
Як шукати синоніми за допомогою Word2Vec
Навіщо потрібні бібліотеки для векторизації.
Комп’ютери розуміють лише числа. Щоби навчити машину природної (людської) мові, ми повинні перевести всі слова в числовий формат. Для цього можна використовувати вбудовування слів — Word2Veс.

Разом із Марією Обєдковою, NLP Engineer у TrustYou, розбираємося, як працює Word2Vec (на прикладі Python-бібліотеки Gensim).
Як перетворити текст на числа
Обробка природної мови (NLP) починається з перетворення тексту на числа — векторизації. Текст розбивають на частини (токени) — символи, слова чи речення, а потім надають числове значення кожній частині (залежно від частоти, з якою токен трапляється в тексті). Токену можна призначити не одне число, а вектор, що складається з кількох чисел.
Word2Vec — одна з реалізацій попередньо навченого векторного подання слів від Google.
Створювати вектори можна за допомогою підходів One-Hot Encoding та Embedding. У One-Hot Encoding кожен вектор складається з кількості чисел, що збігається з числом слів у тексті. Усі елементи вектора дорівнюють 0, крім того, який відповідає токену.
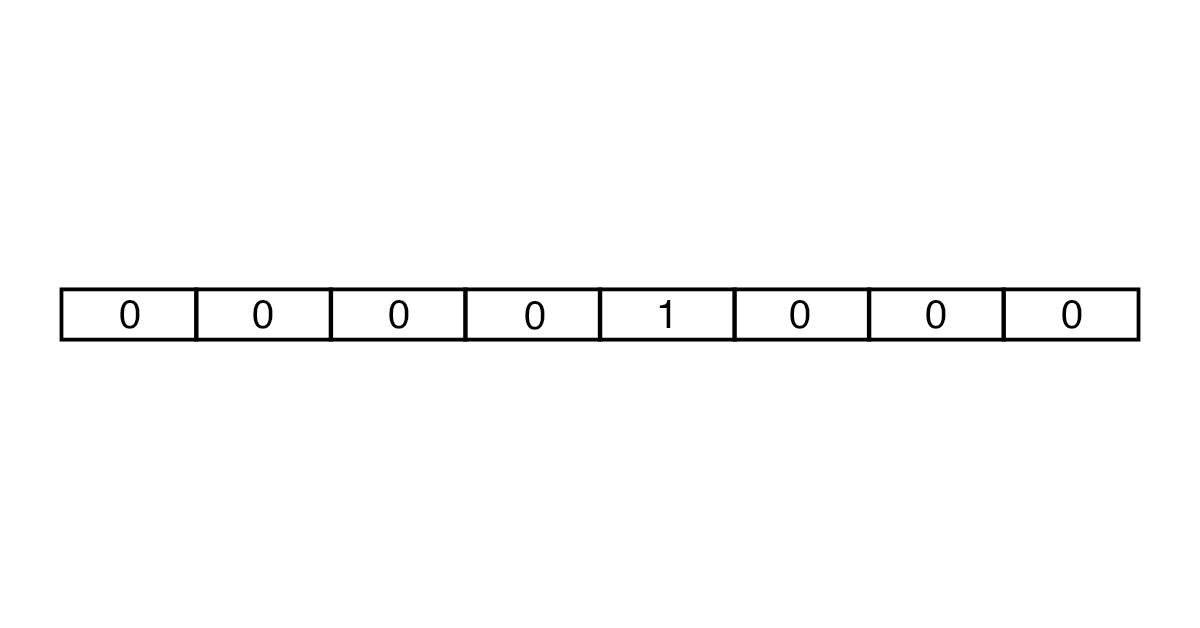
Спочатку кількість слів для аналізу обмежується за допомогою словників. Для англійської мови, наприклад, використовують словники Oxford 3000 та Merriam-Webster. Потім створюється вектор потрібної довжини з безлічі нулів та однієї одиниці. У результаті виходять вектори великого розміру, які займають багато місця в пам’яті.
Embedding вважається більш ефективним та менш ресурсомістким. У такому разі вектор може складатися не тільки з 0 та 1, але й з інших чисел. Знадобиться менше «комірок», щоби перетворити слово.
