
Что такое «проклятие размерности» и как ее снизить
Метод одномерного выбора признаков, факторный анализ и LDA.
Считается, что модель стоит обучать на как можно большем объеме разнообразных данных. Но иногда, если информации становится слишком много, она тормозит или останавливает процесс обучения. Чтобы модель работала нормально, нужно уменьшить количество признаков, выбрав самые эффективные. Для этого применяют методы снижения размерности.
Рассказываем о них.
Что такое «проклятие размерности»
Обучая модели, нужно предоставить им на входе переменные (например, цвет и стоимость товара). Их количество называют размерностью.
Термин «проклятие размерности» в 1961 году ввел американский математик Ричард Беллман. Он описал трудности при обработке датасетов с большим количеством параметров: возрастающую сложность вычислений, необходимость большого объема памяти для хранения датасетов, рост шума и проблему переобучения сетей.
Беллман объяснил рост размерности системы на примере единичного интервала [0,1]. 100 точек способны заполнить этот интервал при частоте от 0,01. Но если мы создадим модель 10-мерного куба — нам потребуется уже 1020 точек, то есть в 1018 раз больше. Беллман видел решение этой проблемы в снижении размерности пространства и переносе данных на пространства с меньшей размерностью.
При кластеризации большое количество переменных приводит к тому, что точки данных выглядят равноудаленными друг от друга. Это еще одно негативное следствие проклятия размерности.
Снижение размерности — метод подготовки данных перед обучением модели. Оно может быть выполнено после очистки и масштабирования данных.
Модель, обученная на данных с широким набором признаков, подвергается риску переобучения. Это приводит к снижению точности. Борьба с переобучением — основная цель уменьшения размерности. Чем меньше предположений делает модель, тем она проще.
Другие преимущества снижения размерности:
- более высокая скорость обучения;
- нужно меньше места для хранения;
- удаление лишнего шума.


Ключевые методы снижения размерности
Для снижения размерности используют методы выбора и проектирования переменных.
Выбор переменных — это самый простой способ уменьшения размерности. А проектирование — создание новых переменных на основе существующих путем их преобразования.
