
Що таке «прокляття розмірності» і як її знизити
Метод одновимірного вибору ознак, факторний аналіз і LDA
Вважають, що модель варто навчати на якомога більшому обсязі різноманітних даних. Але іноді, якщо інформації стає забагато, вона гальмує або зупиняє процес навчання. Щоб модель працювала нормально, потрібно зменшити кількість ознак, обравши найефективніші. Для цього застосовують методи зниження розмірності.
Розповідаємо про них.
Що таке «прокляття розмірності»
Навчаючи моделі, потрібно надати їм на вході змінні (наприклад, колір і вартість товару). Їхню кількість називають розмірністю.
Термін «прокляття розмірності» 1961 року ввів американський математик Річард Беллман. Він описав труднощі під час опрацювання датасетів з великою кількістю параметрів: складність обчислень, що зростає, потребу великого обсягу пам’яті для зберігання датасетів, збільшення шуму та проблему перенавчання мереж.
Беллман пояснив зростання розмірності системи на прикладі одиничного інтервалу [0,1]. 100 точок здатні заповнити цей інтервал за частоти від 0,01. Але якщо ми створимо модель 10-вимірного куба, то знадобиться вже 1020 точок, тобто в 1018 разів більше. Беллман бачив розв’язання цієї проблеми в зниженні розмірності простору і перенесенні даних на простори з меншою розмірністю.
Під час кластеризації велика кількість змінних призводить до того, що точки даних мають вигляд рівновіддалених одна від одної. Це ще один негативний наслідок прокляття розмірності.
Зниження розмірності — метод підготовки даних перед навчанням моделі. Його можна виконати після очищення і масштабування даних.
Модель, навчена на даних із широким набором ознак, наражається на ризик перенавчання. Це призводить до зниження точності. Боротьба з перенавчанням — основна мета зменшення розмірності. Що менше припущень робить модель, то вона простіша.
Інші переваги зниження розмірності:
- вища швидкість навчання;
- потрібно менше місця для зберігання;
- видалення зайвого шуму.


Ключові методи зниження розмірності
Для зниження розмірності використовують методи вибору та проєктування змінних.
Вибір змінних — це найпростіший спосіб зменшення розмірності. А проєктування — створення нових змінних на основі наявних шляхом їх перетворення.
Наприклад, нам потрібна модель, яка прогнозує середній чек. Ми маємо масив даних, який детально описує кожного покупця. Стовпець із кольором очей не допоміг би передбачити чек. На відміну від інформації про дохід покупців.
Метод порога відхилення (Variance Threshold) — простий спосіб вибору змінних. Він відкидає всі ознаки, в яких дисперсія не перевищує заданого порогового значення. Поріг обирають з огляду на дані.
Маленька дисперсія часто трапляється в ознак, у яких значення багатьох рядків збігається (наприклад, ознака «мільярдер», найімовірніше, буде марною).
Метод одновимірного вибору ознак (Univariate Feature Selection) застосовує статистичні тести. Його називають одновимірним, тому що він аналізує змінні по черзі, порівнюючи їх із цільовим показником. Ознаки, які слабо корелюють із ним, відкидаються.
Приклади статистичних тестів — кореляція Пірсона, кореляція відстані, дисперсійний аналіз і хі-квадрат.
