
3 ключевых инструмента дата-инженера
Big Data Consultant Антон Бондарь — об Apache Hadoop, Apache Spark и Apache Airflow.
Если объем данных превышает десяток гигабайт, то стоит использовать специальные технологии для обработки, хранения и управления дата-пайплайнами. Ключевой навык дата-инженера — знание этих технологий.
Антон Бондарь, Big Data Consultant в Cognizant рассказывает о трех основных инструментах дата-инженера.
Незнание используемых технологий ведет к:
- Невыполнению необходимых SLA (service-level agreement). Дата-инженерам устанавливают сроки: как быстро данные должны быть обработаны и предоставлены внутренним и внешним пользователям. Еще важнее это в случаях, когда real-time аналитика — ключевой элемент бизнеса.
- Увеличению затрат на инфраструктуру. Data Engineering движется в сторону cloud. Поскольку стоимость использования и поддержки on-premises BigData-инфраструктуры достаточно велика, а обрабатывать большие объемы данных сейчас могут даже маленькие компании, облачные провайдеры используют Pay-as-you-Go-модель тарификации: вы платите только за те ресурсы, которые используете. В такой ситуации неэффективное применение инструментов приведет к перерасходу вычислительных ресурсов. А это выльется в дополнительные десятки тысяч долларов затрат.
Разберем самые популярные инструменты дата-инженерии, способные обрабатывать любые доступные объемы данных.
Apache Hadoop
Технология, появившаяся в 2006 году, позволила хранить, обрабатывать и анализировать очень большие объемы данных. Big Data в современном понимании началась с этой технологии.
Apache Hadoop — набор библиотек и фреймворк для выполнения распределенных программ на кластерах, состоящих из сотен и тысяч серверов. Hadoop вдохновлен Google MapReduce — моделью программирования, которая разбивает задачу на одинаковые подзадачи, распределяемые по нодам кластера.
С Apache Hadoop начинается история Data Lake. Hadoop демократизировал использование вычислительных мощностей, все больше и больше компаний могли себе позволить анализировать и писать запросы к большим объемам данных, горизонтально масштабируя свои вычислительные мощности.
Помимо Hadoop Common (набора сервисов, библиотек и утилит, которые поддерживают работу остальных модулей Hadoop), Apache Hadoop состоит из трех модулей:
- HDFS (отвечает за распределенное хранение данных на кластере)
- MapReduce (движок обработки данных)
- YARN (используется для управления ресурсами кластера и планирования задач)
Data Engineer чаще всего работает с HDFS и MapReduce.
HDFS(Hadoop Distributed File System)
Внешне HDFS похожа на любую другую POSIX-файловую систему, мы можем видеть список файлов и директорий, давать пользователям права на использование определенных папок и устанавливать запрет на другие, а также загружать файлы в кластер Hadoop и выгружать из него.
С первого взгляда возможности HDFS не впечатляют, но тут важно, как именно данные хранятся «под капотом», ведь именно HDFS дал толчок подходу Data Lake и до сих пор остается одним из немногих способов имплементации Data Lake on-premises.
Напомним, как выглядит архитектура Apache Hadoop.
