
Функція втрат, n-грами та ембединг
Пояснюємо складні терміни з Machine і Deep Learning
Фахівці з Data Science займаються «випасом даних», створюють жадібні алгоритми, рахують функції втрат. Розповідаємо, що це означає.
Класичне машинне навчання
#1. Data wrangling
Популярний варіант перекладу — «випасання даних». Назва з'явилася за співзвуччям із ковбоями (wrangler), які шукають коней, що зникли.
Data wrangling — це процес, який охоплює:
- очищення даних (видалення помилкових значень);
- надання даним одного формату (наприклад, переведення в однакові одиниці виміру);
- агрегацію даних (наприклад, використання змінної «кількість кліків у відвідувача сайту» замість інформації щодо кожного кліку);
- нормалізацію даних;
- парсинг складних структур даних (наприклад, DOM-дерева сайтів);
- з'єднання різних груп даних за ключем;
- роботу з пропущеними даними;
- доповнення даних з відкритих джерел (наприклад, погодних даних);
Виконувати data wrangling можна за допомогою різних інструментів, наприклад, Pandas, OpenRefine і Trifacta Wrangler.
#2. Жадібний алгоритм
Основний принцип алгоритму — вибір найвигіднішого рішення на кожному етапі роботи. Він легко програмується, але підходить не для всіх завдань, бо не прораховує результати наступних операцій. Наприклад, якщо потрібно знайти найдовший шлях на дереві, то жадібний алгоритм на кожному кроці вибирає гілку з найбільшою вагою.
Водночас багато дерев рішень побудовані на ньому. Крім того, жадібний алгоритм вкрай швидкий і не вимагає великих обчислювальних потужностей. Його застосовують у системах навчання з підкріпленням (reinforcement learning).
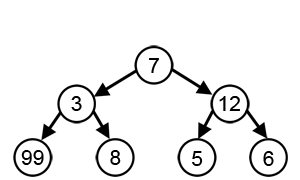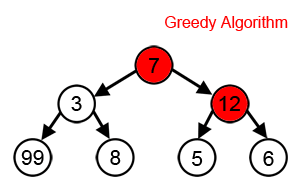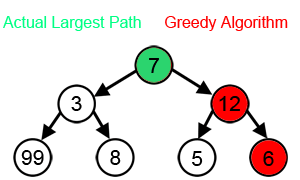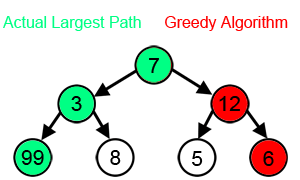
Джерело: Wikipedia
#3. Метаалгоритм
Це частина метанавчання — галузі ML, яка використовує для навчання дані інших алгоритмів. Алгоритм може надавати різну вагу поведінковим моделям залежно від кількості правильних відповідей або успішного виконання завдання.
Простий приклад метаалгоритму — «комітет більшості», який застосовують для завдань класифікації. Результатом роботи комітету вважають той варіант, за який проголосувало найбільше окремих алгоритмів.
Основні класи метаалгоритмів:
- бегінг (тренування великої кількості моделей однакової архітектури на різних підмножинах даних);
- бустинг (кожен наступний алгоритм вчиться знаходити слабкі місця попереднього і виправляти їх).
#4. Функція втрат
Щоб оцінити ML-алгоритм, потрібно обчислити, наскільки результат його роботи далекий від очікуваного. Це завдання розв’язує функція втрат. Вона визначає відстань між фактичним виходом алгоритму й очікуваним.
Що менший результат, який видає функція втрат, то краще. Але якщо він близький до нуля, це означає, що результати прогнозування нейромережі збігаються з очікуваними результатами. У реальності це неможливо.
Під час розв’язання задач регресії як функцію втрат використовують середню квадратичну помилку (MSE). Це різниця між прогнозованим значенням і істинним, піднесена до квадрата й усереднена за всім набором даних. Найпростіша функція втрат у завданні класифікації — точність (відсоток правильно вгаданих міток).
Deep learning
#1. N-грама
Це безперервна послідовність трьох або більше елементів. Елементи можуть бути різними: звуки, символи, склади, найчастіше — слова. За допомогою n-грам у нейролінгвістиці рахують словосполучення або аналізують великі масиви текстів для виявлення закономірностей і кластеризації даних. Також n-грами залучають під час оцінювання унікальності тексту.
Корисне застосування n-грам розробили в Google. Сервіс Google Books Ngram Viewer візуалізує частоту використання n-грам у всіх оцифрованих джерелах у Google Books.
