
Объединяй и властвуй: алгоритмы кластеризации
Рассказываем об основных.
Кластеризация — это группирование похожих объектов. Объекты называются точками данных, группы — кластерами.
Кластеризация помогает в работе с данными, о которых ничего не известно. Ее используют, например, при обнаружении спама, мошеннических сообщений, недостоверных новостей, а также для таргетирования целевой аудитории и персонализации продуктов.
Объясняем, как работают ключевые алгоритмы кластеризации.
Этапы кластеризации
#1. Подготовка данных. Обычно их репрезентуют в виде таблицы, где есть объекты и их атрибуты.
#2. Определение меры близости. Необходимо охарактеризовать сходство объектов. Если информация не численная, то мера близости должна свести ее к численной для сравнения.
#3. Выбор алгоритма. Иногда используют сразу несколько для лучшего результата.
#4. Подготовка результатов и их интерпретация.
Принципы кластеризации
#1. На основе центроидов. Такие алгоритмы разделяют точки данных в зависимости от расстояния до центров (центроидов). Это самый популярный тип кластеризации. Основа любого алгоритма на базе центроидов — вычисления расстояния между объектами набора данных.
Есть десятки способов измерить расстояние. Евклидово расстояние — самый простой из них. Это расстояние между объектами в обычном смысле (именно его мы измеряем линейкой). Этот способ менее эффективен для работы в многомерных пространствах. Для них больше подходит манхэттенская метрика. Ее название отсылает к планировке кварталов Манхэттена. В самом простом случае длина в метрике определяется как расстояние между двумя перекрестками, которое нужно пройти, если двигаться только вдоль улиц.
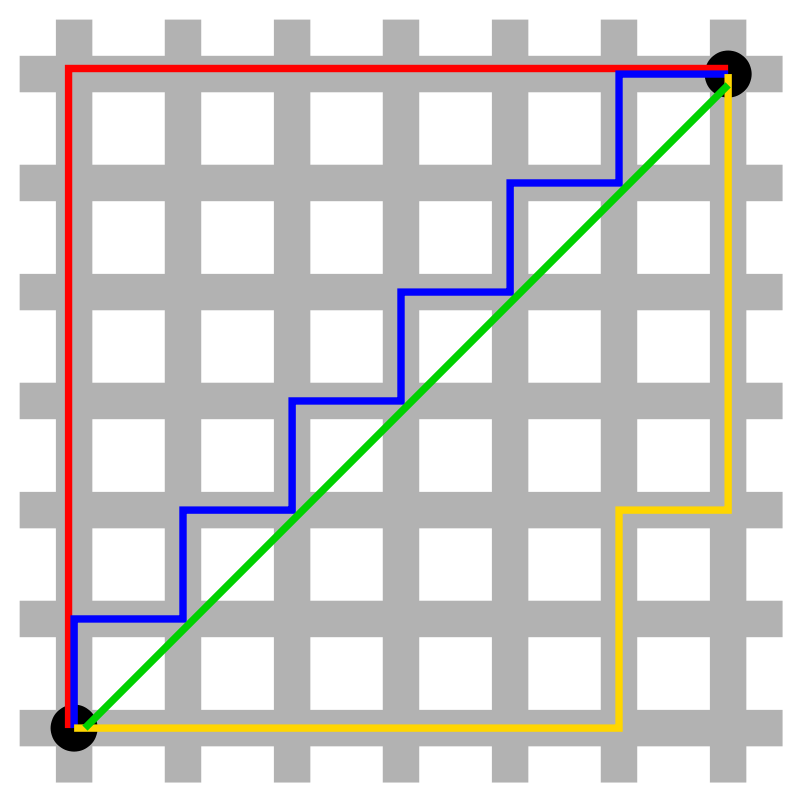
Wikipedia
Популярный алгоритм на основе центроидов — метод K-means (K-средних) Это простой алгоритм. Кластеры формируются на основе расстояния от точек до центров. Перед использованием нужно определить их количество. Алгоритм начинает работу с того, что располагает центры кластеров случайным образом. После этого сдвигает их так, чтобы минимизировать суммарное расстояние между точками и их центрами. Модель выполняет итерацию по всем точкам данных, поэтому применяется для небольших датасетов. Этот метод плохо масштабируется и чувствителен к шуму. Из-за того, что начальные точки выбираются случайно, алгоритм может давать разные результаты при повторном анализе. Для минимизации разброса данных анализ проводят несколько раз, а результаты усредняют.
