
Як вимірювати ефективність команди: 9 ключових метрик
Для engineering-менеджерів
Позиція engineering manager — це не про мікроменеджмент і не про те, щоб рахувати кількість закритих задач. Це про здатність бачити повну картину за допомогою купи інсайдерських метрик, які розкривають роботу команди з різних сторін.
В цій статті розповімо про важливий аспект курсу з інженерного менеджменту, а саме про мастхев-метрики. Ці показники — спосіб говорити з бізнесом однією мовою, виявляти проблеми до того, як вони переростуть у кризи, і будувати передбачувану, ефективну інженерну культуру.
Продуктивність команди: як зрозуміти, скільки та як швидко ви будуєте продукт
Перший сигнал того, що команда працює ефективно, — це її здатність стабільно та передбачувано доставляти результат. Для цього не потрібно складних формул або систем, а достатньо кількох базових метрик. Вони покажуть, чи зростає продуктивність, де є ботлнеки та як змінюється динаміка з часом. До них, наприклад, входять:
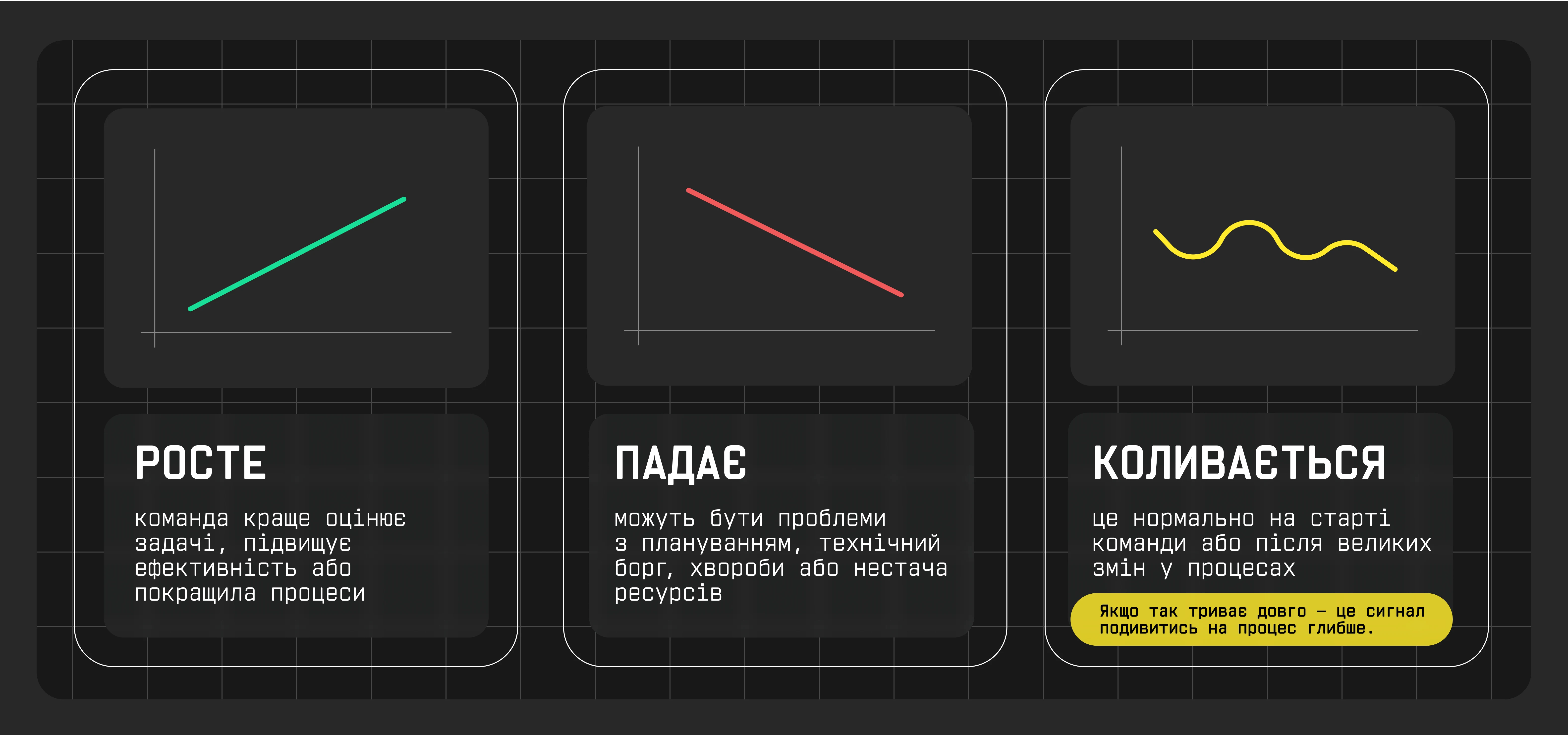
- Velocity — швидкість виконання
Відображає кількість story points, які команда завершує за один спринт. Ця метрика потрібна для розуміння того, наскільки стабільно команда встигає виконувати запланований обсяг роботи. Інтерпретувати velocity доволі легко. Якщо ця метрика:
- Lead time — шлях від ідеї до користувача
Метрика показує середній час, що минає від моменту створення задачі (наприклад, у беклозі) до її релізу в продакшн. Вона демонструє, наскільки швидко команда здатна втілювати бізнес-ідеї в робочі рішення.
Наприклад, якщо нова фіча доходить від беклогу до користувача за 30 днів, а раніше це займало 50, — процес став ефективнішим. Якщо ж час зростає — можливо, з’явилося вузьке місце: наприклад, тестування займає забагато часу. - Cycle Time — час життя задачі в роботі
Відображає те, скільки часу проходить від моменту, коли інженер починає працювати над задачею, до її деплою. Це метрика «операційної» ефективності — вона показує, наскільки гладко та швидко рухається робота в процесі.
Якщо задачі типово займають 3–4 дні, але окремі тягнуться 10+, це привід дослідити причину: чи була задача занадто великою, чи застрягла на рев’ю, чи бракує ресурсів. - Throughput — скільки задач завершується