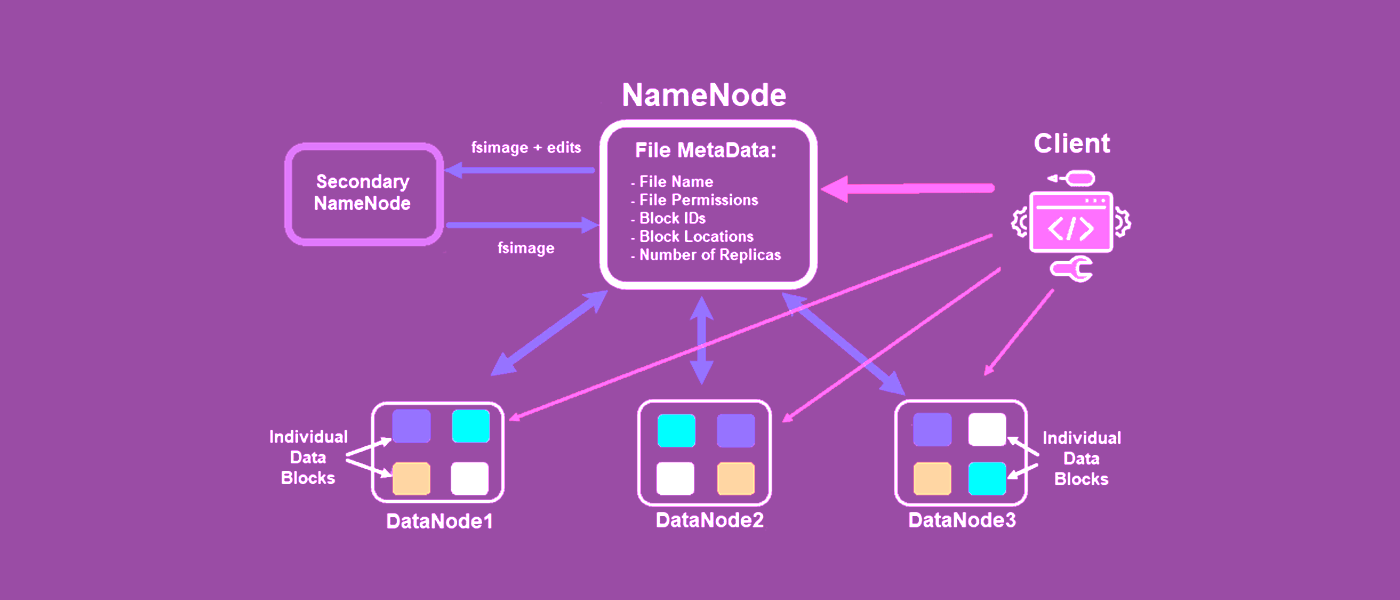
Данные/файлы в HDFS хранятся на Data Nodes, но не в чистом виде. Когда пользователь/программа загружают файл в Hadoop, то посылают файл на Name Node (все общение между кластером Hadoop и внешним миром происходит через Name Node). Он разбивает входящий файл на несколько блоков (по 128 Мб каждый) и рассылает на разные Data Nodes. Логика в том, чтобы блоки одного файла обязательно находились на разных Data Nodes и, следовательно, разных серверах Hadoop-кластера. После каждый блок файла копируется два раза и эти две копии изначального блока копируются на любые другие две Data Nodes. Разберемся, для чего.
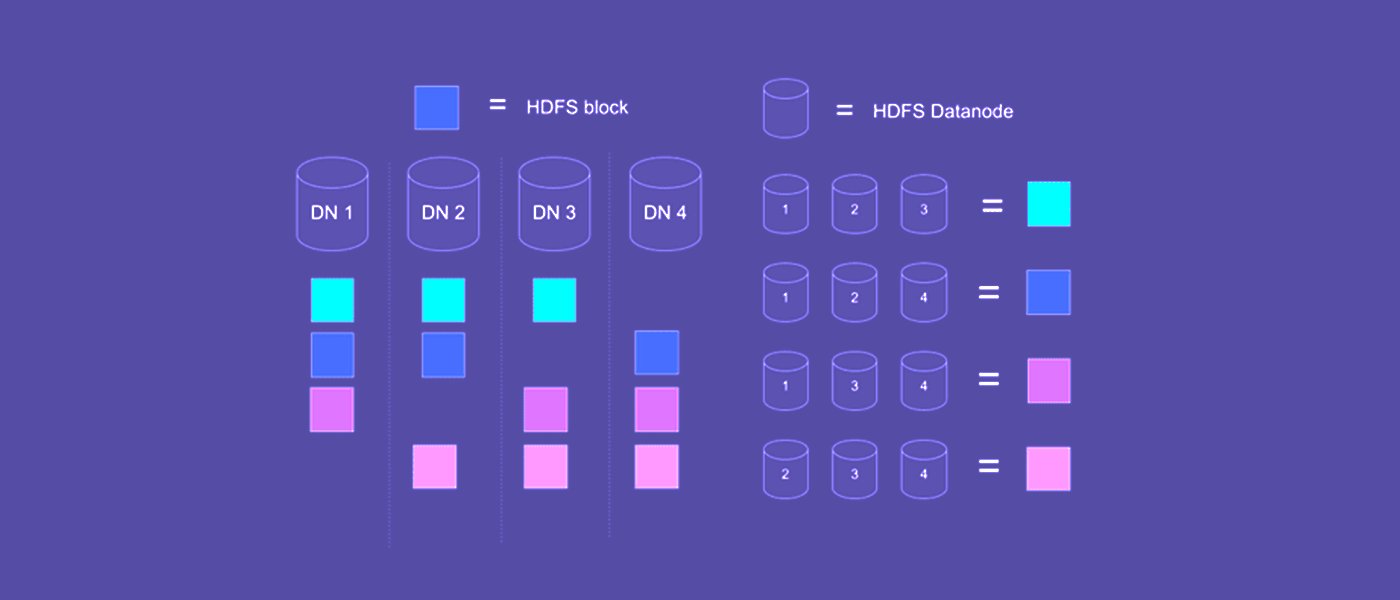
Как показано на рисунке, входящий файл разбили на 4 блока и каждый блок скопировали два раза. Если упадет одна или даже две (!) Data Nodes, файл все равно останется доступным. Падение единичных серверов в большом нагруженном кластере — обычное дело.
