< власний data pipeline >
Big Data: обробка та аналітика
Опануйте Spark, Databricks, Kafka, dbt та Airflow, щоб перетворювати великі дані на дієві рішення.
Денис Кулемза
Senior Data Engineer в Intellias
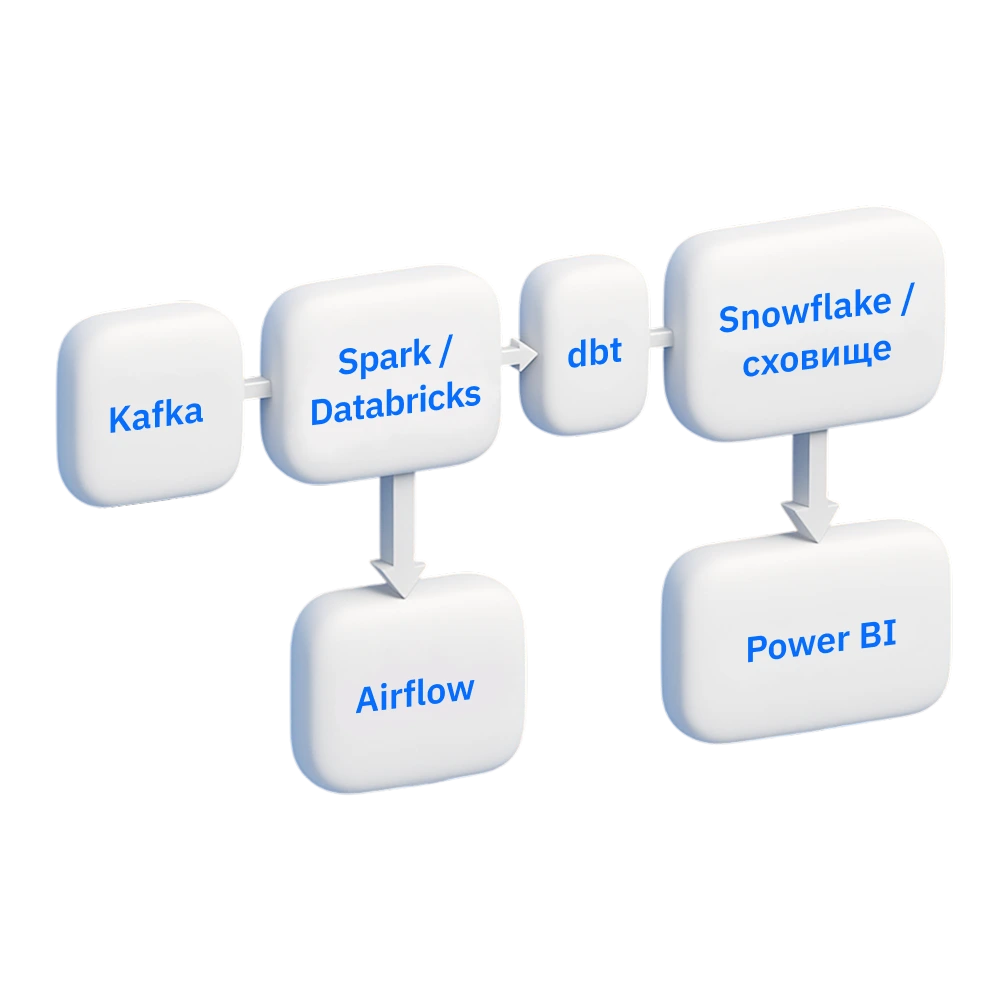
які хочуть будувати ефективніші пайплайни зі Spark, Kafka та dbt, шукають стабільніші флоу та можливості кращої оркестрації через Airflow
які хочуть зрозуміти, який вигляд мають дані за лаштунками: від потоків до моделювання, а також хочуть отримати більше контролю над даними, з якими працюють
які хочуть перейти в data-напрям, прокачати роботу з логами, подіями, схемами та краще розуміти архітектуру сучасних data-пайплайнів

- навчитеся налаштовувати середовище у Snowflake, зможете реалізовувати ELT/ETL-сценарії
- будете автоматизувати процеси за допомогою Kafka та Airflow
- зрозумієте, як інтегрувати інструменти Big Data у бізнес-процеси
- застосовуватимете найкращі практики роботи з Big Data на основі реальних кейсів
Опануєте Apache Spark, Databricks, Kafka, Snowflake, dbt, Airflow, AWS Athena, Power BI, щоб проєктувати стабільні системи обробки даних — від збору до візуалізації.
Побудуєте повний цикл обробки даних: збір, трансформація, перевірка якості, збереження та візуалізація.
Дізнаєтесь, як перевіряти дані на точність, налаштовувати тести в dbt й автоматизувати контроль якості в пайплайнах.

