
Что такое data warehouse и как его построить
Рассказывает Senior Product Analyst в Jooble.
Компании получают данные из множества источников. Рекламная информация поступает из Google AdWords, сессии пользователей — из Google Analytics, данные продукта — из MySQL, MS Server или MongoDB. Информация о платежах — из 1C. Кроме этого, есть тикет-системы, чаты, CRMs и даже Excel-файлы.
Вручную обрабатывать и соединять эту информацию — нецелесообразно и дорого. Поэтому многие компании используют data warehouse (хранилище данных).
Оксана Носенко, лектор курса «SQL для аналитики» в robot_dreams, Senior Product Analyst в Jooble, объясняет, чем data warehouse отличается от базы данных и как создать собственное хранилище.

Хранение данных в «облаке»
Data warehouse — это система, которая хранит данные из разных источников для аналитики и составления отчетов.
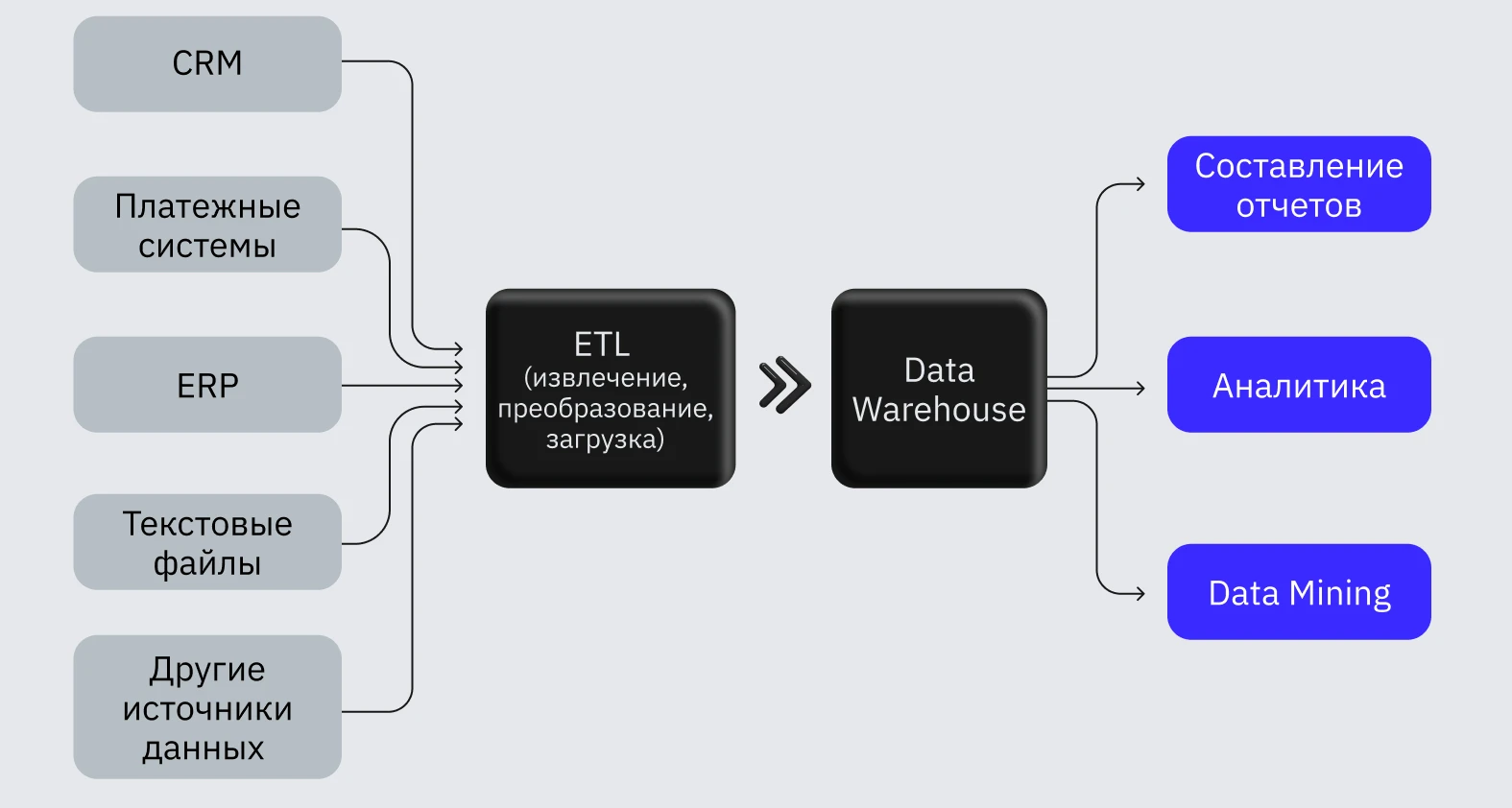
Схема хранилища данных
Хранилища отличаются от баз данных по ряду признаков:
- данные в warehouse не обязательно должны поступать в реальном времени (если иное не предусмотрено бизнес-задачей);
- данные могут иметь разную структуру (в зависимости от источников);
- хранилище не обязательно должно работать быстро. Главное, чтобы скорости хватало для решения всех аналитических задач.