Другой важный плюс в том, что мы можем выгружать большой файл из HDFS не последовательно, а параллельно — скачивая разные блоки файла одновременно с нескольких серверов Hadoop-кластера. Это дает ускорение выгрузки, кратное количеству Data Node, на которых находятся блоки файла.
Такой подход позволяет практически безгранично горизонтально масштабироваться. Заканчивается место в Data Lake? Добавьте новый сервер в кластер и назначьте его Data Node.
MapReduce
Это движок (processing engine) для параллельной обработки больших датасетов. Разберем на примере, как он устроен.
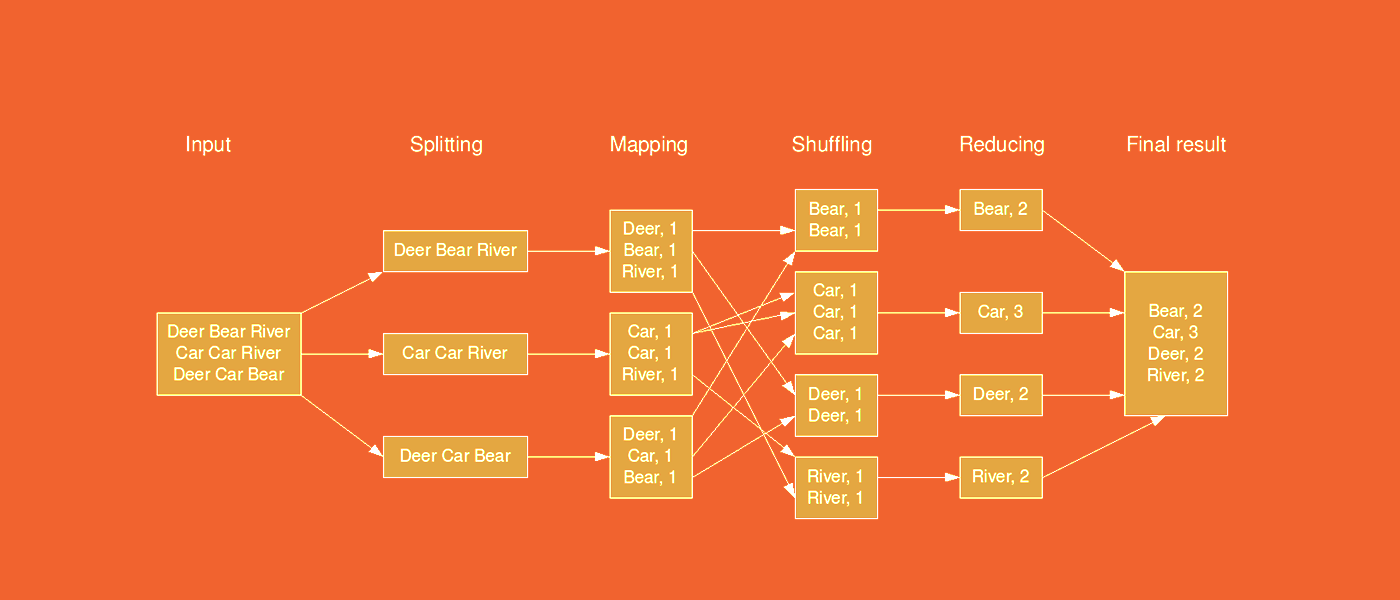
Процесс подсчета слов MapReduce
Входной файл — текст в формате .txt, который мы загрузили в Hadoop, и сейчас он, разбитый на блоки, лежит в HDFS. Наша задача — проанализировать файл, составив список уникальных слов и установив, сколько раз каждое из них встречается в этом тексте.