Визначає кількість задач, які команда завершує за певний період (наприклад, за спринт або місяць). Ця метрика показує реальний вихід роботи, незалежно від складності задач.
Наприклад, команда стабільно закриває 25 задач за спринт. Якщо кількість впала до 15, це свідчить про падіння throughput. Далі варто розбиратися з причинами: чи задачі стали складнішими, чи зменшився склад команди, чи з’явилися блокери.
Як читати ці метрики разом
Окремо кожна метрика важлива, але разом вони показують повну історію:
- Якщо velocity стабільна, але cycle time росте — задачі можуть бути переоцінені або застрягати в процесі.
- Якщо lead time довгий, але cycle time короткий — проблеми, швидше за все, в беклозі або пріоритизації, а не в самій розробці.
- Якщо throughput стабільний, але velocity падає — команда бере менші задачі або інакше оцінює складність.


Якість: як не «вистрілити собі в ногу» швидкістю
Швидкість — це добре лише тоді, коли продукт працює. Якщо команда викочує фічі швидко, але половину часу витрачає на виправлення помилок, бізнес нічого не виграє. Метрики якості допомагають побачити, чи не «з’їдає» брак стабільності всю вашу продуктивність.
- Bug Rate/Defect Density — скільки помилок ви робите
Ця метрика відображає кількість знайдених багів на реліз або на певну кількість рядків коду (наприклад, на 1000 LOC). Іншими словами, вона відображає загальну «чистоту» продукту й стабільність процесу розробки. Якщо цей показник:

- Escaped Defects — баги, які дійшли до користувача
Escaped Defects показує кількість дефектів, які не знайшли під час тестування й вони потрапили в продакшн. Тобто ця метрика показує реальний вплив проблем на користувачів та бізнес. - Change Failure Rate — наскільки «безпечні» ваші деплої
Це частка релізів, які завершились невдачею, відкатом (rollback) або терміновим патчем. Це один із ключових індикаторів зрілості процесу доставки. Він показує, чи готовий ваш код до продакшену й наскільки стабільні релізи. Так, якщо зі 100 деплоїв 5 закінчились фейлом — це хороший показник (~5%). Якщо 20+ — потрібно оптимізувати тестування, CI/CD або процес релізів.