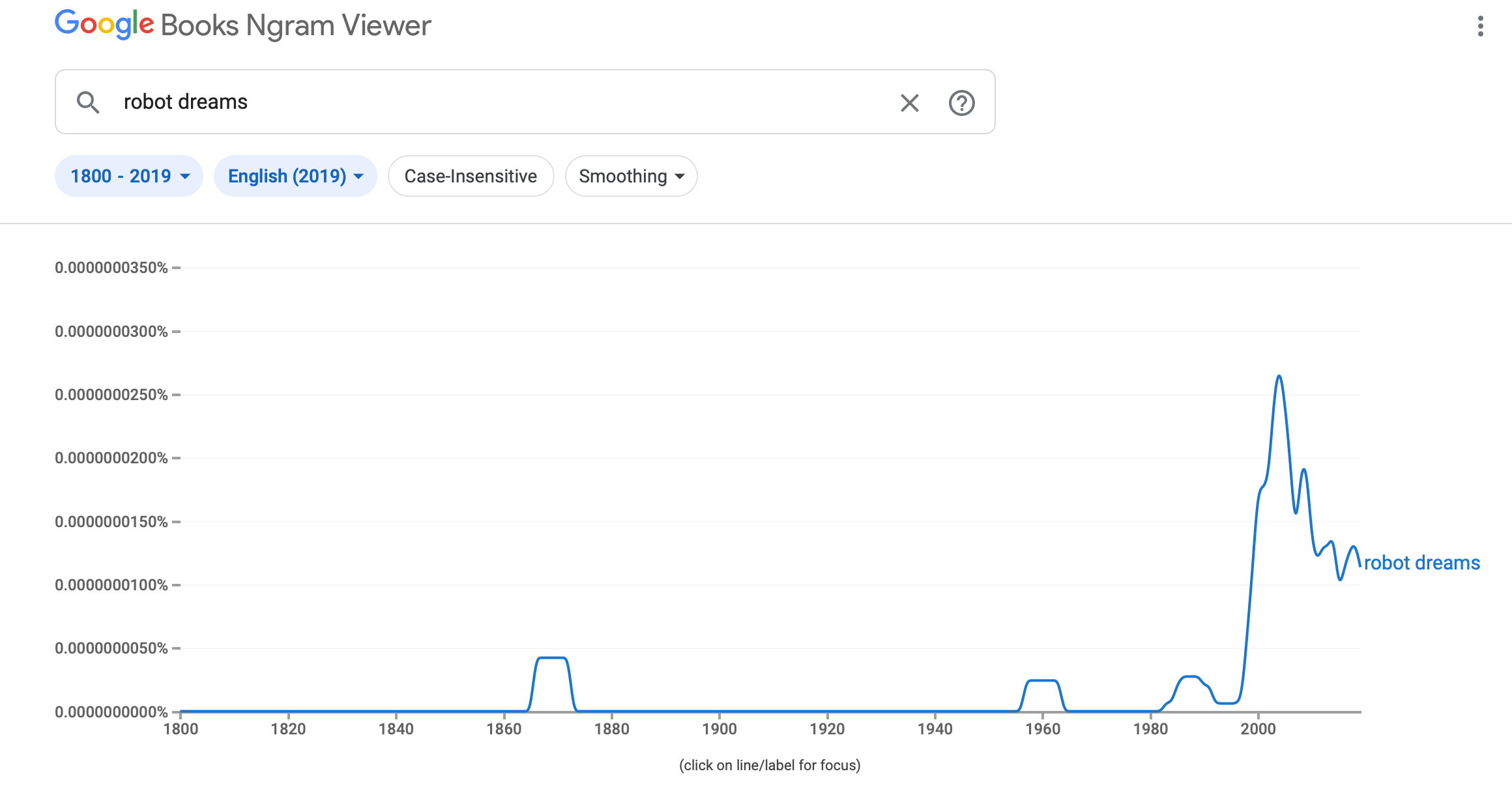
Приклад роботи сервісу
#2. Sequence-to-sequence
Спеціальний клас архітектур із періодичною нейромережею, які зазвичай використовують для машинного перекладу або створення чат-ботів. На вході seq2seq приймає одну послідовність елементів (частіше — слів), а на виході — повертає іншу.
Sequence-to-sequence складається з енкодера і декодера. Зазвичай це рекурентні нейромережі (RNN). Інформація в RNN передається в різних напрямках і в довільні часові відрізки. Енкодер обробляє вхідну інформацію і переводить у вектор контексту. Після обробки інформацію отримує декодер, який генерує вихідну послідовність.