Сначала выполняется операция mapping. Hadoop MapReduce берет каждый блок и присваивает каждому слову значение 1. Получается список в формате «ключ — значение», где ключ — слово, и оно не уникально в рамках списка, а значение — единица.
После происходит shuffling: Data Node начинаются обмениваться парами «ключ — значение» так, чтобы в конце операции одинаковые ключи находились рядом. Сразу после этого начинается операция reducing: значения одинаковых ключей суммируются. На выходе получается файл со списком уникальных слов и их количеством в тексте.
Операции map и reduce выполняются отдельно для каждого блока на каждой Data Node.
// Функция, используемая рабочими нодами на Map-шаге
// для обработки пар ключ-значение из входного потока
void map (String name, String document):
// Входные данные:
// name - название документа
// document - содержимое документа
for each word w in document:
EmitIntermediate(w, "1");
// Функция, используемая рабочими нодами на Reduce-шаге
// для обработки пар ключ-значение, полученных на Map-шаге
void reduce(String word, Iterator partialCounts):
// Входные данные:
// word - слово
// partialCounts - список группированных промежуточных результатов. Количество записей в partialCounts —
и есть
// требуемое значение
int result = 0;
for each v in partialCounts:
result += parseInt(v);
Emit(AsString(result));
Java-код для WordCount-программы
Так происходит распределенная обработка данных в Hadoop. Не хватает мощности, джобы отрабатывают медленно, а код и так максимально оптимизирован? Добавляем новый сервер в Hadoop-кластер и назначаем его Data Node — так мы сможем выполнять больше операций Map или Reduce параллельно.
MapReduce — очень живучий подход для обработки данных. Если во время выполнения MapReduce упала треть кластера, то он, хоть и с задержками, успешно завершит джобу.
Главный недостаток Hadoop MapReduce — низкая эффективность. Многие технологии могут совершать те же операции, что и MapReduce, гораздо быстрее. Например, Apache Spark, Apache Impala, Apache Mahout.
Кроме того, MapReduce поддерживает не все виды операций над данными. На рисунке выше видно, что блоки с данными разделены и обрабатываются независимо друг от друга. С помощью MapReduce невозможно проанализировать взаимоотношения между элементами, он поддерживает только последовательные аналитические операции.
Тем не менее у MapReduce есть весомый плюс. Как правило, когда мы хотим обработать данные, то приносим их к вычислительным мощностям. Но с Hadoop MapReduce все наоборот: данные и так лежат в HDFS, который выступает Data Lake'ом. Первая операция Map выполняется на тех же Data Nodes, где лежат блоки с данными.
Apache Spark
Это BigData-фреймворк для распределенной обработки данных в оперативной памяти. Spark поддерживает обработку и структурированных данных (в виде таблиц), и полуструктурированных (json, yaml, xml и так далее), и неструктурированных (тексты и другие медиаформаты).
Spark — часть Hadoop Ecosystem, но может как взаимодействовать с Hadoop-кластером, брать и сохранять данные на HDFS и выполняться на тех же серверах кластера, что и Hadoop, так и работать независимо от Hadoop.
