
Предобученные модели
Что это такое, почему они важны и где их взять.
Евгения Сорока, Software Development Engineer в Amazon Web Services, рассказывает, что такое трансферное обучение и как искать предобученные модели.

С помощью deep learning можно решить многие задачи computer vision — обнаружения и классификации объектов, распознавания лиц, генерации изображений, сегментации.
Обучение модели может занимать от считанных минут до нескольких месяцев (в зависимости от набора данных и конкретной задачи). Из-за значительных вычислительных затрат еще несколько лет назад этим занимались исследовательские университеты и крупные технологические компании. Сейчас нам помогает трансферное обучение.
Трансферное обучение
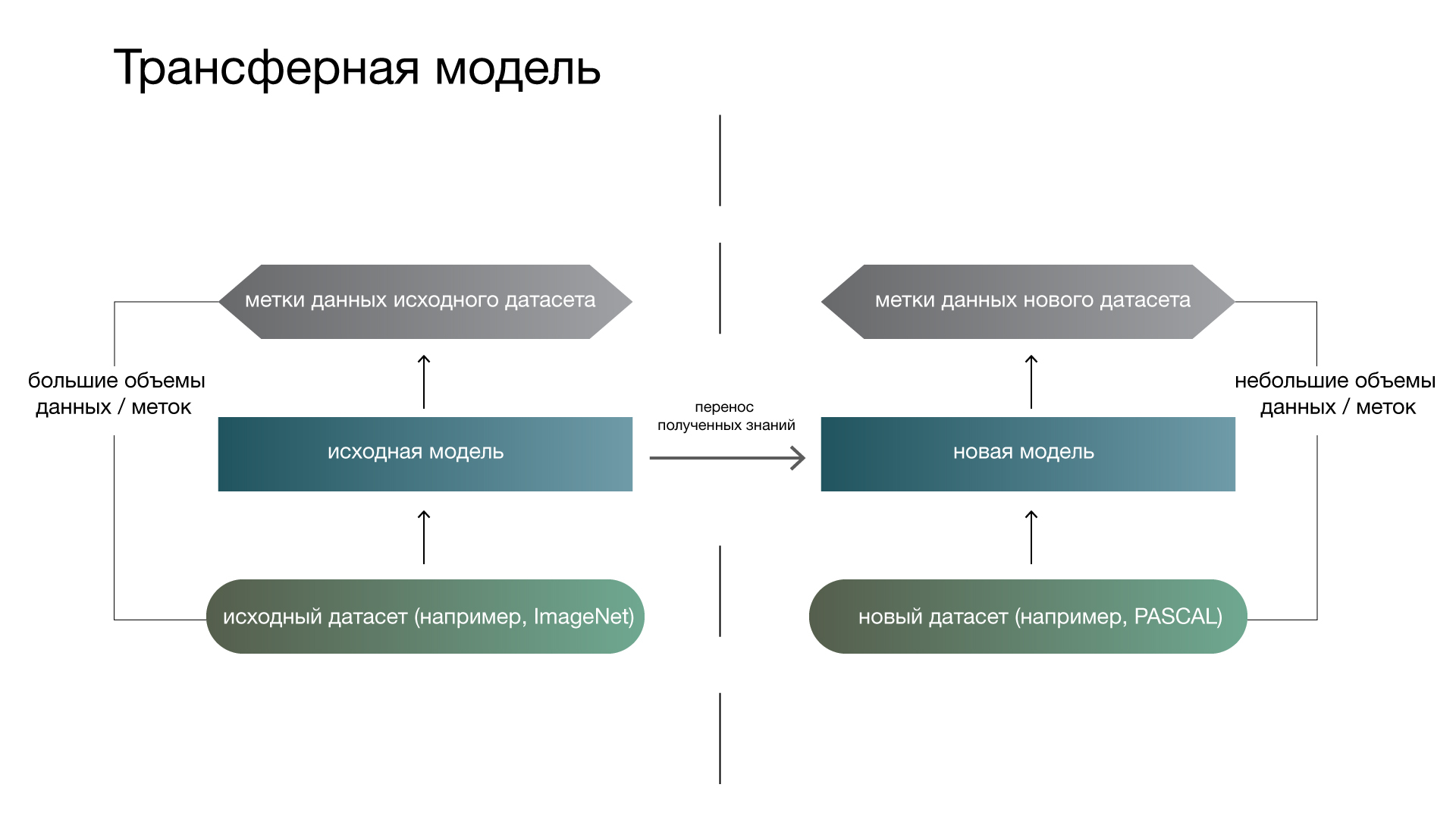
Трансферное обучение — подраздел ML. Его цель — применение знаний, полученных благодаря решению одной задачи, к другой, но схожей задаче. Это популярный метод компьютерного зрения — он позволяет получить точные модели, экономя время и деньги. При переносе обучения мы начинаем с признаков, усвоенных при решении другой задачи, вместо того чтобы тренировать модели с нуля.
