
Об’єднуй і володарюй: алгоритми кластеризації
Розповідаємо про основні
Кластеризація — це групування схожих об’єктів. Об’єкти називають точками даних, групи — кластерами.
Кластеризація допомагає в роботі з даними, про які нічого не відомо. Її використовують, наприклад, під час виявлення спаму, шахрайських повідомлень, недостовірних новин, а також для таргетування цільової аудиторії та персоналізації продуктів.
Пояснюємо, як працюють ключові алгоритми кластеризації.
Етапи кластеризації
#1. Підготовка даних. Зазвичай їх репрезентують у вигляді таблиці, де є об’єкти та їхні атрибути.
#2. Визначення міри близькості. Потрібно охарактеризувати схожість об’єктів. Якщо інформація не чисельна, то міра близькості має звести її до чисельної для порівняння.
#3. Вибір алгоритму. Іноді використовують одразу кілька для кращого результату.
#4. Підготовка результатів та їх інтерпретація.
Принципи кластеризації
#1. На основі центроїдів. Такі алгоритми поділяють точки даних залежно від відстані до центрів (центроїдів). Це найпопулярніший тип кластеризації. Основа будь-якого алгоритму на базі центроїдів — обчислення відстані між об’єктами набору даних.
Є десятки способів виміряти відстань. Евклідова відстань — найпростіший із них. Це відстань між об’єктами у звичайному сенсі (саме її ми вимірюємо лінійкою). Цей спосіб менш ефективний для роботи в багатовимірних просторах. Для них більше підходить мангеттенська метрика. Її назва пов’язана з плануванням кварталів Мангеттену. У найпростішому випадку довжину в метриці визначають як відстань між двома перехрестями, яку потрібно пройти, якщо рухатися тільки вздовж вулиць.
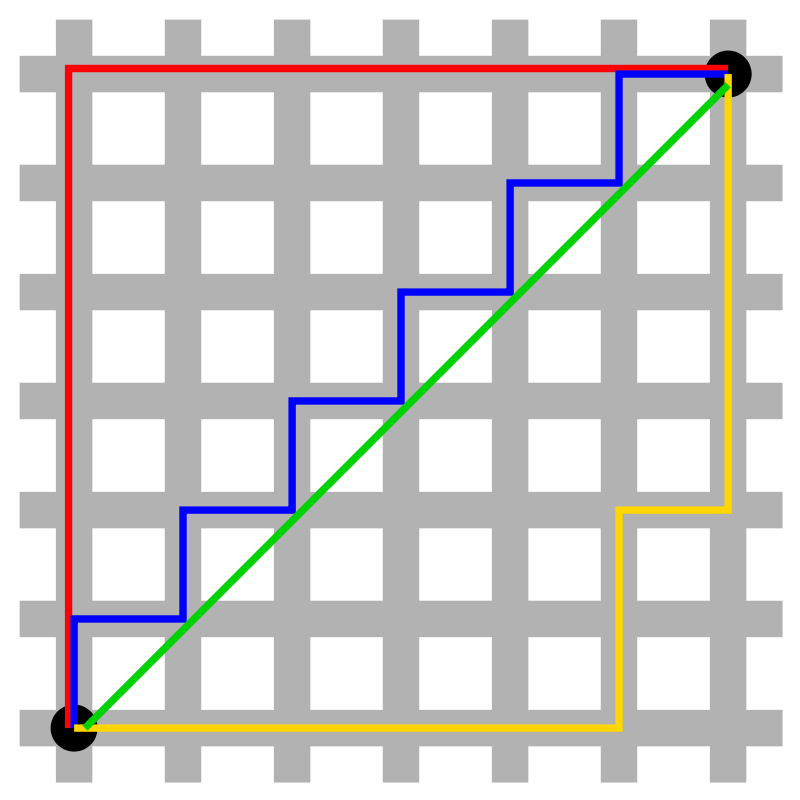
Wikipedia
Популярний алгоритм на основі центроїдів — метод K-means (K-середніх) Це простий алгоритм. Кластери формуються на основі відстані від точок до центрів. Перед використанням потрібно визначити їхню кількість. Алгоритм починає роботу з того, що розташовує центри кластерів випадковим чином. Після цього зсуває їх так, щоб мінімізувати сумарну відстань між точками та їхніми центрами. Модель виконує ітерацію по всіх точках даних, тому її застосовують для невеликих датасетів. Цей метод погано масштабується і чутливий до шуму. Через те, що початкові точки вибирають випадково, алгоритм може давати різні результати під час повторного аналізу. Для мінімізації розкиду даних аналіз проводять кілька разів, а результати усереднюють.