У Apache Spark есть API (не Web-API) для четырех языков программирования: Python, Java, Scala, R.
Поскольку Spark в основном написан на Scala, для достижения максимальной эффективности лучше использовать Scala и (в меньшей степени) — Java.
Но самый популярный язык для написания Spark Job — Python. Он предоставляет простое и понятное API для взаимодействия со Spark, которое повышает читаемость кода и упрощает его поддержку. Также Python добавляет множество опций для визуализации данных, использование которых невозможно в Scala или Java.
PySpark (интерфейс Spark для Python) при использовании основного модуля Spark SQL обычно дает такую же производительность, как и любой другой язык программирования. Apache Spark позволяет эффективно обрабатывать данные. Например, программа WordCount, о которой мы говорили выше, выполняется в нем в 100 раз быстрее, чем в Hadoop MapReduce. Это возможно благодаря распределенной архитектуре и in-memory расчетам.
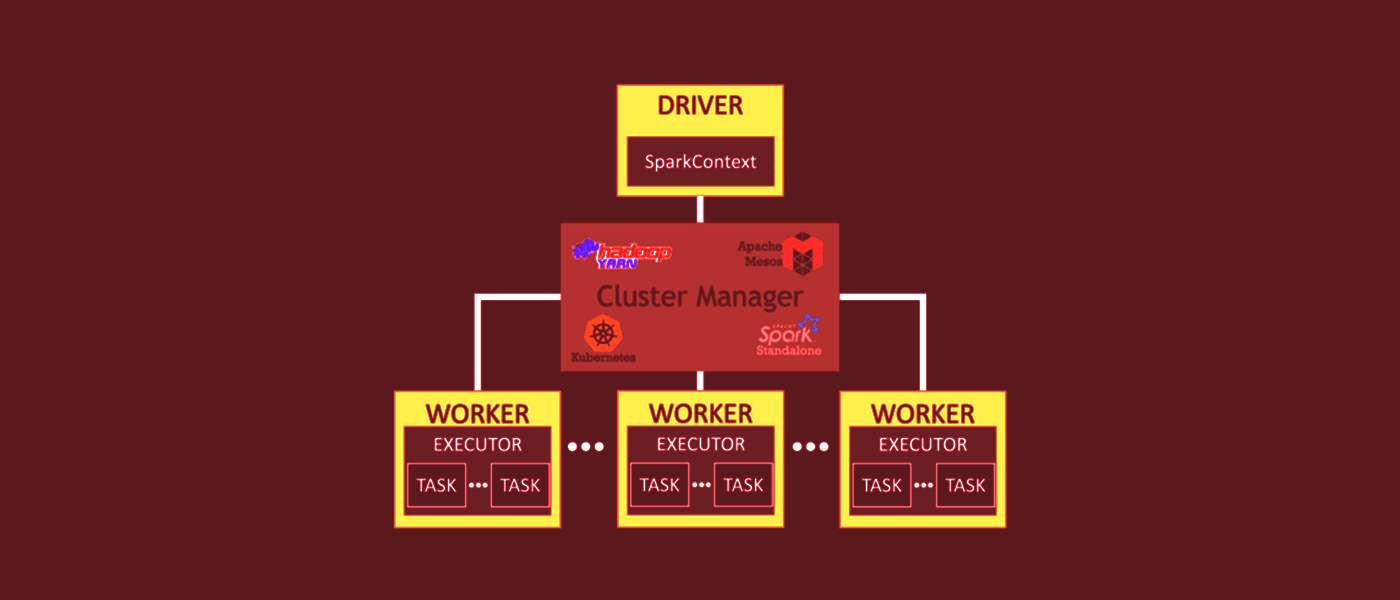
Все вычисления в Spark происходят в оперативной памяти.
Spark способен выполнять как пакетную, так и потоковую обработку данных.