Например, нам нужна модель, которая прогнозирует средний чек. У нас есть массив данных, который подробно описывает каждого покупателя. Столбец с цветом глаз не помог бы предсказать чек. В отличие от информации о доходе покупателей.
Метод порога отклонения (Variance Threshold) — простой способ выбора переменных. Он отбрасывает все признаки, в которых дисперсия не превышает заданного порогового значения. Порог выбирается с учетом данных.
Маленькая дисперсия часто встречается у признаков, в которых значение многих строк совпадает (например, признак «миллиардер», скорее всего, будет бесполезен).
Метод одномерного выбора признаков (Univariate Feature Selection) применяет статистические тесты. Он называется одномерным, потому что анализирует переменные по очереди, сравнивая их с целевым показателем. Признаки, которые слабо коррелируют с ним, отбрасываются.
Примеры статистических тестов — корреляция Пирсона, корреляция расстояния, дисперсионный анализ и хи-квадрат.
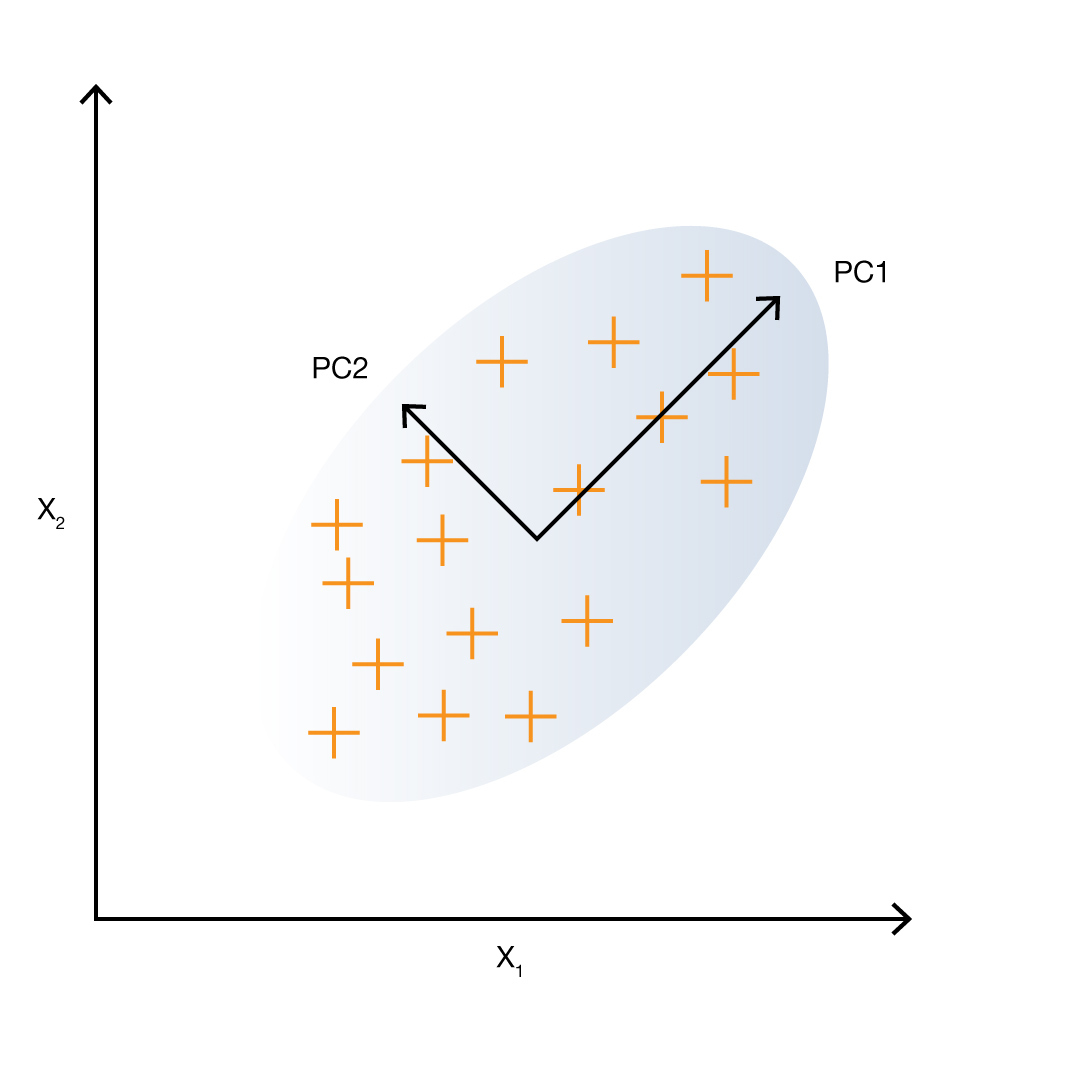
Самые распространенные методы проектирования переменных используют линейные преобразования. Например, PCA (Principal Component Analysis). Его применяют для уменьшения размерности континуальных данных (температура, вес, уровень гемоглобина в крови). Он позволяет снизить потерю информации при уменьшении размерности.
PCA применяется, если некоторые признаки коррелируют друг с другом. Он создает из них независимые линейные комбинации. Часто дисперсии получившихся признаков сильно отличаются. В таком случае признаки с низкой дисперсией можно отбросить, потому что они менее информативны.
Этот метод решает две задачи: создает более информативные признаки и уменьшает шум в данных.
Факторный анализ (Factor analysis), как и PCA, создает новые признаки, комбинируя существующие. Его отличие в том, что FA предполагает наличие реальных скрытых факторов, которые определяют наблюдаемые. Кроме того, он объясняет часть дисперсии наблюдаемых параметров ошибками измерения, а часть — реальной дисперсией скрытых факторов.
Данные должны быть количественными, измеряться по интегральной шкале или шкале отношений. Категориальные данные (религия, место рождения, пол) не подходят для этого метода.
Например, когда человек выбирает мебель, его решение основано на ряде факторов: его возрасте, доходе, площади квартиры. Это скрытые факторы (их не знают владельцы магазина), и задача анализа — выявить их. Используйте этот метод, если считаете, что такие факторы существуют.
