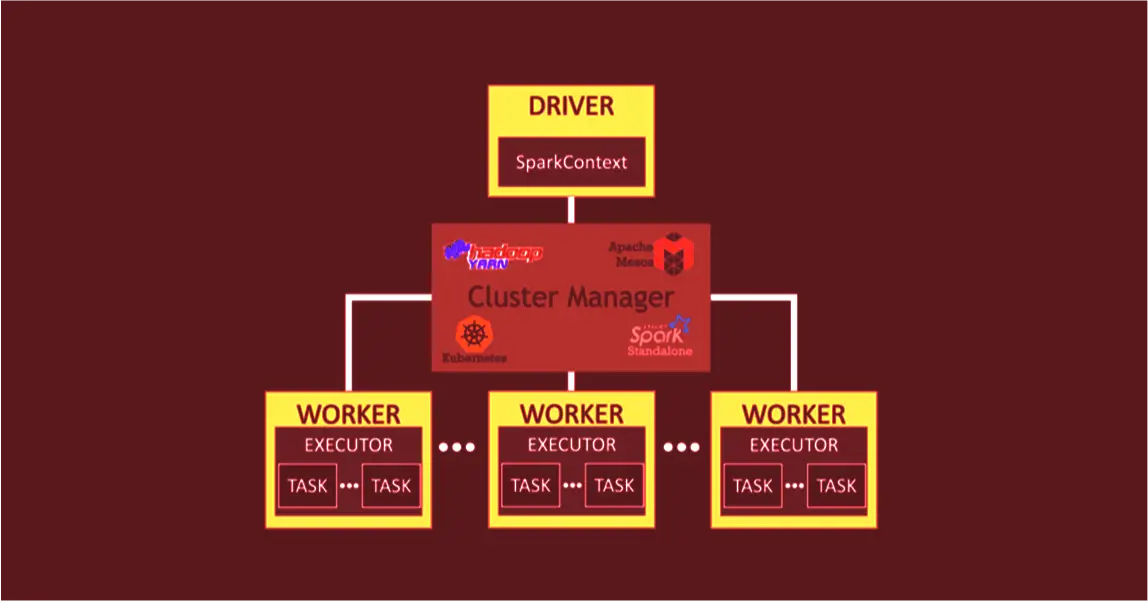
Усі обчислення в Spark відбуваються в оперативній пам’яті.
Spark здатний виконувати як пакетну, так і потокову обробку даних.
Apache Spark складається з чотирьох компонентів:
- MLlib — бібліотека інструментів для ML-завдань;
- Streaming — інструменти для real-time аналітики;
- SQL — модуль для роботи зі структурованими даними;
- GraphX — бібліотека для процесингу графових структур даних.


В Apache Spark дані можуть бути представлені у вигляді RDD (Resilient Distributed Dataset), DataFrame і Dataset.
RDD — основна структура даних у Spark, DataFrames і Datasets — надбудови над RDD. Їх рекомендовано використовувати, якщо ви добре знаєте свої дані та розумієте, як працюють «нутрощі» Spark. RDD дають змогу здійснювати низькорівневі трансформації над неструктурованими даними (як медіа або текст).
Dataframe зовні — аналог Python Pandas Dataframes, але з кращою оптимізацією «під капотом». На відміну від RDD, дані в DataFrame організовані в колонки, як у реляційних СУБД. Dataframe допомагає структурувати дані та надає зручний API для обробки даних, що зберігаються розподілено.
Dataset — відносно новий вид представлення даних в Apache Spark. Він об’єднує переваги RDD (сувора типізація і можливість застосування низькорівневих lambda-функцій) з оптимізацією Spark SQL. Dataset не представлений у Python і R API, але деякі його можливості доступні в Dataframe.
Spark SQL — модуль для роботи зі структурованими даними. Знати його обов’язково. На відміну від RDD, він вводить нову концепцію — DataFrame, який дає більше розуміння про структуру оброблюваних даних і про операції, які виконуються над даними. «Під капотом» Spark цю інформацію використовують для додаткової оптимізації.
Є два способи для взаємодії зі Spark SQL: SQL і DataFrame API. Який би спосіб ви не обрали, рушій буде однаковим.

Одна й та сама логіка, однакова продуктивність, але різний код.
У коді прихована ще одна особливість Apache Spark — lazy evaluation. Коли Spark читає код і бачить трансформації даних, він не починає їх виконувати, а заносить у DAG (спрямований ациклічний граф), де послідовно зберігає всі операції, які ви хочете зробити над даними. Коли ви викликаєте «дію» — хочете порахувати кількість рядків у DataFrame, зберегти дані у файл або в базу даних, — Spark починає аналізувати DAG з усіма операціями, складає оптимальний план трансформацій і починає їх.
Інший важливий модуль — Spark Streaming. Він працює навіть не з потоковими даними, а з micro-batches, тобто бере маленькі шматочки даних з потоку й обробляє їх по черзі. Попри це, Spark зарекомендував себе як Production Grade IoT-рішення.