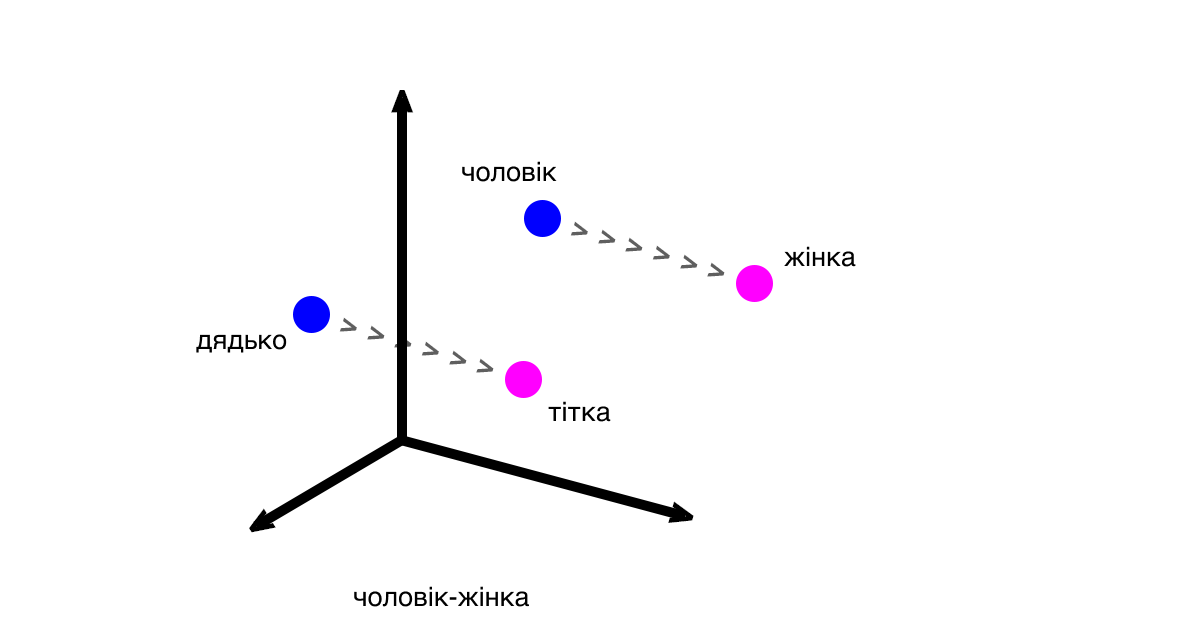
Вектори показують різницю та закономірності між частинами тексту (словами, реченнями). Класичний приклад: вектор між словами «чоловік» і «жінка» буде таким самим, як і вектор між словами «дядько» та «тітка».
Відстані між векторами відповідають змісту слів. Вираз «дядько» — «чоловік» + «жінка» буде близьким до «тітка», але водночас може не відповідати йому на 100 %.
Марія: «Word2Vec використовують як основу для великих проєктів і як спосіб розв’язання дослідницьких підзадач. Водночас в ідеї дистрибутивної семантики (того, що слово можна ідентифікувати за контекстом) є недоліки. Наприклад, схожість слів не завжди вказує на те, що вони однакові за змістом».
Пошук синонімів: пишемо скрипт
Для роботи з Word2Vec можна використовувати бібліотеку Gensim. Вона допомагає обробляти природні мови та отримувати семантичні теми з документів. Gensim «переганяє» текст у вектор і рахує відстань між векторами. Перевага бібліотеки в тому, що вона не вимагає повного завантаження корпусу в пам’ять, а дає змогу читати дані з диска.
Розповідаємо на прикладі, як векторні представлення допомагають знаходити синоніми для покращення роботи пошукових запитів.
- 1. Завантажимо бібліотеки для парсингу та аналізу сторінок.
pip install beautifulsoup4 pip install lxml - 2. Приступимо до написання скрипту та підтягнемо необхідні залежності (для парсингу, роботи з регулярними зображеннями, NLP та Gensim).
import bs4 as bs import urllib.request import re import nltk from nltk.corpus import stopwords from gensim.models import Word2Vec - 3. Парситимемо сторінку «Вікіпедії» про роман Філіпа Діка Do Androids Dream of Electric Sheep.
scrapped_data = urllib.request.urlopen('https://en.wikipedia.org/wiki/Do_Androids_Dream_of_Electric_Sheep') article = scrapped_data.read() - 4. За допомогою об’єкта BeautifulSoup витягуємо з абзаців текст.
parsed_article = bs.BeautifulSoup(article, 'lxml') paragraphs = parsed_article.find_all('p') - 5. Об’єднуємо весь текст у змінній article_text.
article_text = "" for p in paragraphs: article_text += p.text - 6. Подальша робота будь-якого скрипту залежить від того, наскільки добре ви провели очищення вихідного тексту. Тому ми переводимо всі символи до нижнього регістру.
cleaned_article = article_text.lower() - 7. Залишаємо лише літери та прибираємо пробіли, використовуючи регулярні вирази.
cleaned_article = re.sub('[^a-z]', ' ', cleaned_article) cleaned_article = re.sub(r'\s+', ' ', cleaned_article) - 8. Готуємо датасет для навчання.
all_sentences = nltk.sent_tokenize(cleaned_article) all_words = [nltk.word_tokenize(sent) for sent in all_sentences] - 9. Проходимося по датасету і видаляємо стоп-слова (ті, які не додають сенсу, наприклад, is).
for i in range(len(all_words)): all_words[i] = [w for w in all_words[i] if w not in stopwords.words('english')] - 10. Створюємо модель Word2Vec зі словами, що найчастіше трапляються в тексті. Наприклад, тими, що трапляються щонайменше 3 рази (min_count=3).
word2vec = Word2Vec(all_words, min_count=3) - 11. У межах моделі знаходимо і виводимо найближче за змістом (topn=1) слово для book.
print(word2vec.wv.most_similar('book', topn=1))
Готово — найближчий синонім слова book за нашим словником — novel.
[('novel', 0.26558035612106323)]
Таким же способом можна шукати близькі значення до окремих слів та цілих запитів.