Apache Spark состоит из четырех компонентов:
- MLlib — библиотека инструментов для ML-задач
- Streaming — инструменты для real-time аналитики
- SQL-модуль для работы со структурированными данными
- GraphX — библиотека для процессинга графовых структур данных


В Apache Spark данные могут быть представлены в виде RDD (Resilient Distributed Dataset), DataFrame и Dataset.
RDD — основная структура данных в Spark, DataFrames и Datasets — надстройки над RDD. Их рекомендуется использовать, если вы хорошо знаете свои данные и понимаете, как работают «внутренности» Spark. RDD позволяют совершать низкоуровневые трансформации над неструктурированными данными (как медиа или текст).
Dataframe внешне — аналог Python Pandas Dataframes, но с лучшей оптимизацией «под капотом». В отличие от RDD, данные в DataFrame организованы в колонки, как в реляционных СУБД. Dataframe помогает структурировать данные и предоставляет удобный API для обработки распределенно хранящихся данных.
Dataset — относительно новый вид представления данных в Apache Spark. Он объединяет преимущества RDD (строгая типизация и возможность применения низкоуровневых lambda-функций) с оптимизацией Spark SQL. Dataset не представлен в Python и R API, но некоторые его возможности доступны в Dataframe.
Spark SQL — модуль для работы со структурированными данными. Знать его обязательно. В отличие от RDD, он вводит новую концепцию — DataFrame, который дает больше понимания про структуру обрабатываемых данных и про операции, которые выполняются над данными. «Под капотом» Spark эту информацию используют для дополнительной оптимизации.
Есть два способа для взаимодействия со Spark SQL: SQL и DataFrame API. Какой бы способ вы ни выбрали, движок будет одинаковым.

Одна и та же логика, одинаковая производительность, но разный код.
В коде скрыта еще одна особенность Apache Spark — lazy evaluation. Когда Spark читает код и видит трансформации данных, он не начинает их выполнять, а заносит в DAG (направленный ацикличный граф), где последовательно хранит все операции, которые вы хотите совершить над данными. Когда вы вызываете «действие» — хотите посчитать количество строк в DataFrame, сохранить данные в файл или в базу данных, — Spark начинает анализировать DAG со всеми операциями, составляет оптимальный план трансформаций и начинает их.
Другой важный модуль — Spark Streaming. Он работает даже не с потоковыми данными, а с micro-batches, то есть берет маленькие кусочки данных из потока и обрабатывает их по очереди. Несмотря на это, Spark зарекомендовал себя как Production Grade IoT-решение.
Если вы уже используете DataFrame API, то концепция Structured Streaming позволит вам работать с потоковыми данными таким же образом, как со статичными.
Apache Airflow
Это opensource-инструмент для разработки, менеджмента и мониторинга дата-пайплайнов (ETL-процессов). Вся логика в нем описывается только кодом на Python. Главное преимущество этого — вы можете использовать Git для версионирования ETL-задач.
Основная концепция в Airflow — DAG, та же структура данных, что и Apache Spark. Но здесь DAG — отдельная ETL-задача, разбитая на шаги, которые следуют в строгой последовательности.