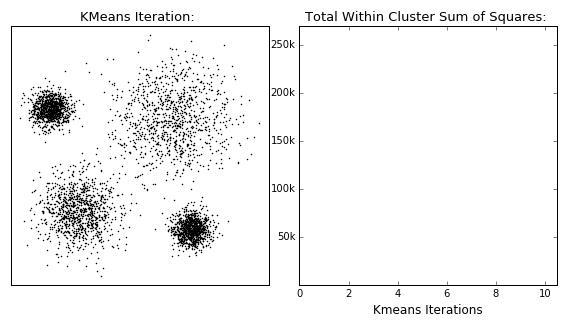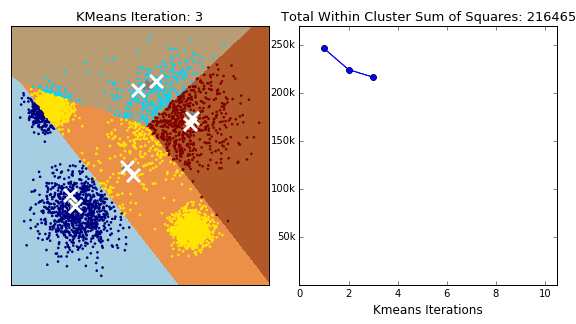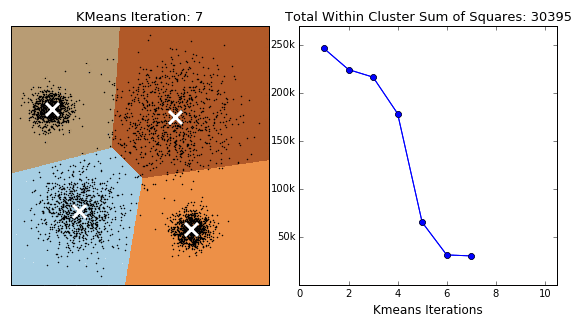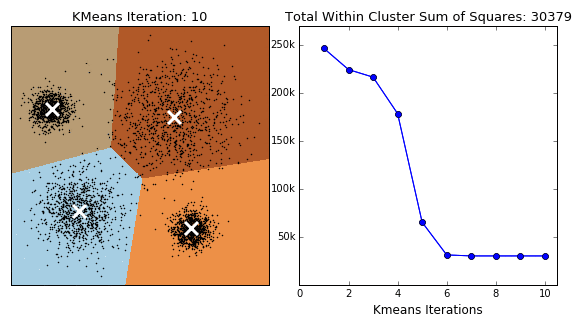
Є й інші алгоритми, побудовані на основі центроїдів: K-medioids, CLARANS, FUZZY C-means, generalized K-harmonic means.
#2. На основі розподілу. Така кластеризація створює і групує точки даних на основі їхньої ймовірної приналежності до одного й того самого розподілу (гауссового, біноміального та інших), яку потрібно встановити заздалегідь. Цей підхід схожий на кластеризацію за центроїдами, але точки відносять до кластерів не на основі відстані, а на основі максимальної правдоподібності. Самі кластери водночас визначаються не тільки положеннями їхніх центрів, а й параметрами розподілів.
Ключовий приклад — Gaussian Mixture Models Clustering (модель гаусової суміші). Функція Гаусса описує спосіб розподілу ймовірностей. Це гнучка модель, яка може визначити приналежність точок даних до кількох кластерів одночасно і працювати з кластерами будь-якої форми.
