
Попередньо навчені моделі
Що це таке, чому вони важливі та де їх узяти.
Євгенія Сорока, Software Development Engineer в Amazon Web Services розповідає, що таке трансферне навчання і як шукати попередньо навчені моделі.

За допомогою deep learning можна розв’язати багато завдань computer vision — наприклад, виявлення та класифікації об’єктів, розпізнавання облич, генерації зображень, сегментації.
Навчання моделі може займати від лічених хвилин до кількох місяців (залежно від набору даних і конкретної задачі). Через значні обчислювальні витрати ще кілька років тому цим займалися дослідницькі університети та великі технологічні компанії. Нині нам допомагає трансферне навчання.
Трансферне навчання
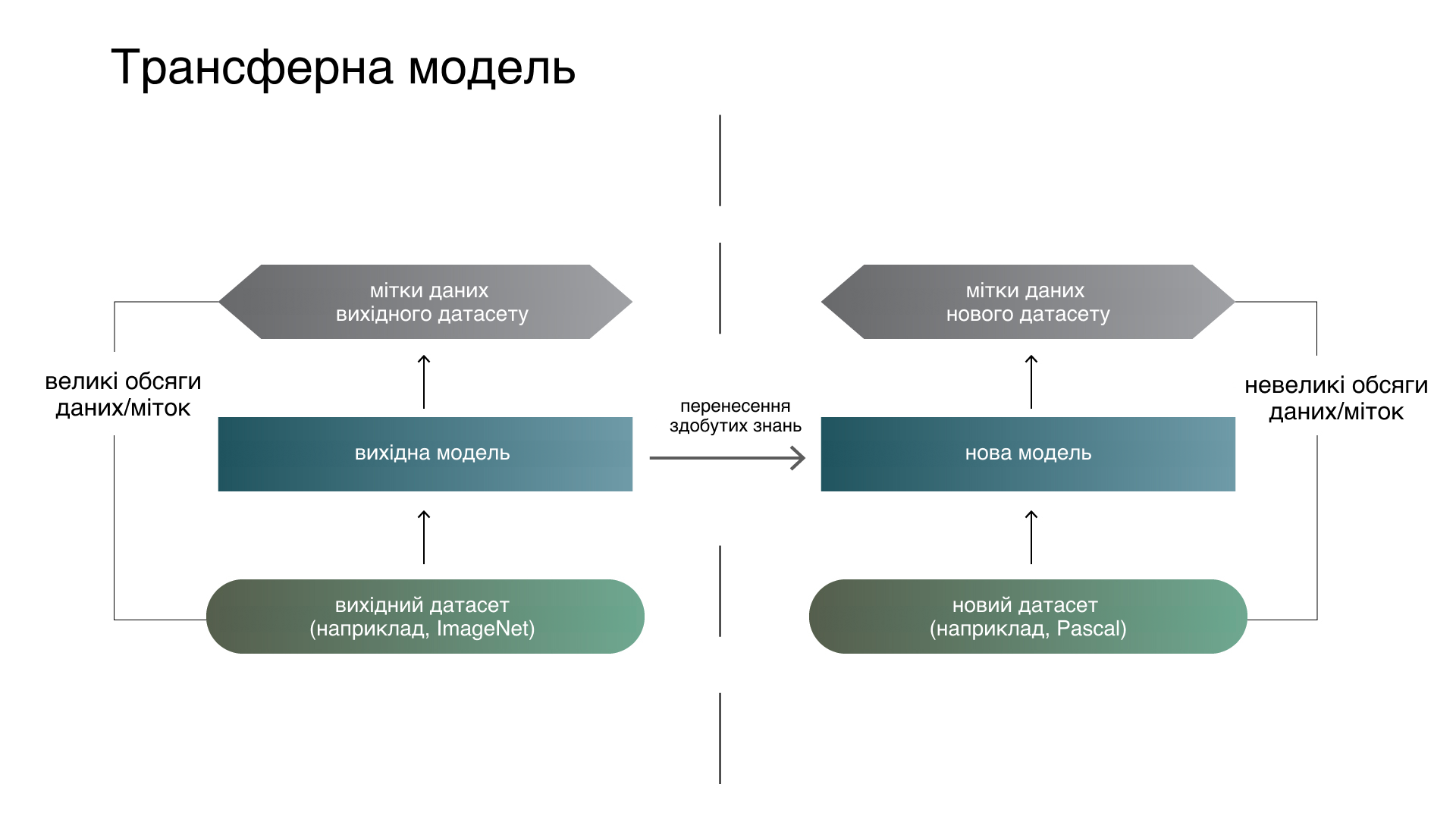
Трансферне навчання — підрозділ ML. Його мета — застосування знань, отриманих завдяки розв’язанню одного завдання, до іншого, але схожого завдання. Це популярний метод комп’ютерного зору — він дає змогу отримати точні моделі, заощаджуючи час та гроші. При перенесенні навчання ми починаємо з ознак, засвоєних під час розв’язання іншого завдання, замість того, щоби тренувати моделі з нуля.