Data warehouse подходит для сложных и комплексных вычислений лучше, чем база данных. Во время выполнения сложного запроса база данных может быть перегружена. Из-за этого вы рискуете потерять новую информацию — для ее обработки не хватит ресурсов.
Как создать data warehouse
Для хранения данных чаще всего используют cloud-решения. Их плюсы:
- поддержка и масштабируемость: не надо выделять комнату для серверов и подключать новые в случае роста нагрузки. Обычно облачное хранилище масштабируется автоматически;
- производительность: облачные решения работают быстрее традиционных и автоматически перераспределяют нагрузку;
- доступ к данным: чтобы попасть в облачное хранилище, не нужно устанавливать сервер на компьютер. Достаточно открыть браузер и войти в облако. SQL-запрос можно делать даже со смартфона.
Основные cloud warehouses — Amazon Redshift, Google BigQuery, Azure.
У них разная стоимость, производительность, экосистема, поддержка.
В продуктовых IT-компаниях, где я работала, мы выбирали Google Big Query по этим причинам:
- хранилище в GBQ запустить можно быстро и без помощи администраторов баз данных. Нужно только создать аккаунт в Google Cloud;
- формат pay-as-you-go: оплата по мере потребления только за те услуги, которые используем. Не нужно заранее выбирать самый оптимальный пакет;
- готовые pipeline-решения. Многие платформы предоставляют услуги трансфера данных в GBQ. Поэтому warehouse запускали только аналитики, без разработчиков и админов.
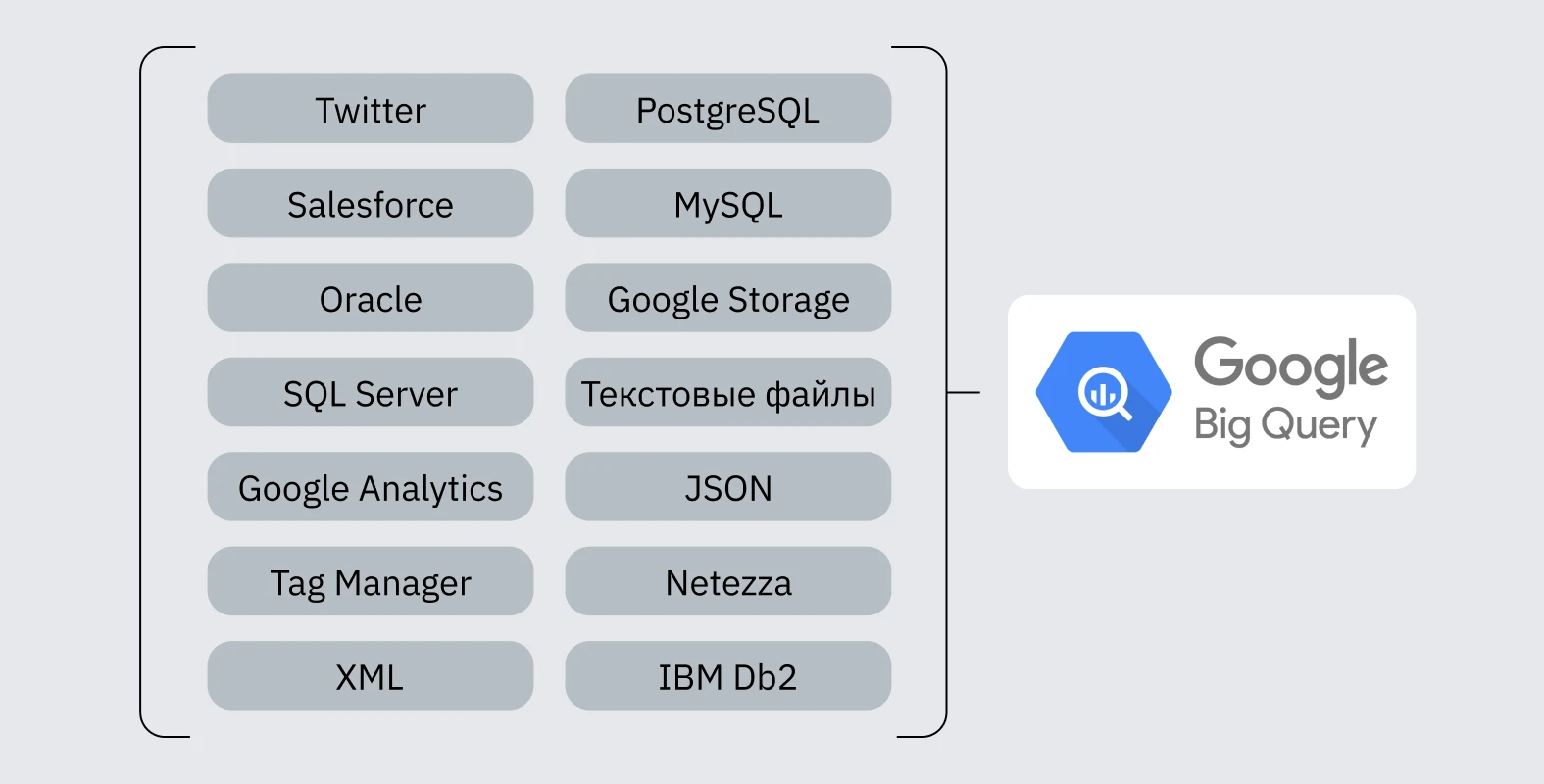
Пример GBQ Data Warehouse
Основной минус Big Query — плата за запросы. Каждый SQL-запрос использует определенный объем памяти, за который нужно платить в конце месяца. Поэтому советую поставить ограничение на количество запросов в день.