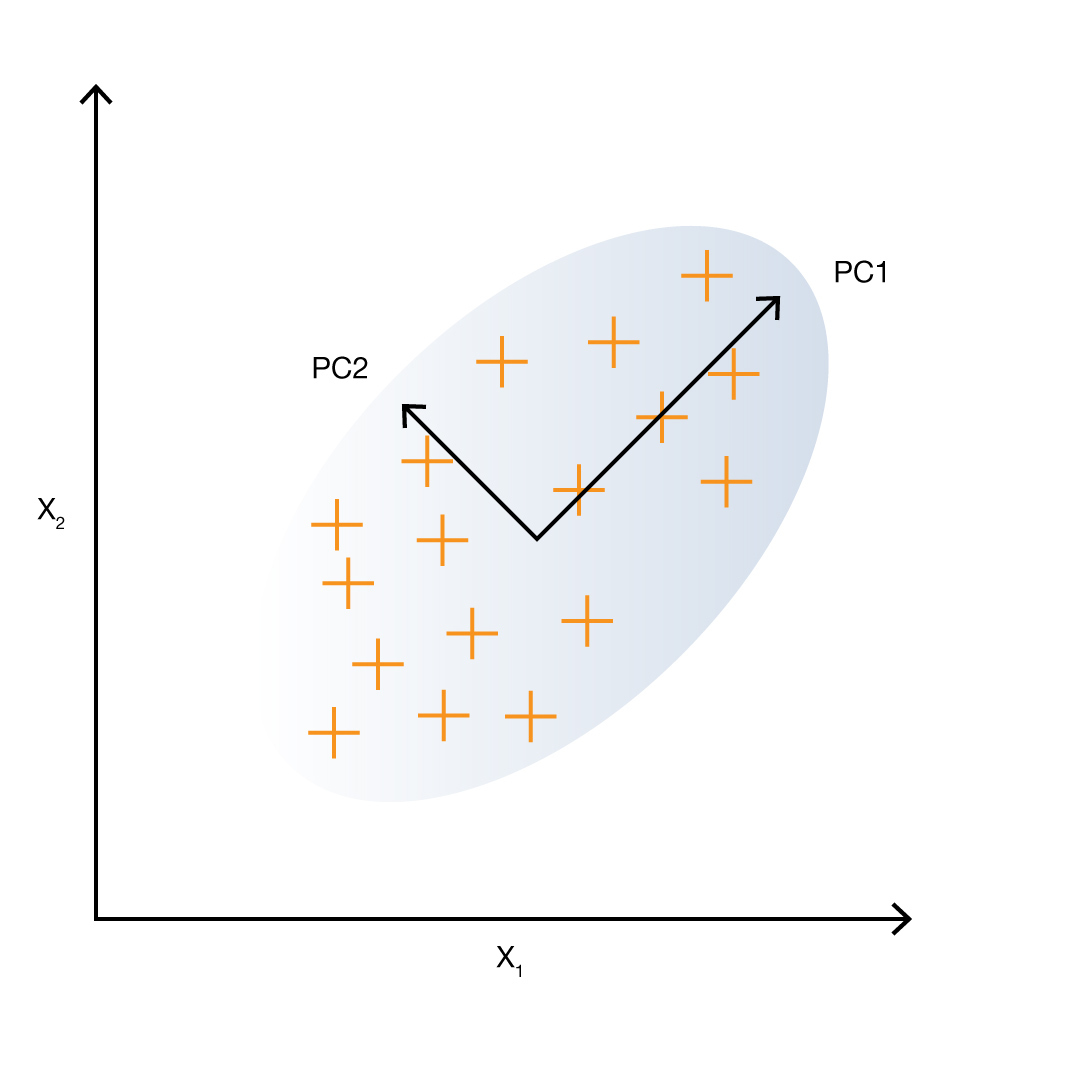
Найпоширеніші методи проєктування змінних використовують лінійні перетворення. Наприклад, PCA (Principal Component Analysis). Його залучають для зменшення розмірності континуальних даних (температура, вага, рівень гемоглобіну в крові). Він дає змогу знизити втрату інформації за зменшення розмірності.
PCA застосовують, якщо деякі ознаки корелюють одна з одною. Він створює з них незалежні лінійні комбінації. Часто дисперсії отриманих ознак сильно відрізняються. У такому разі ознаки з низькою дисперсією можна відкинути, тому що вони менш інформативні.
Цей метод розв’язує два завдання: створює більш інформативні ознаки та зменшує шум у даних.
Факторний аналіз (Factor analysis), як і PCA, створює нові ознаки, комбінуючи наявні. Його відмінність у тому, що FA передбачає наявність реальних прихованих чинників, які визначають спостережувані. Крім того, він пояснює частину дисперсії спостережуваних параметрів помилками вимірювання, а частину — реальною дисперсією прихованих факторів.
Дані мають бути кількісними, вимірюватися за інтегральною шкалою або шкалою відносин. Категорійні дані (релігія, місце народження, стать) не підходять для цього методу.
Наприклад, коли людина обирає меблі, її рішення ґрунтується на низці чинників: її віці, доході, площі квартири. Це приховані чинники (їх не знають власники магазину), і завдання аналізу — виявити їх. Використовуйте цей метод, якщо вважаєте, що такі фактори існують.