Еще в 2016 году Эндрю Ын спрогнозировал рост популярности метода: «Трансферное обучение будет следующим двигателем коммерческого успеха ML после обучения с учителем».
Предобученные модели: что это и где их искать
Трансферное обучение предполагает использование предобученных моделей (созданных и натренированных на большом наборе общедоступных данных). Чаще всего их разрабатывают крупные технологические компании или ведущие исследователи в области компьютерного зрения. Эти модели обучаются на внушительных объемах данных (например, ImageNet — ~14 млн изображений, Google Landmarks Dataset v2 — ~5 млн изображений).
Выбор предобученной модели зависит от задачи. YOLOv2 используется для обнаружения и классификации объектов, OpenFace — для распознавания лиц, ResNet — для классификации изображений.
Для успешного трансферного обучения нужна модель, натренированная на наборе данных, схожем с целевым. Так, модель, обученная на изображениях лиц, не лучшим образом обобщается для задачи распознавания текста. Поэтому популярны модели, обученные на больших и разнообразных наборах данных (выученные признаки встречаются в других наборах с высокой вероятностью).
Фреймворки машинного обучения — один из источников натренированных моделей. Наборы предобученных моделей предоставляют Tensorflow, PyTorch, Keras, Caffe2. Например:
- Tensorflow Model Garden — репозиторий с множеством реализаций SOTA-моделей на основе TensorFlow.
- Модели Torchvision включают основные архитектуры для задачи классификации изображений (AlexNet, VGG, ResNet и другие).
- Keras applications предоставляет коллекцию популярных моделей для задачи классификации, которые легко подгрузить с помощью оболочки Keras.
- Caffe и Caffe2 также предоставляют набор готовых предобученных моделей.


Коллекции моделей по областям применения
Большинство моделей, предоставляемых фреймворками, фокусируются на задаче классификации изображений или обнаружения и сегментации объектов. Если задача иная, модели нужно искать, отталкиваясь от нее.
- TensorFlow Hub предоставляет модели, распределенные по тематикам: классификация изображений и видео, вектор признаков, обнаружение объектов, сегментация, перенос стиля, генератор, обнаружение позы.
- Model Zoo — платформа с обширным набором натренированных моделей для энтузиастов и исследователей глубокого обучения (на различных платформах и областях применения, включая TensorfFlow, PyTorch, Caffee).
Как использовать предобученные модели
Допустим, мы нашли подходящую натренированную модель. Рассмотрим, как ее использовать, на примере задачи классификации.
Чтобы перепрофилировать обученную модель, нужно заменить исходный классификатор новым (соответствующим нашим классам) и дообучить модель на наших данных. Есть три варианта:
- Обучение всей модели предполагает потенциальное обновление всех коэффициентов исходной модели в соответствии с нашим набором изображений.
- Обучение нескольких сверточных слоев предполагает замораживание весов начальных слоев нейросети (соответствующих общим признакам изображений, независимых от задачи), и обновление более высоких уровней (относящихся к конкретным функциям в зависимости от задачи).
- Обучение классификатора соответствует сохранению сверточной базы нейронной сети и использованию ее выходных данных для подачи в новый классификатор.