Якщо ви вже використовуєте DataFrame API, то концепція Structured Streaming дасть вам змогу працювати з потоковими даними так само, як зі статичними.
Apache Airflow
Це opensource-інструмент для розробки, менеджменту й моніторингу дата-пайплайнів (ETL-процесів). Уся логіка в ньому описується лише кодом на Python. Головна перевага цього — ви можете використовувати Git для версіювання ETL-завдань.
Основна концепція в Airflow — DAG, та сама структура даних, що й Apache Spark. Але тут DAG — окреме ETL-завдання, розбите на кроки, які йдуть у суворій послідовності.
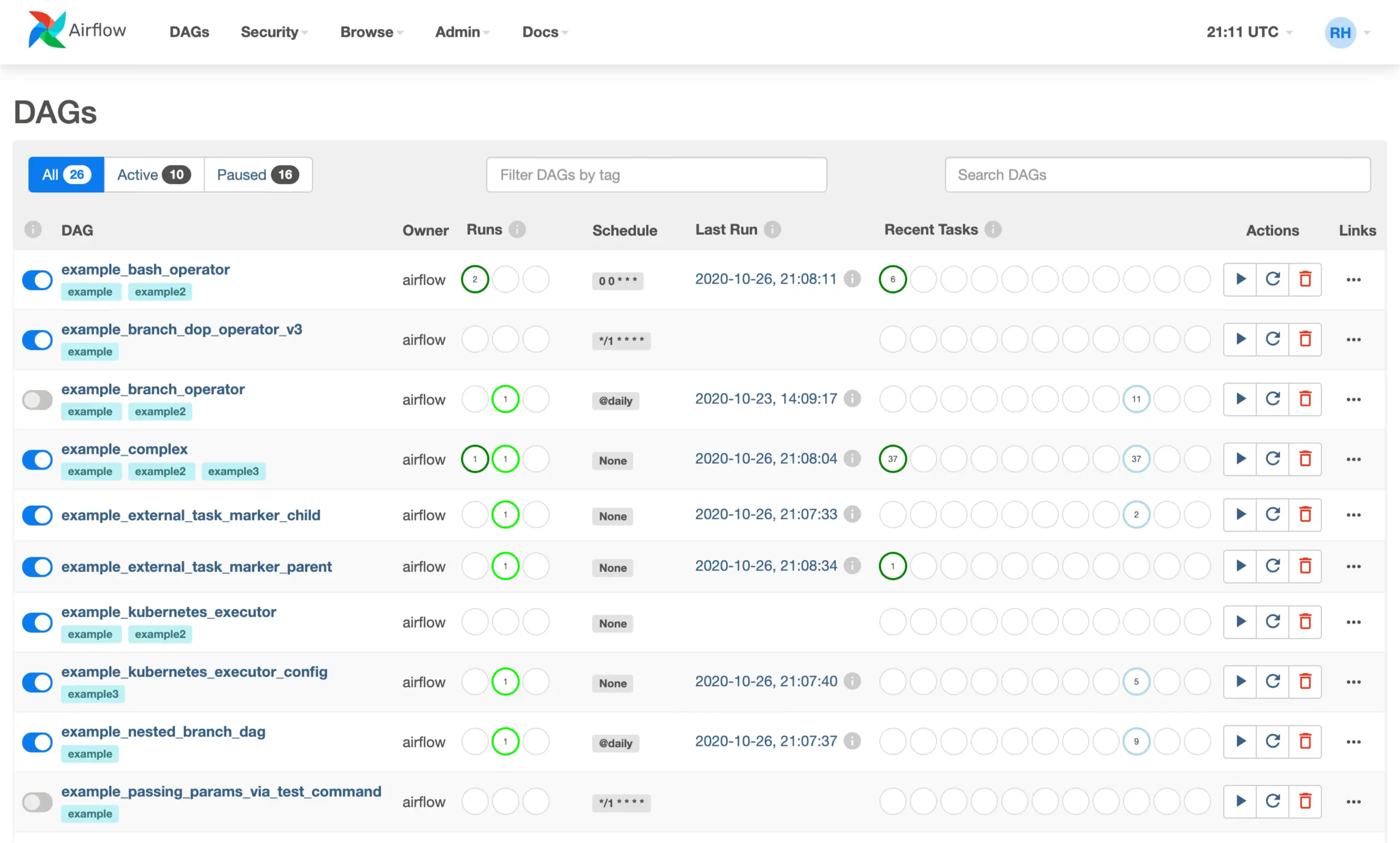
Інтерфейс Airflow
На головному екрані перелічені всі DAG’и, дата останнього запуску, кількість запусків, їхній результат та інша інформація.