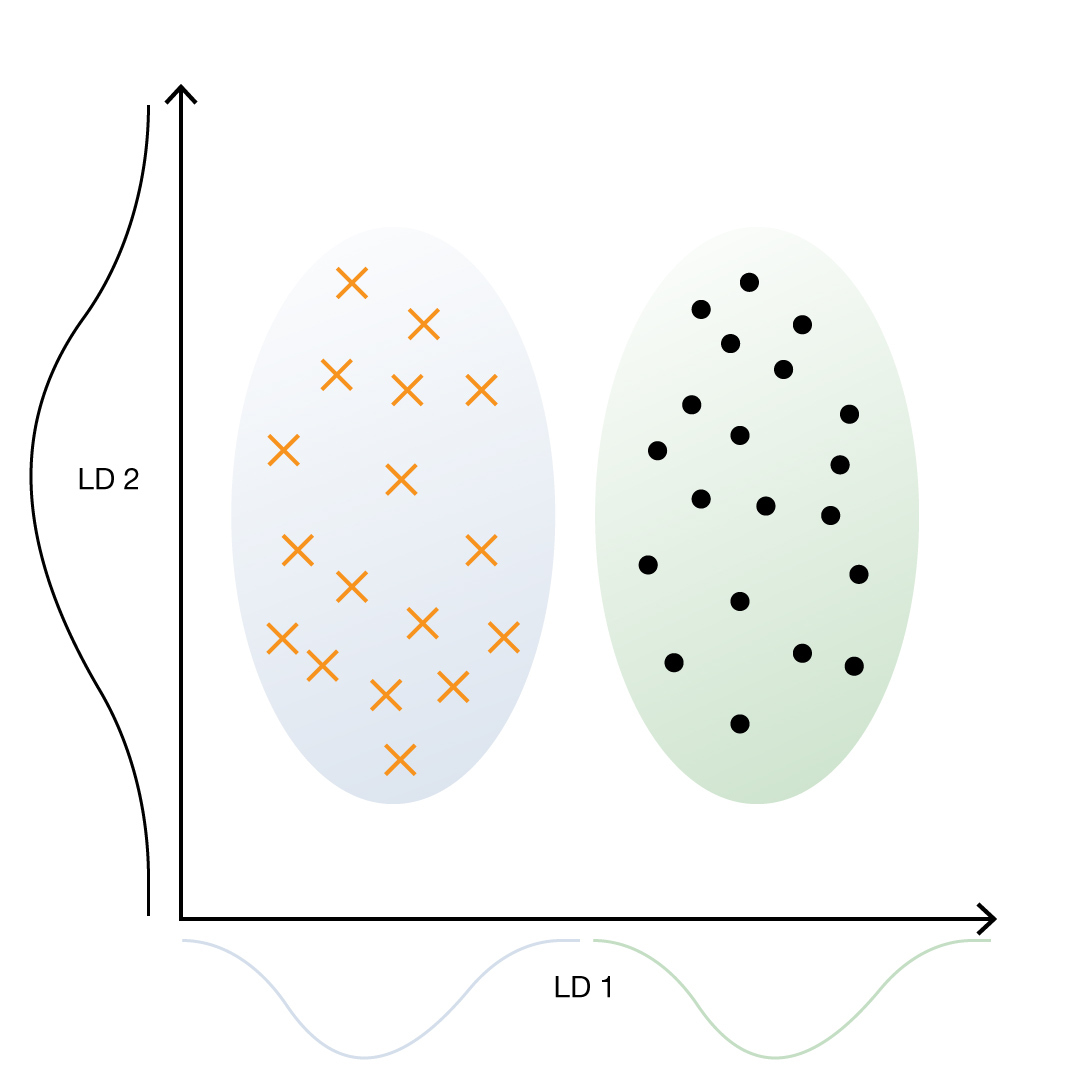
LDA (Linear Discriminant Analysis) застосовують для завдань класифікації. Цим методом часто послуговуються для зменшення розмірності впродовж попередньої обробки даних. Мета — спроєктувати набір даних на простір меншої розмірності з гарною роздільністю кластерів. Метод робить припущення про нормально розподілені класи та рівні коваріації класів. Його можна задіювати навіть у випадках, коли класів понад два.
Нелінійні методи зниження розмірності
Методи нелінійного перетворення використовують, коли дані не лежать у лінійному підпросторі. Якщо лінійний підпростір тривимірного простору можна уявити як плоский аркуш паперу, то прикладом нелінійного різноманіття буде згорнутий аркуш.
До нелінійних методів належить, наприклад, багатовимірне масштабування (MDS), ізометричне відображення об’єктів (Isomap), локально-лінійне вкладення (LLE), власне відображення Гессе та інші.
Популярний метод зменшення розмірності, який дає неймовірні результати, — автокодувальник. Це тип штучної нейромережі, що навчається копіювати свої вхідні дані у вихідні, маючи зменшений, порівняно з вхідним і вихідним, проміжний шар. Автокодувальник стискає вхідні дані в значення ваг проміжного шару, а потім реконструює вихідні дані з цих значень.