- зрозумієте відмінність між сховищами даних, data lakes і lakehouse-архітектурою
- дізнаєтеся про переваги та недоліки кожного підходу залежно від бізнес-сценарію
- вивчите патерни обробки даних — пакетну й потокову — та їхній вплив на архітектуру пайплайна
- зрозумієте розподілену модель виконання в Spark
- навчитеся виконувати базові трансформації та дії з DataFrame
- дізнаєтеся, коли краще використовувати DataFrame API, а коли — Spark SQL
- дізнаєтеся, як виявляти й усувати проблеми з продуктивністю в Spark
- навчитеся використовувати партиціювання, кешування й broadcast joins для оптимізації
- зрозумієте, як читати Spark UI для покращення виконання завдань і розв’язання проблем зі skew
- дізнаєтеся, з чого складається AWS EMR та як працюють його компоненти (Hadoop, Spark, Hive тощо)
- навчитеся налаштовувати EMR-кластери для зручної та масштабованої роботи зі Spark
- навчитеся налаштовувати робоче середовище Databricks в AWS
- зрозумієте життєвий цикл кластерів і як оптимізувати витрати
- дізнаєтеся, як підключати Databricks до хмарних сховищ, зокрема ADLS
- навчитеся писати й виконувати SQL-запити в Databricks
- дізнаєтеся, як використовувати Databricks SQL для BI-аналітики
- зрозумієте, як оптимізувати запити й працювати з продуктивністю
- дізнаєтеся, як Unity Catalog централізує управління даними в Databricks
- навчитеся налаштовувати каталоги, схеми та доступи для безпеки даних
- зрозумієте можливості аудиту й відстеження походження даних (data lineage)
- дізнаєтеся, як оцінювати й оптимізувати витрати на Databricks
- навчитеся покращувати продуктивність ноутбуків і дотримуватися best practices
- вмітимете швидко знаходити й усувати проблеми з конфігурацією чи продуктивністю
- зрозумієте відмінність між Star- та Snowflake-схемами
- навчитеся обирати відповідний підхід для моделювання
- вмітимете розробляти базові аналітичні схеми «зірка» та «сніжинка»
- дізнаєтесь основні принципи роботи Snowflake як хмарного DWH
- навчитеся налаштовувати середовище, створювати таблиці та працювати з Warehouse
- зможете завантажувати дані у Snowflake та виконувати SQL-запити
- зрозумієте ключові переваги Snowflake у порівнянні з іншими сховищами
- дізнаєтесь, як автоматизувати процеси в Snowflake за допомогою Tasks і Streams
- навчитеся реалізовувати сценарії ELT/ETL безпосередньо у Snowflake
- ознайомитеся зі способами шерингу даних і налаштуванням доступів
- зрозумієте, як використовувати Time Travel та Zero-Copy Cloning у проєктах
- навчитеся організовувати dbt-проєкт за рекомендованою структурою
- розберетесь із синтаксисом Jinja та створенням модульних SQL-шаблонів
- зможете створювати аналітичні моделі у форматі схем зірки або сніжинки за допомогою dbt
- навчитеся створювати тести й макроси для перевірки якості та цілісності даних
- зможете автоматизувати документацію та оповіщення для прозорості процесів
- розберетесь із розширеним синтаксисом Jinja для скорочення повторюваного коду
- навчитеся описувати ключові концепції Kafka — topics, partitions, offsets
- зрозумієте, як Kafka забезпечує обробку даних у реальному часі
- зможете інтегрувати Kafka з іншими системами для подієво-орієнтованих архітектур
- дізнаєтесь, як реалізувати інкрементну обробку даних у Spark Structured Streaming
- навчитеся працювати з невпорядкованими подіями за допомогою watermarking і windowing
- зможете розгорнути стримінговий конвеєр від Kafka до Delta Lake
- зрозумієте переваги Kafka та Spark для real-time і stateful-обробки даних
- навчитеся створювати та налаштовувати потоки в AWS через Amazon Kinesis Data Analytics
- зможете реалізувати трансформації потоків: вікна, стани й checkpointing
- дізнаєтеся про моделі NoSQL: key-value, документну та колонкову
- навчитеся проєктувати ключі партицій для масштабованості
- зрозумієте суть CAP-теореми та компроміси між узгодженістю й доступністю
- навчитеся здійснювати SQL-запити до даних у дата-озерах
- дізнаєтесь, як Athena масштабується та як оцінити її вартість
- зрозумієте, як партиціювання й зовнішні схеми пришвидшують аналітику
- навчитеся створювати DAG в Airflow для автоматизації ETL
- зрозумієте, як керувати розгортанням через Git та CI/CD
- дізнаєтесь, як працювати з розкладами, бекфілами та покращувати надійність
- навчитеся керувати завданнями Databricks через Airflow
- зможете запускати dbt-команди й налаштовувати змінні середовища
- дізнаєтесь, як централізувати розклади, логування та обробку помилок
- навчитеся підключатися до джерел, трансформувати й візуалізувати дані в Power BI
- дізнаєтесь, у чому відмінності між DirectQuery, Import та Live Connection
- дізнаєтесь, як підключити Power BI до Databricks Lakehouse для аналітики в реальному часі
- навчитеся налаштовувати розклади оновлення та працювати з потоковими наборами даних
- опануєте захист доступу до даних через AWS IAM
- розберете всі неточності й отримаєте відповіді на запитання, що виникли під час проходження курсу Big Data
- реалізуєте та презентуєте data pipeline на базі Lambda-архітектури з використанням Databricks, dbt, Kafka, Snowflake і Power BI
Реєстрація
Реєструйтеся на курс, щоб Big Data почали працювати на вас:
від розв'язання щоденних завдань до
професійного зростання на ринку.
СТАРТ НАВЧАННЯ — У КВІТНІ 2026 РОКУ