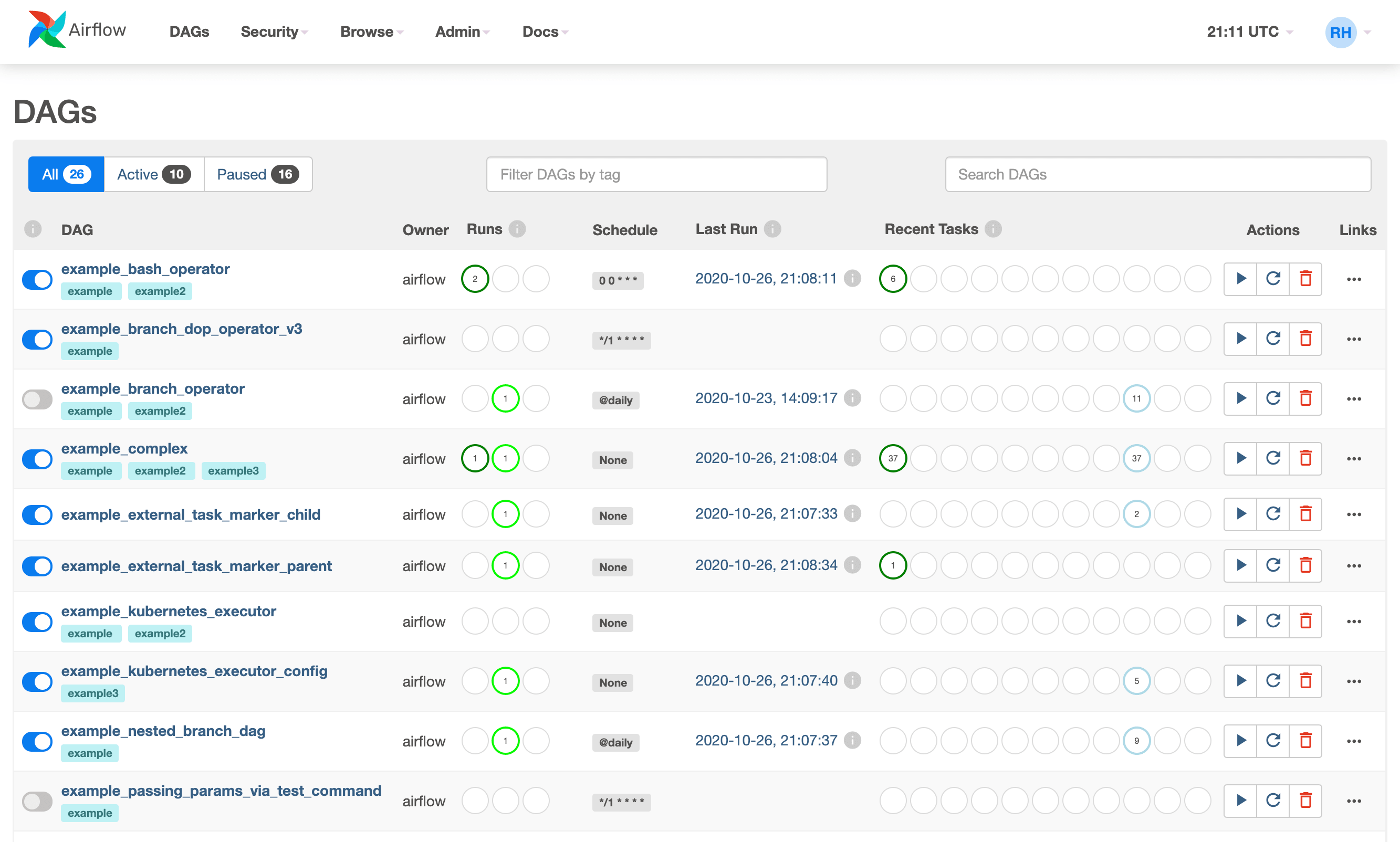
Интерфейс Airflow
На главном экране перечислены все DAG-и, дата последнего запуска, количество запусков, их результат и другая информация.