#3. Згорткові нейромережі (CNN)
Це клас алгоритмів глибинного навчання, головні елементи яких — згортковий шар і шар пулингу. Згортковий шар можна уявити як функцію, що приймає на вхід невелику квадратну частину зображення (зазвичай 3х3 або 5х5) і повертає число, яке розраховують як суму значень пікселів, помножених на певні ваги. Таку функцію називають функцією згортки. Вона послідовно проходить усіма зонами вихідного зображення (від квадрата 3х3 у лівому верхньому кутку до такого самого квадрата в правому нижньому) і формує нове, «підсвічуючи» деталі, які визначаються видом конкретної функції згортки.
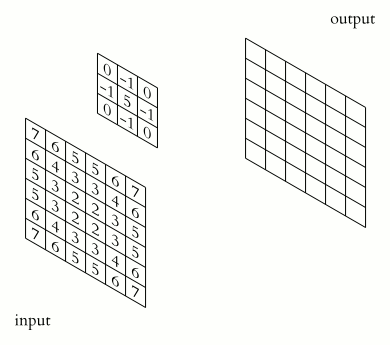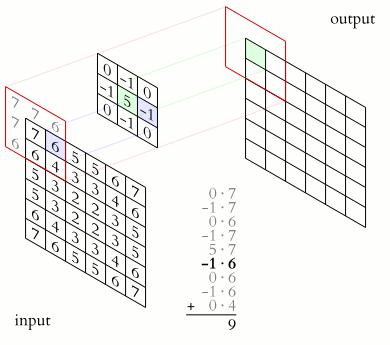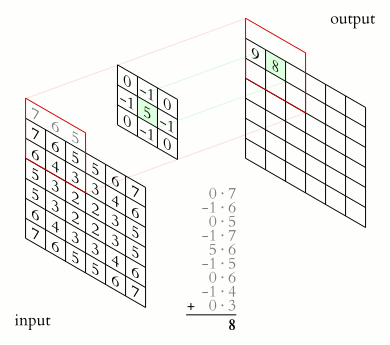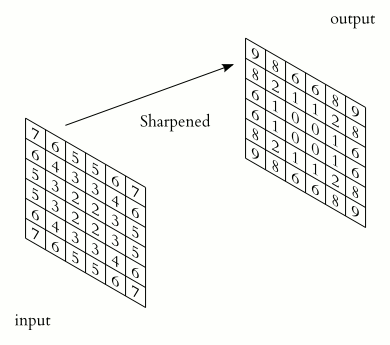
Джерело: Wikipedia
Пулинг-шар розбиває картинку, отриману від згорткового шару, на невеликі ділянки (наприклад, квадрати 2х2) і залишає тільки піксель із найбільшим значенням. У результаті кількість пікселів зменшується в кілька разів.
Ключова перевага CNN — значне зменшення кількості ваг, що налаштовуються. Якщо повнозв’язний шар між двома кольоровими картинками розміром 100х100 пікселів містить 900 млн ваг, то згортковий може містити всього 9. Водночас у пулинг-шарі ваг взагалі немає.
Тобто згорткова мережа навчається незрівнянно швидше за повнозв’язну.
Кілька років тому згорткові мережі зробили революцію в задачах розпізнавання зображень, а зараз елементи їхньої архітектури застосовують у всіх сферах машинного навчання.
#4. Стемінг
Це процес пошуку основи слова. Алгоритми стемінгу використовують для нормалізації тексту. Наприклад, під час опрацювання мови комп’ютер навчають розуміти відмінності між формою дієслів «грати» і «грають». Приклади алгоритмів, за якими працює стемінг, — пошук за таблицями флексій, а також видалення суфіксів і закінчень слів.


#5. Лематизація
Це алгоритм, який шукає лему (словникову форму слова). Його застосовують для пошуку зв’язку між словами, наприклад, «гарний» і «найкращий».
Цей підхід обробки текстових даних складніший за стемінг, але вирізняється більшою точністю.
Однак для роботи алгоритму потрібно правильно визначати, до якої частини мови належить кожне слово. Лематизація працює набагато повільніше, ніж стемінг, і вимагає великих обчислювальних ресурсів.
#6. Ембединг
Навчити комп’ютер розуміти семантично близькі слова можна за допомогою векторної (дистрибутивної) моделі. Проаналізувавши великий масив текстів, комп’ютер встановить схожість контексту вживання слів із близьким значенням. Наприклад, зрозуміє, що слова «кафе» і «ресторан» трапляються в схожих реченнях.
Векторні моделі — набори чисел, які відбивають контекст вживання слова. Ці числа і є word embedding. Нейромережа на вході отримує стислі векторні характеристики слів (embedding), а потім вирішує, яке зі слів краще підходить за контекстом.
Instagram залучає цю функцію для підбору схожих профілів. Застосунок аналізує слова, які використовують клієнти, і формує нові рекомендації.