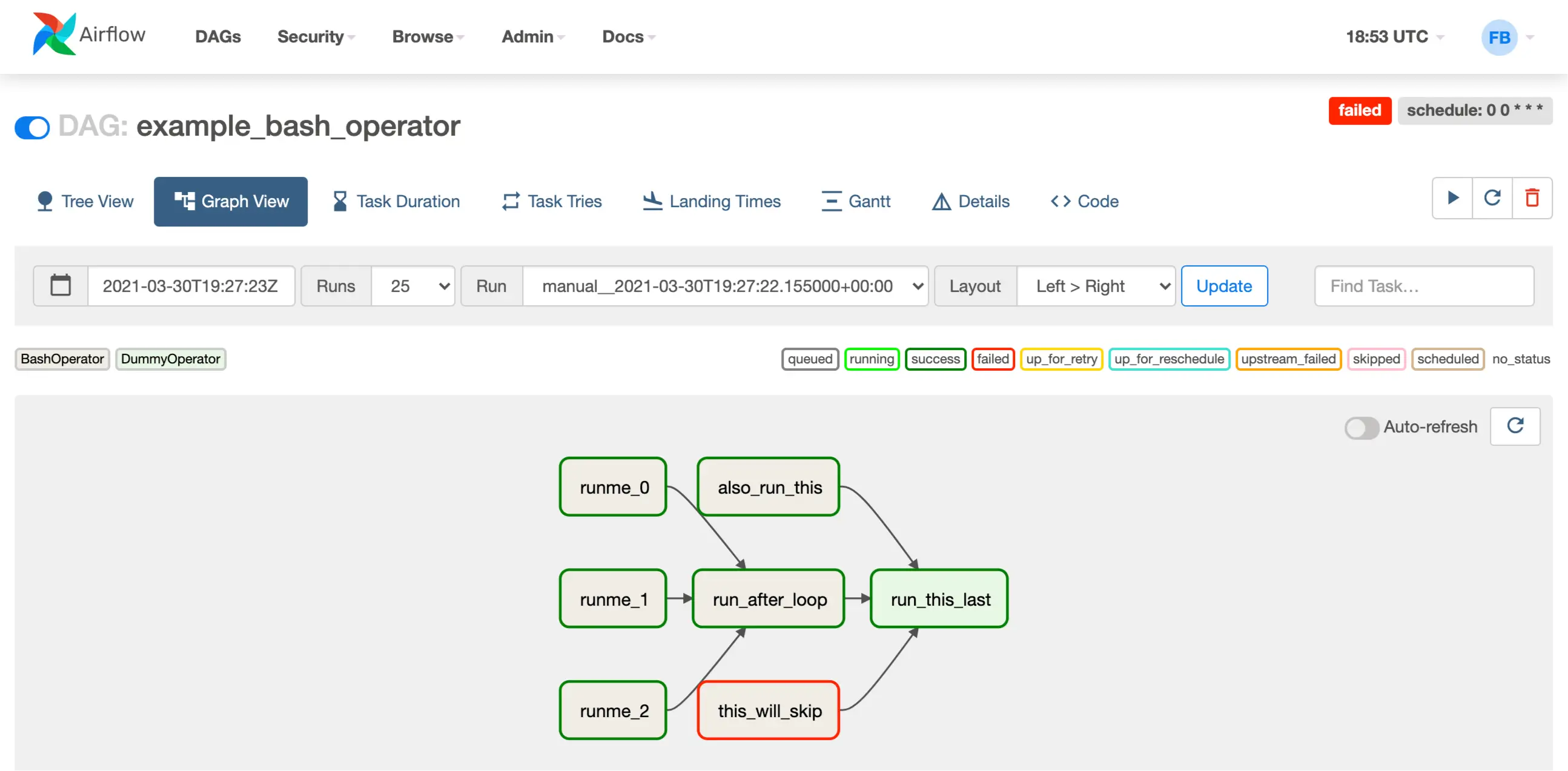
Інтерфейс окремо взятого DAG'а
Кожен крок у DAG позначений окремим блоком. Кожному кроку ви можете призначити додаткову логіку — сказати, що робити, якщо крок закінчився з помилкою, або задати послідовність виконання в різних випадках. Також можна дізнатися додаткову інформацію кожного кроку, включно з докладними логами щодо виконання, його часом і детальним описом помилок, якщо вони були. Усе це описується звичайним Python-кодом, до того ж він має абсолютно pythonic вигляд.
У Airflow величезна кількість конекторів до зовнішніх джерел даних: файлів, СУБД, API клауд-провайдерів (AWS S3, Azure Storage, GCP Storage), а також до зовнішніх рушіїв для обробки даних (Apache Spark, Hadoop MapReduce). Якщо потрібного оператора для роботи з даними або конекшну до рушія немає, то функціональність Airflow легко розширюється самописними модулями. Airflow спочатку проєктували так, щоб ви могли змінювати вбудований набір функцій під свої завдання.
Apache Airflow нав’язує вам принципи гарної інженерії: успадкування функціональності й перевикористання коду. Крім цього, у нього багато додаткових інструментів, зокрема вбудоване сховище паролів, змінних, NoSQL-база даних для зберігання метаданих.