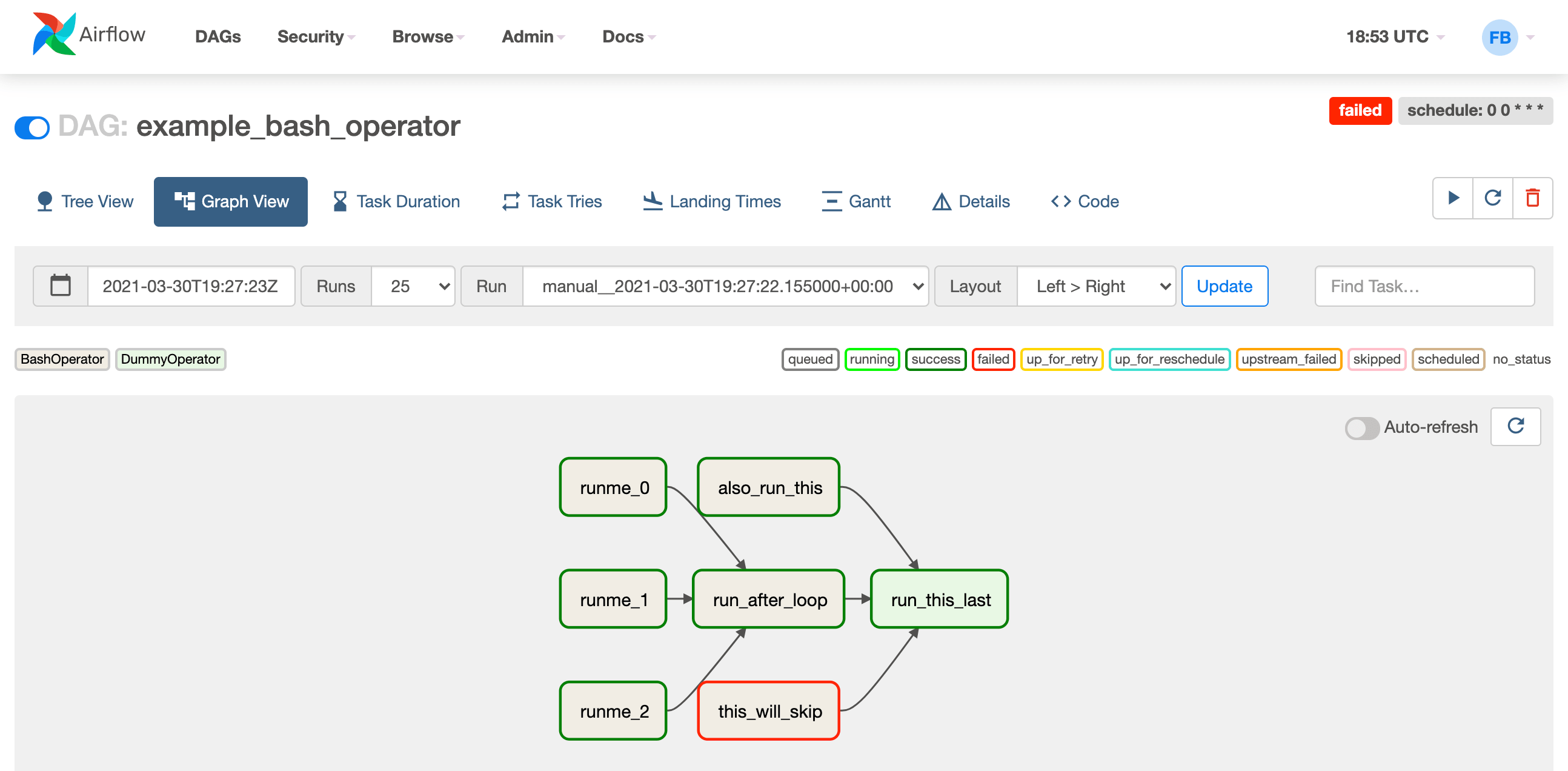
Интерфейс отдельно взятого DAG'а
Каждый шаг в DAG обозначен отдельным блоком. Каждому шагу вы можете назначить дополнительную логику — сказать, что делать, если шаг закончился с ошибкой, или задать последовательность выполнения в разных случаях. Также можно узнать дополнительную информацию каждого шага, включая подробные логи по выполнению, его время и детальное описание ошибок, если они были. Все это описывается обычным Python-кодом, причем он выглядит абсолютно pythonic.
У Airflow огромное количество коннекторов к внешним источникам данных: файлам, СУБД, API клауд-провайдерам (AWS S3, Azure Storage, GCP Storage), а также к внешним движкам для обработки данных (Apache Spark, Hadoop MapReduce). Если нужного оператора для работы с данными или коннекшена к движку нет, то функциональность Airflow легко расширяется самописными модулями. Airflow изначально проектировался так, чтобы вы могли изменять встроенный набор функций под свои задачи.
Apache Airflow навязывает вам принципы хорошей инженерии: наследование функциональности и переиспользование кода. Помимо этого, у него много дополнительных инструментов, включая встроенное хранилище паролей, переменных, NoSQL-базу данных для хранения метаданных.