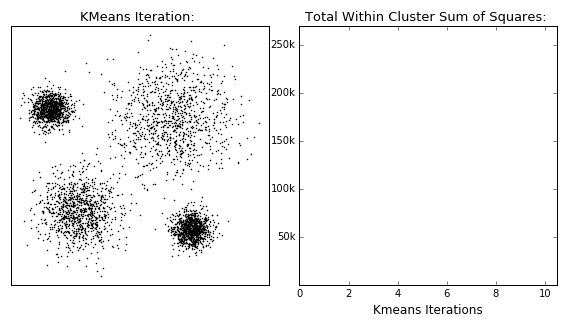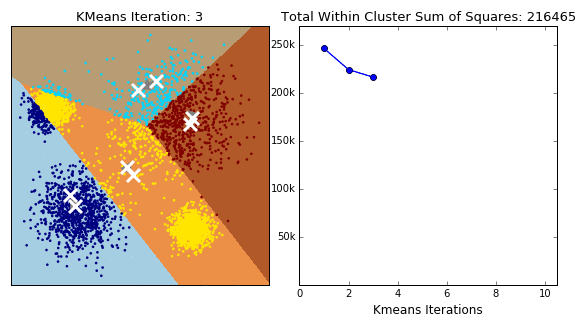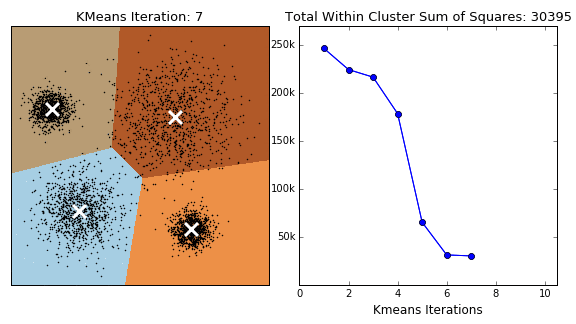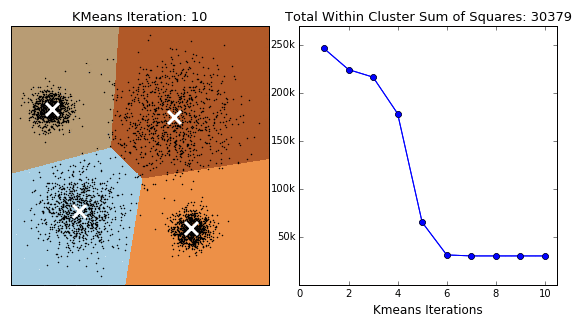
Есть и другие алгоритмы, построенные на основе центроидов: K-medioids, CLARANS, FUZZY C-means, generalized K-harmonic means.
#2. На основе распределения. Такая кластеризация создает и группирует точки данных на основе их вероятной принадлежности к одному и тому же распределению (гауссовому, биномиальному и другим), которую нужно установить заранее. Этот подход похож на кластеризацию по центроидам, но точки относят к кластерам не на основе расстояния, а на основе максимальной правдоподобности. Сами кластеры при этом определяются не только положениями их центров, но и параметрами распределений.
Ключевой пример — Gaussian Mixture Models Clustering (модель гауссовой смеси). Функция Гаусса описывает способ распределения вероятностей. Это гибкая модель, которая может определить принадлежность точек данных к нескольким кластерам одновременно и работать с кластерами любой формы.