Создавая хранилище данных, нужно учитывать все сложности. Основная проблема — конструирование пайплайнов. Нужно настроить трансфер данных из всех источников в единое хранилище. Во время него придется столкнуться с несовершенными API, ограничениями по выгрузке или парсингом данных. Можно писать все соединения самостоятельно или использовать готовые решения (например, Owox, Alooma, Blendo). Тем, кто работает с большим объемом информации, лучше написать свои скрипты, которые будут синхронизировать данные каждый день.
Маленькому бизнесу без администратора баз данных стоит использовать pipeline-платформу. Ее стоимость зависит от объема информации и количества соединений.
Вторая сложность — качество данных. Трансфер данных может не выдавать ошибку. Но при этом информация может быть неполной (из-за ограничений в API). Также есть риск ошибки во время дальнейшего парсинга переменных (например, возникнут проблемы с кодировкой данных из 1С).
Следующий шаг после создания хранилища — выбор инструментов для разработки frontend-части. Бизнесу нужно видеть графики, срезы, сравнения и динамику.


Мой фаворит — Tableau. В нем можно выполнить любую задачу. Главное — понять, что именно вам нужно.
Здесь также можно выбрать Tableau Online, и поддержкой/обслуживанием серверов будут заниматься Tableau-специалисты. Недостаток решения — цена. Лицензии достаточно дорогие. Если вы пока не готовы тратиться на BI-систему, но хотите визуализировать данные с GBQ, альтернативой может стать Google Data Studio. Небольшой компании на старте будет достаточно возможностей GDS.
Развитие data-аналитики в компании быстро дает заметный результат. Обладая всеми нужными данными, проще оптимизировать рекламные кампании, проводить A/B-тесты, работать с продуктовыми гипотезами.