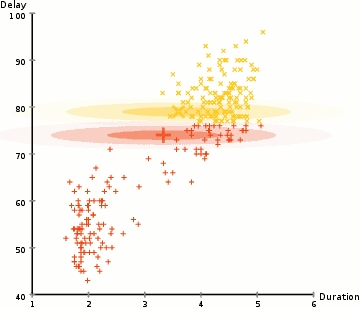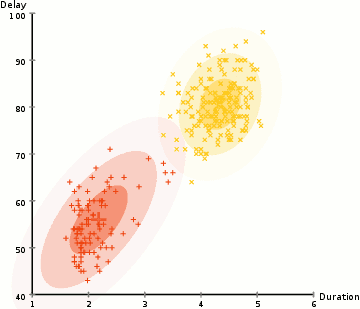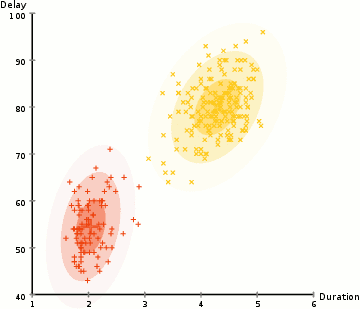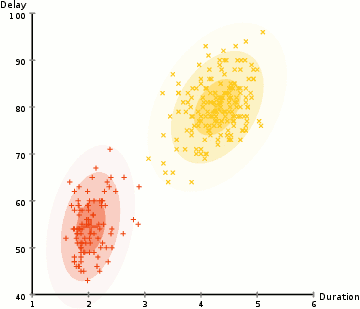
#3. На основі щільності. Такі алгоритми знаходять місця, в яких багато точок даних, і об’єднують їх. Кластери можуть мати будь-яку форму. Заразом точки даних, що розташовані відокремлено, не потрапляють ні до якого кластера.
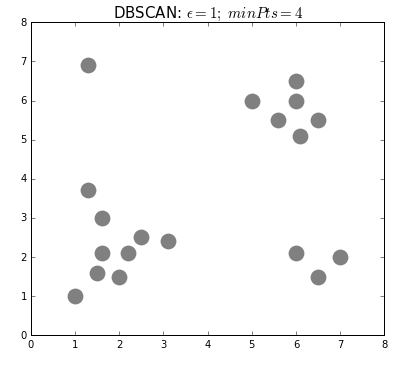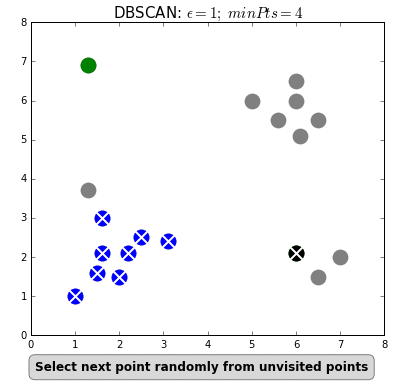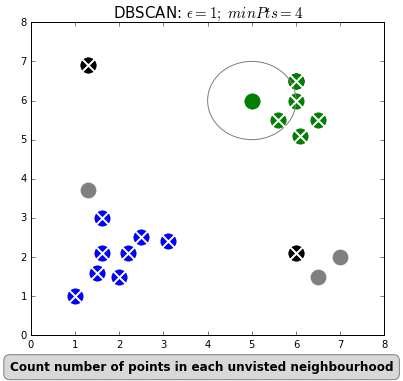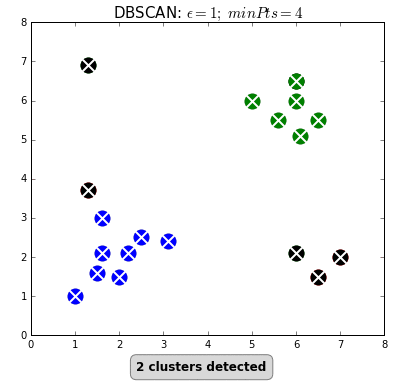
Найпопулярніший і найпростіший алгоритм цього класу — DBSCAN (Density-Based Spatial Clustering Of Applications With Noise — просторова кластеризація застосунків із шумом).
Алгоритм вважає, що дві точки пов’язані, якщо вони лежать у межах околиці одна одної. DBSCAN враховує дві умови під час формування кластерів: minPts (мінімальна кількість точок у кластері) та eps (максимальна відстань точки до інших точок даних). Вибір правильних початкових параметрів має вирішальне значення для його роботи.