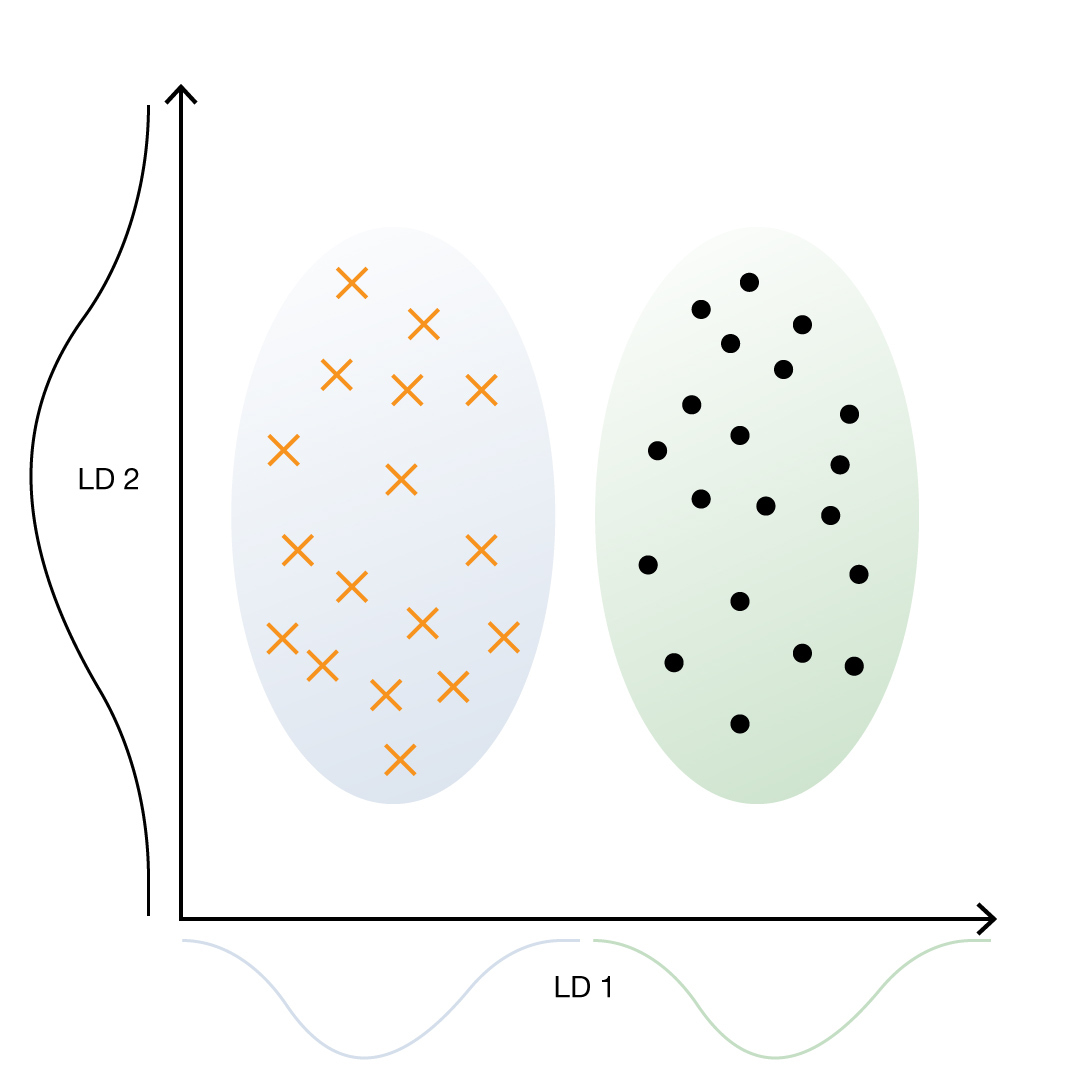
LDA (Linear Discriminant Analysis) используется для задач классификации. Этот метод часто применяют для уменьшения размерности при предварительной обработке данных. Цель — спроецировать набор данных на пространство меньшей размерности с хорошей разделимостью кластеров. Метод делает предположения о нормально распределенных классах и равных ковариациях классов. Его можно применять даже в случаях, когда классов больше двух.
Нелинейные методы снижения размерности
Методы нелинейного преобразования используются, когда данные не лежат в линейном подпространстве. Если линейное подпространство трехмерного пространства можно представить как плоский лист бумаги, то примером нелинейного многообразия будет свернутый лист.
К нелинейным методам относится, например, многомерное масштабирование (MDS), изометрическое отображение объектов (Isomap), локально-линейное вложение (LLE), собственное отображение Гессе и другие.
Популярный метод уменьшения размерности, который дает впечатляющие результаты, — автокодировщик. Это тип искусственной нейросети, который обучается копировать свои входные данные в выходные, имея уменьшенный, по сравнению с входным и выходным, промежуточный слой. Автокодировщик сжимает входные данные в значения весов промежуточного слоя, а затем реконструирует выходные данные из этих значений.