Ще у 2016 році Ендрю Ін спрогнозував зростання популярності методу: «Трансферне навчання буде наступним двигуном комерційного успіху ML після навчання з учителем».
Попередньо навчені моделі:
що це й де їх шукати
Трансферне навчання передбачає використання попередньо навчених моделей (створених та натренованих на великому наборі загальнодоступних даних). Найчастіше їх розробляють великі технологічні компанії чи провідні дослідники у сфері комп’ютерного зору. Ці моделі навчаються на значних обсягах даних (наприклад, ImageNet — ~14 млн зображень, Google Landmarks Dataset v2 — ~5 млн зображень).
Вибір попередньо навченої моделі залежить від завдання. YOLOv2 використовується для виявлення та класифікації об’єктів, OpenFace — для розпізнавання облич, ResNet — для класифікації зображень.
Для успішного трансферного навчання потрібна модель, натренована на наборі даних, схожому з цільовим. Так, модель, навчена на зображеннях облич, не найкраще узагальнюється для завдання розпізнавання тексту. Тому популярні моделі, навчені на великих і різноманітних наборах даних (вивчені ознаки трапляються в інших наборах із високою ймовірністю).
Фреймворки машинного навчання — одне із джерел натренованих моделей. Набори пропонованих моделей надають Tensorflow, PyTorch, Keras, Caffe2. Наприклад:
- Tensorflow Model Garden — репозиторій із безліччю реалізацій SOTA-моделей на основі TensorFlow.
- Моделі Torchvision включають основні архітектури для завдання класифікації зображень (AlexNet, VGG, ResNet та інші).
- Keras applications надає колекцію популярних моделей для задач класифікації, які легко підвантажити за допомогою оболонки Keras.
- Caffe и Caffe2 також надають набір попередньо навчених моделей.


Колекції моделей за сферами застосування
Більшість моделей, які надаються фреймворками, фокусуються на задачі класифікації зображень або виявлення та сегментації об’єктів. Якщо завдання інше, моделі потрібно шукати, відштовхуючись від нього.
- TensorFlow Hub пропонує моделі, розподілені за тематиками: класифікація зображень та відео, вектор ознак, виявлення об’єктів, сегментація, перенесення стилю, генератор, виявлення пози.
- Model Zoo — платформа з великим набором натренованих моделей для ентузіастів та дослідників глибокого навчання (на різних платформах та сферах застосування, включно з TensorfFlow, PyTorch, Caffee).
Як використовувати попередньо навчені моделі
Припустимо, ми знайшли потрібну натреновану модель. Розглянемо, як її використати, на прикладі задачі класифікації.
Щоби перепрофілювати навчену модель, потрібно замінити вихідний класифікатор на нові (відповідні наші класи) і донавчити модель на наших даних. Є три варіанти:
- Навчання всієї моделі передбачає потенційне оновлення всіх коефіцієнтів вихідної моделі відповідно до нашого набору зображень.
- Навчання кількох згорткових шарів передбачає заморожування ваг початкових шарів нейромережі (відповідних загальним ознакам зображень, незалежних від завдання), та оновлення вищих рівнів (які стосуються конкретних функцій залежно від завдання).
- Навчання класифікатора відповідає збереженню згорткової бази нейронної мережі та використанню її вихідних даних для подачі в новий класифікатор.