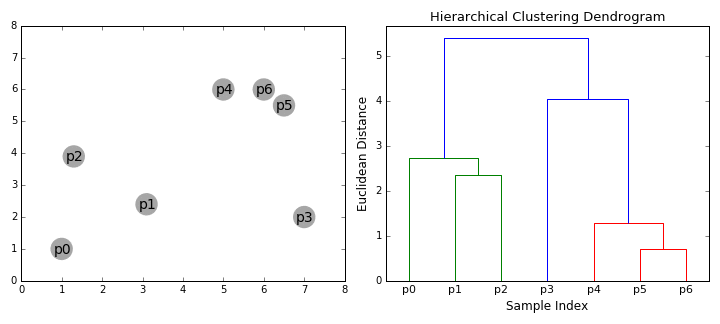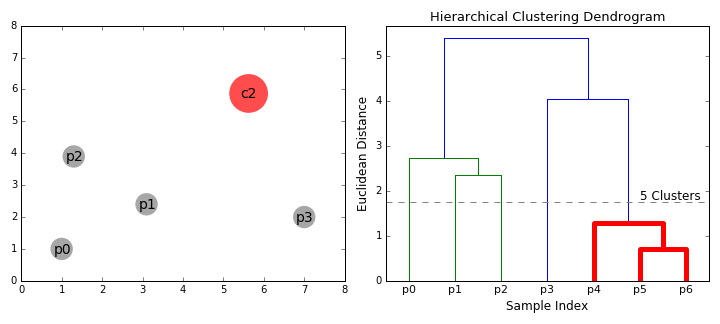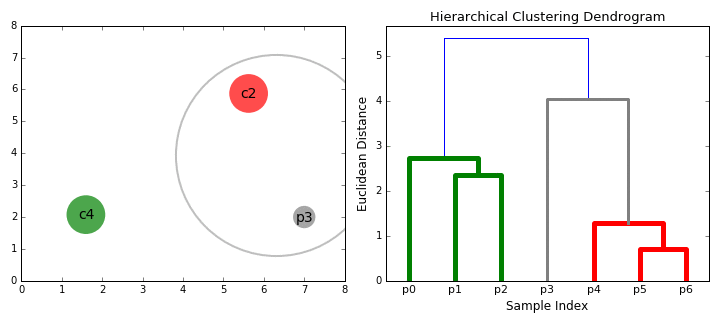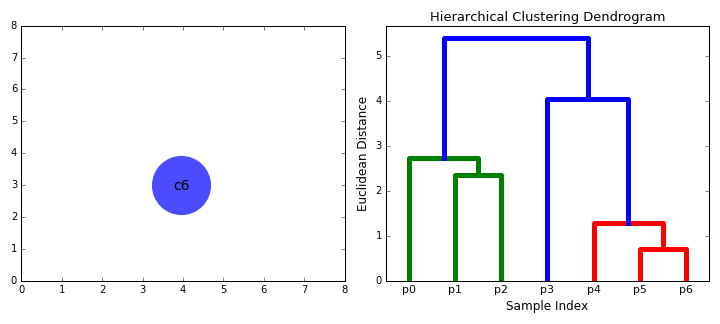
#4. Ієрархічна кластеризація. Такі моделі будують дерева кластерів (дендрограми), у яких маленькі кластери включені у великі. За схожим принципом упорядковано документи в комп’ютері: жорсткі диски містять папки, у папках розташовані файли. Перевага цього методу в тому, що кількість кластерів не потрібно визначати заздалегідь. Але він вимагає багато ресурсів на обчислення і не підходить для великих наборів даних. Також чутливий до шуму і викидів.
Алгоритми ієрархічної кластеризації поділяють на 2 категорії: висхідні (об’єднувальні) та низхідні (ті, що розділяють). Висхідні алгоритми послідовно агломерують пари кластерів, доки всі кластери не об’єднаються в один, що містить усі точки даних. Низхідні алгоритми послідовно поділяють кореневий кластер на субкластери.
Agglomerative Hierarchical Clustering (агломеративно-ієрархічна кластеризація) належить до висхідних алгоритмів і об’єднує невеликі кластери в один кореневий. На першому етапі кожен об’єкт є окремим кластером. Вони об’єднуються послідовно за допомогою матриці подібності. Агломеративна модель найкраще підходить для пошуку невеликих кластерів.
Алгоритм OPTICS (Ordering Points To Identify the Clustering Structure — точки впорядкування для визначення структури кластеризації) поєднує ієрархічну та кластеризацію за щільністю. Це модифікована версія DBSCAN, яка може знаходити кластери з різною щільністю. Мінус — велика кількість обчислень.