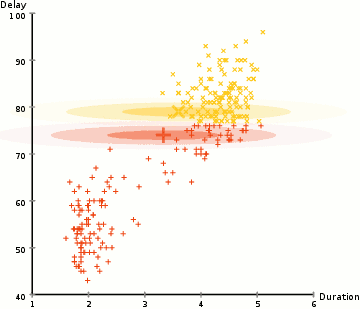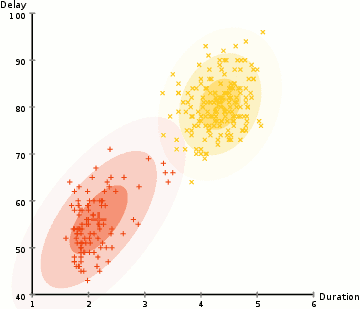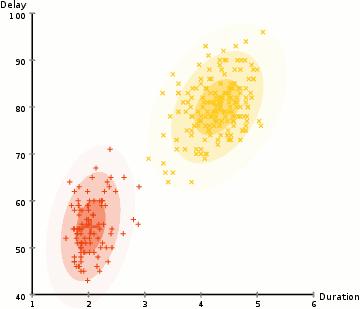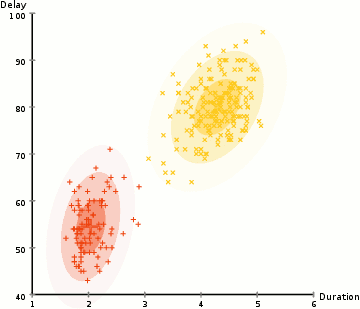
#3. На основе плотности. Такие алгоритмы находят места, в которых много точек данных, и объединяют их. Кластеры могут иметь любую форму. При этом точки данных, находящиеся обособленно, не попадают ни в какой кластер.
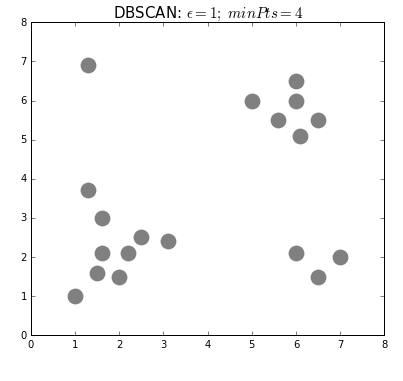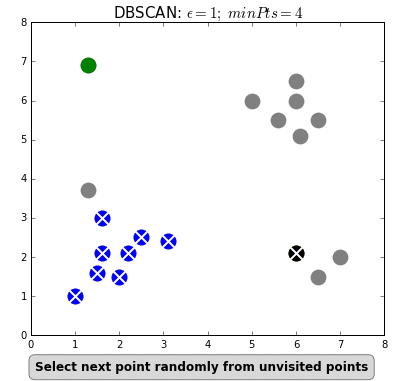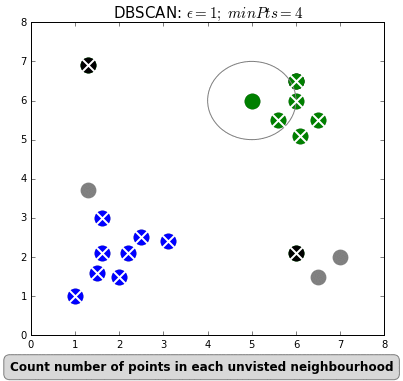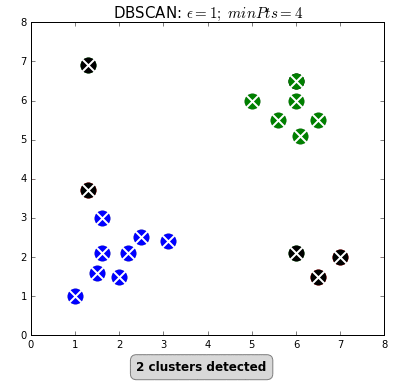
Самый популярный и простой алгоритм этого класса — DBSCAN (Density-Based Spatial Clustering Of Applications With Noise — пространственная кластеризация приложений с шумом).
Алгоритм считает, что две точки связаны, если они лежат в пределах окрестности друг друга. DBSCAN учитывает два условия при формировании кластеров: minPts (минимальное количество точек в кластере) и eps (максимальное расстояние точки до других точек данных). Выбор правильных начальных параметров имеет решающее значение для его работы.