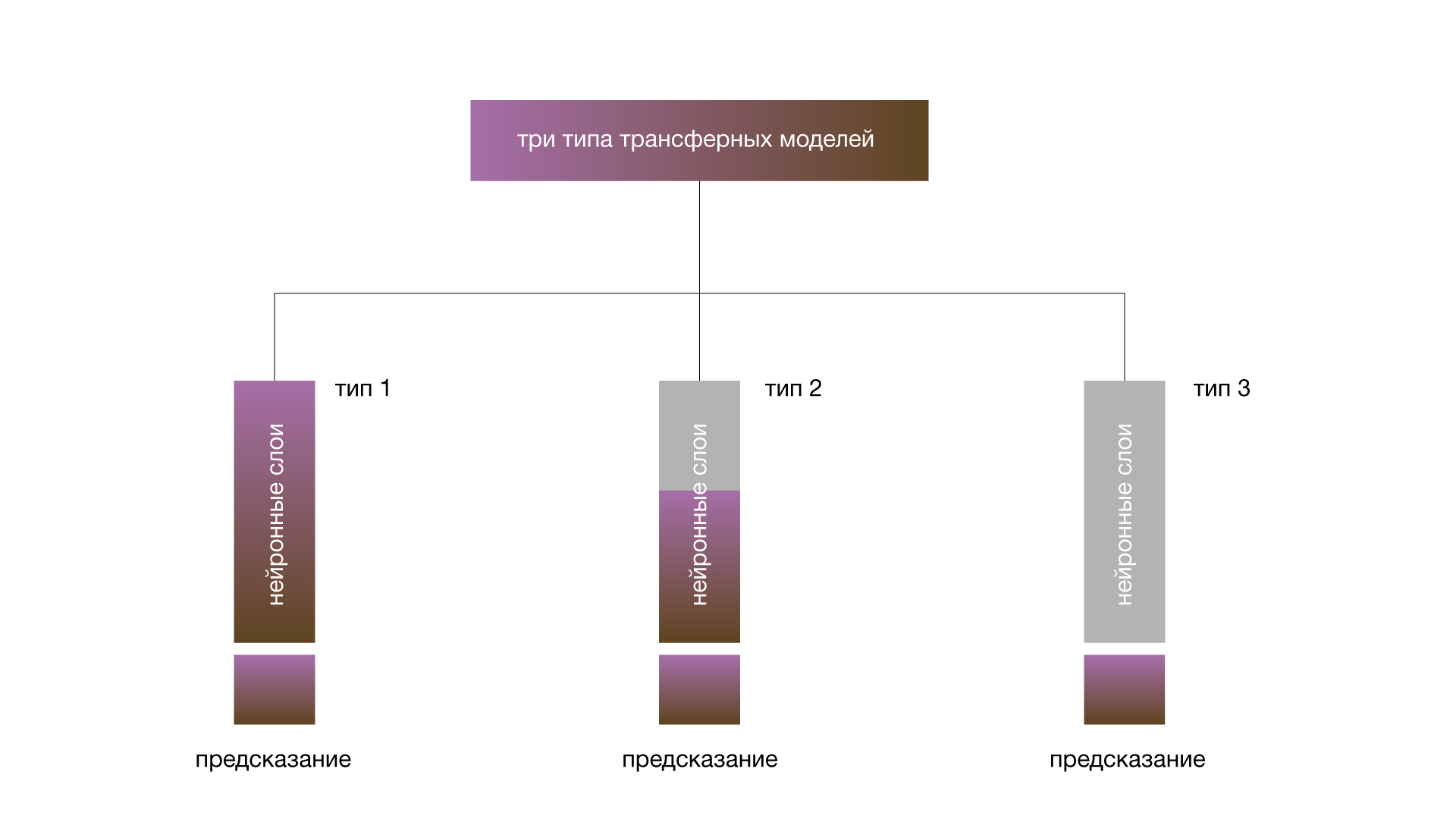
Обучение всей модели полезно при наличии большого набора данных и вычислительной мощности. Если набор изображений маленький, большинство слоев замораживают, чтобы избежать оверфита (overfit), когда модель «запоминает» доступные изображения и плохо обобщается. Если вычислительной мощности не хватает, набор данных невелик и/или предобученная модель решает очень похожую задачу, подойдет обучение классификатора. В этом случае предобученная модель играет роль фиксированного механизма извлечения признаков.
В курсе Computer vision мы применим трансферное обучение на практике — быстро и незатратно разработаем систему для решения одной из самых распространенных задач.