Практика: не женіться за 0% багів
Важливо розуміти, що мета — не ідеальна якість, а збалансована. Абсолютна відсутність багів означає, що ви, скоріше за все:
- Занадто довго тестуєте і сповільнюєте релізи
- Витрачаєте ресурси не на ті речі, які створюють бізнес-цінність
- Боїтеся випускати нове, щоб «нічого не зламати»
Краще орієнтуватися на «достатньо хорошу якість», де критичних багів у продакшені мінімум, загальна кількість дефектів під контролем, а деплої стабільні та передбачувані.


Надійність процесів: чи можна довірити команді стабільні релізи
Один із головних маркерів зрілої технічної команди — те, наскільки передбачувано та безболісно вона доставляє зміни в продакшн. Навіть найкращий код нічого не вартий, якщо його важко викотити, він часто «падає» або виправлення займає дні. Саме тому важливо вимірювати не лише продуктивність і якість, але й стабільність процесу доставки.
- Deployment Frequency — як часто ви доставляєте зміни
Показує кількість деплоїв у продакшн за певний період (наприклад, день, тиждень або місяць). Ця метрика вимірює те, наскільки швидко та регулярно команда може приносити користувачам нову цінність. Звісно, все залежить від типу компанії, але:
▪ Часті релізи — ознака автоматизованих процесів, впевненості в якості й зрілості DevOps-культури.
▪ Рідкісні релізи — можуть означати страх поламати продакшн, проблеми з CI/CD або складні ручні процеси. - Mean Time to Recovery (MTTR) — швидкість відновлення після збоїв
MTTR визначає середній час, який проходить від виявлення проблеми до повного відновлення роботи системи. Ця метрика напряму впливає на довіру бізнесу та користувачів.
Так, якщо після збою сервіс повертається до нормальної роботи за 30 хвилин, це чудовий показник, а 6 годин або більше — це прямий ризик втратити гроші та користувачів. - Lead Time for Changes — як швидко зміни доходять до користувачів
Lead Time for Changes вираховує середній час від моменту, коли зміна з’явилася в репозиторії (коміт), до моменту, коли вона потрапила в продакшн. Іншими словами, це метрика «операційної швидкості» команди. Вона показує, наскільки гладко йде шлях від написаного коду до користувача. Інтерпретувати її легко:
▪ Короткий час — результат автоматизованих пайплайнів, ефективних рев’ю і тестування.
▪ Довгий час — можливі вузькі місця: очікування релізного вікна, ручні перевірки або недостатня автоматизація.


Командне здоров’я: метрики, про які часто забувають
Продуктивність, якість і стабільність не мають сенсу, якщо за ними стоїть демотивована команда, хронічне вигорання або приховане незадоволення. Метрики здоров’я допомагають помітити проблеми до того, як вони зруйнують усе інше.
- Work in Progress (WIP) — чи не робите ви забагато одночасно
WIP відстежує кількість задач, які команда виконує паралельно наразі.
Ця метрика допомагає розуміти, наскільки команда сфокусована. Чим більше задач одночасно, тим повільніше просувається кожна з них і тим вищі ризики помилок. - Team Satisfaction/eNPS — як команда себе почуває
Ця метрика включає регулярні короткі опитування про задоволеність роботою, командою, процесами та менеджментом. eNPS (Employee Net Promoter Score) — це питання «Чи порадили б ви це місце роботи другу?» з оцінкою від 0 до 10.
Вона дозволяє дослідити моральний стан, який напряму впливає на швидкість, креативність і якість. Зниження задоволеності зазвичай передує падінню всіх інших метрик.