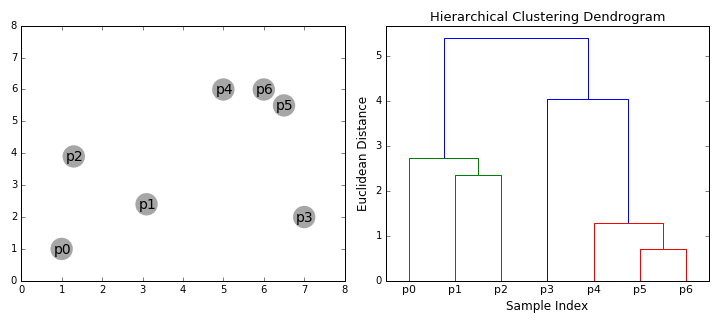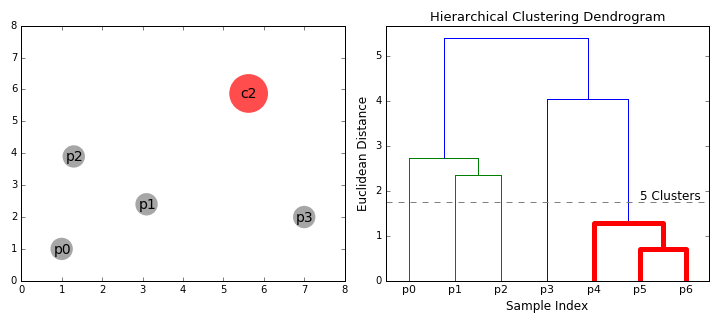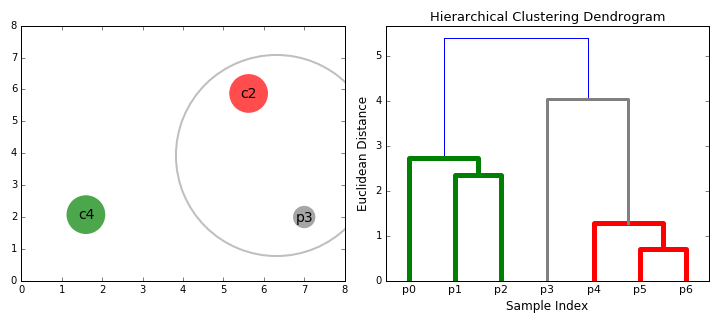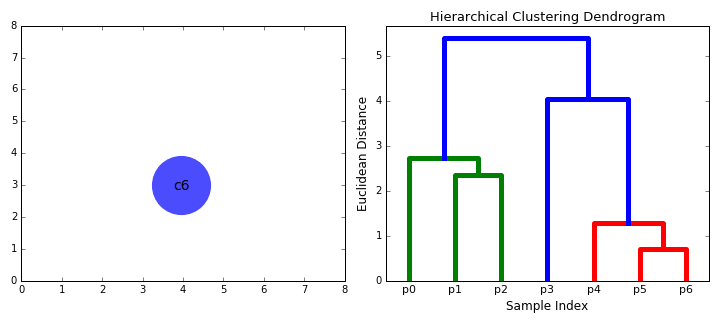
#4. Иерархическая кластеризация. Такие модели строят деревья кластеров (дендрограммы), в которых маленькие кластеры включены в большие. По похожему принципу упорядочены документы в компьютере: жесткие диски содержат папки, в папках расположены файлы. Достоинство этого метода в том, что количество кластеров не нужно определять заранее. Но он требует много ресурсов на вычисления и не подходит для больших наборов данных. Также чувствителен к шуму и выбросам.
Алгоритмы иерархической кластеризации делятся на 2 категории: восходящие (объединяющие) и нисходящие (разделяющие). Восходящие алгоритмы последовательно агломерируют пары кластеров, пока все кластеры не будут объединены в один, содержащий все точки данных. Нисходящие алгоритмы последовательно разделяют корневой кластер на субкластеры.
Agglomerative Hierarchical Clustering (агломеративно-иерархическая кластеризация) относится к восходящим алгоритмам.Она объединяет небольшие кластеры в один корневой. На первом этапе каждый объект представляет собой отдельный кластер. Они объединяются последовательно при помощи матрицы сходства. Агломеративная модель лучше всего подходит для поиска небольших кластеров.
Алгоритм OPTICS (Ordering Points To Identify the Clustering Structure — точки упорядочивания для определения структуры кластеризации) сочетает иерархическую и кластеризацию по плотности. Это модифицированная версия DBSCAN, которая может определять кластеры с разной плотностью. Минус — большое количество вычислений.