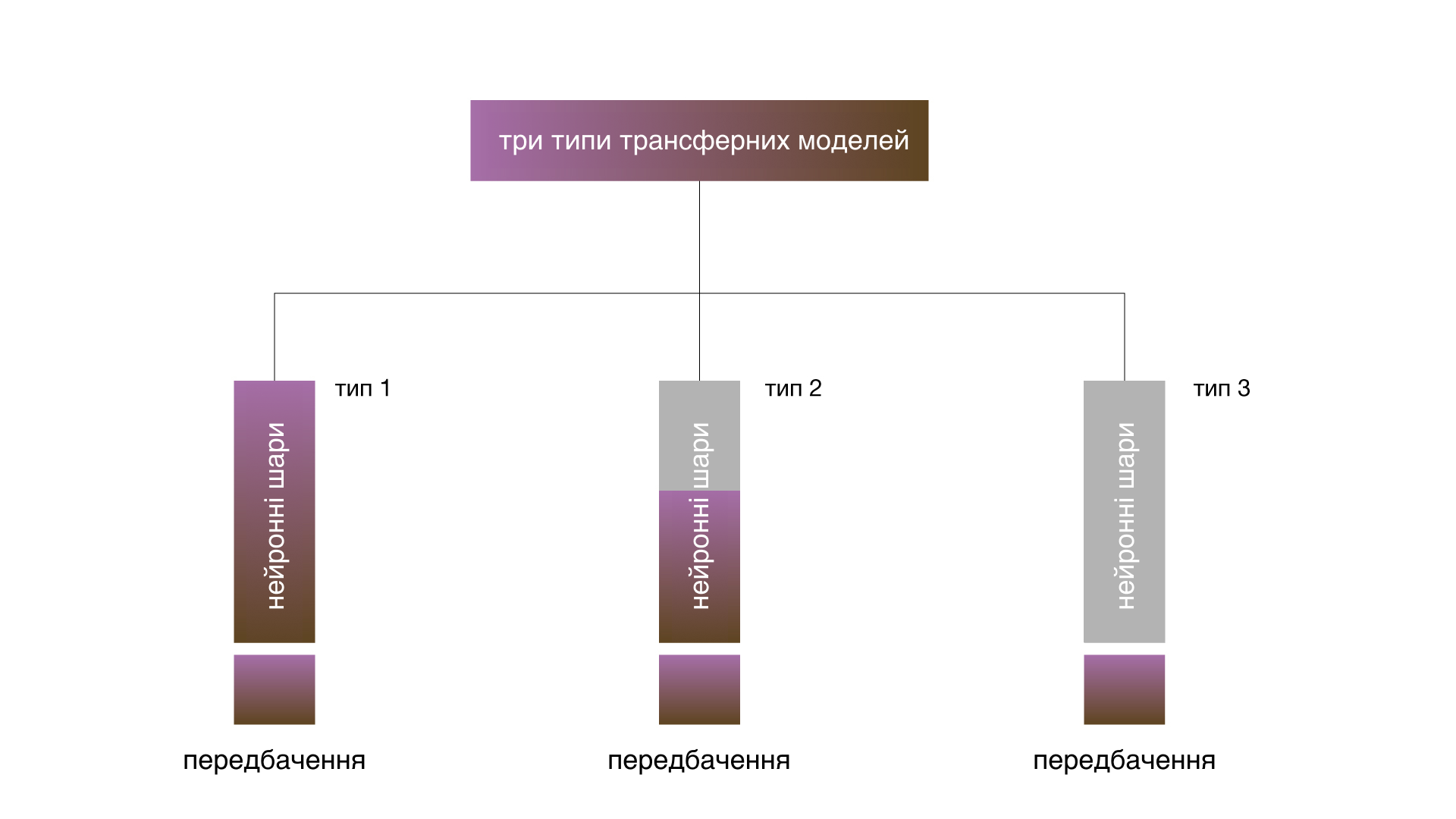
Навчання всієї моделі корисне за наявності великого набору даних та обчислювальної потужності. Якщо набір зображень маленький, більшість шарів заморожують, щоб уникнути оверфіту (overfit), коли модель запам’ятовує доступні зображення й погано узагальнюється. Якщо обчислювальної потужності не вистачає, набір даних невеликий та/або попередньо навчена модель розв’язує дуже схоже завдання, підійде класифікатор навчання. У цьому випадку попередньо навчена модель відіграє роль фіксованого механізму отримання ознак.
У курсі Computer vision ми застосуємо трансферне навчання на практиці — швидко та не дуже витратно розробимо систему для розв’язання одного з найпоширеніших завдань.