Так, якщо команда щоквартально оцінює задоволеність і середній бал впав з 8,2 до 6,1, це сигнал того, що треба розібратись. Можливо, змінилися пріоритети, з’явився надлишок бюрократії або команда не бачить результату своєї роботи. - Capacity Utilization — чи не працює команда понаднормово
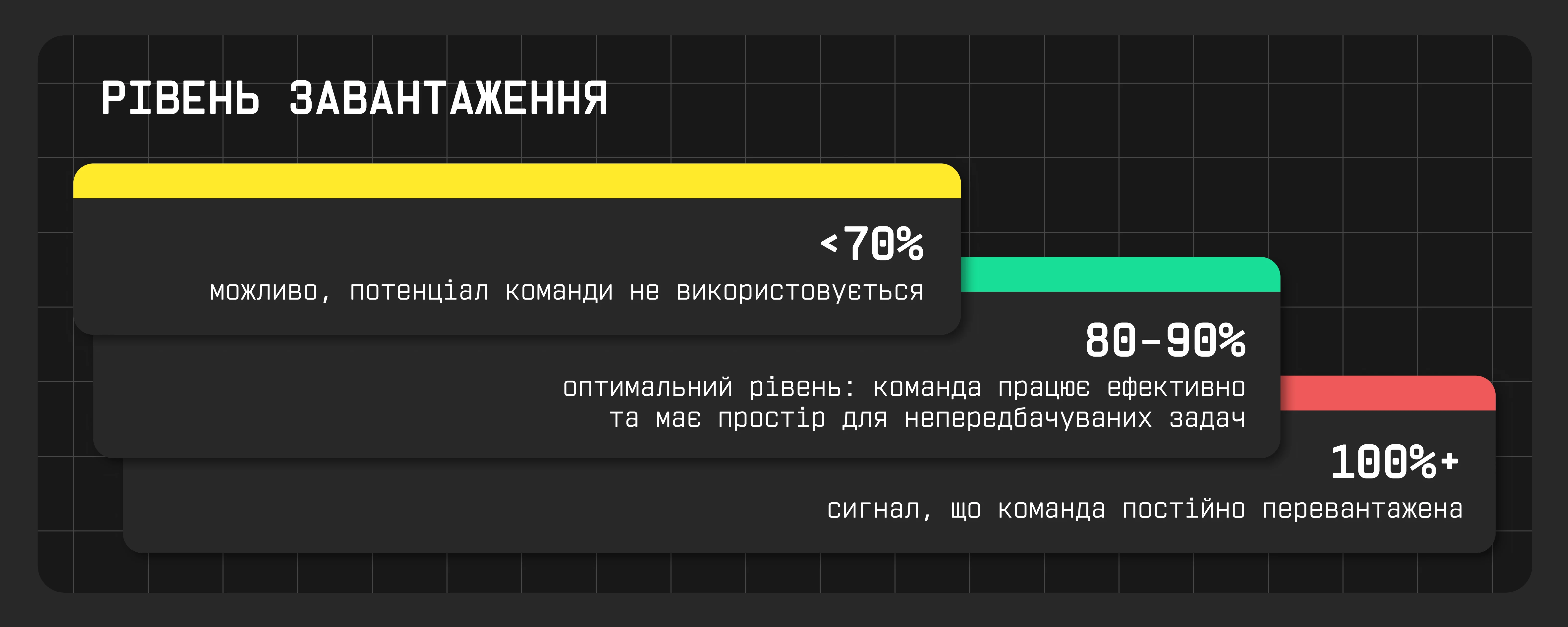
Це співвідношення між запланованим навантаженням і тим, що команда реально виконує.
Capacity Utilization допомагає побачити, чи не перевищує планування реальні можливості команди. Якщо люди постійно працюють на межі, це прямий шлях до вигорання. До прикладу:
На завершення
Навіть самі метрики, про які йдеться в тексті, говорять самі за себе: вони не «для галочки» й не спосіб «тримати всіх під мікроскопом». Це інструменти, які допомагають бачити реальну картину, ухвалювати зважені рішення та регулярно покращувати процеси.
Вони показують не тільки те, що команда робить, але й те, як вона це робить: наскільки швидко рухається до цілей, чи не страждає якість, чи стабільні релізи, чи не згорять люди на цьому шляху.
Успішний Engineering Manager не просто збирає показники, а читає сигнали, які дають ці дані, і перетворює їх на дії. І саме це відрізняє команду, яка просто пише код, від тієї, що реально рухає продукт і бізнес уперед.


