
9 структур даних, які вам знадобляться
Матриця, масив, стек та інші.
Структури даних — способи зберігання та вилучення інформації. Правильний вибір структури допоможе ефективніше виконати завдання. Структури даних важливі в розробці ПЗ, від них залежить, як працюватимуть алгоритми.
Розповідаємо про структури даних, які найчастіше використовуються.
#1. Масив (Array)
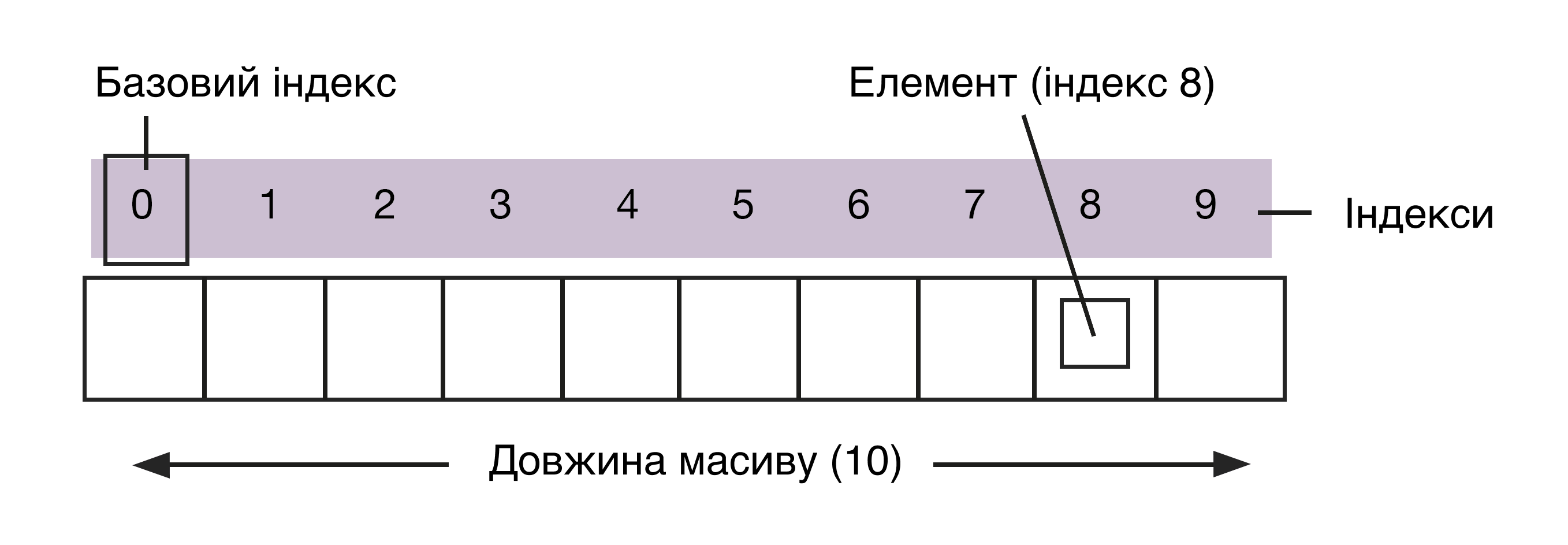
Масив — проста базова структура. Стеки, черги та списки — похідні від масивів. Одиниці даних у масиві присвоюється число чи індекс, який свідчить про її розташування. Щоби знайти комірку з інформацією в масиві, потрібно додати до базового елементу її індекс. Базовий елемент, зазвичай, позначається ім’ям самого масиву.
Уявіть записник зі сторінками, пронумерованими від 1 до 10. Кожна з них може містити інформацію або бути порожньою. Блокнот — масив сторінок, сторінки — елементи масиву «блокнот». Програмно ви отримуєте інформацію зі сторінки, звертаючись до її індексу, тобто «блокнот +4» буде посилатися на вміст четвертої сторінки.
Масив — це фіксована структура, яка зберігає елементи одного типу в безперервних осередках пам’яті. Є виняток — гетерогенні масиви, які можуть зберігати дані різних типів. Масиви бувають одномірними та багатовимірними (масиви в масивах). Їхні розміри фіксовані, тому у вже створений масив не можна просто вставити новий елемент. Потрібно скопіювати старий масив та створити новий, збільшивши розмір.
#2. Матриця (Matrix)
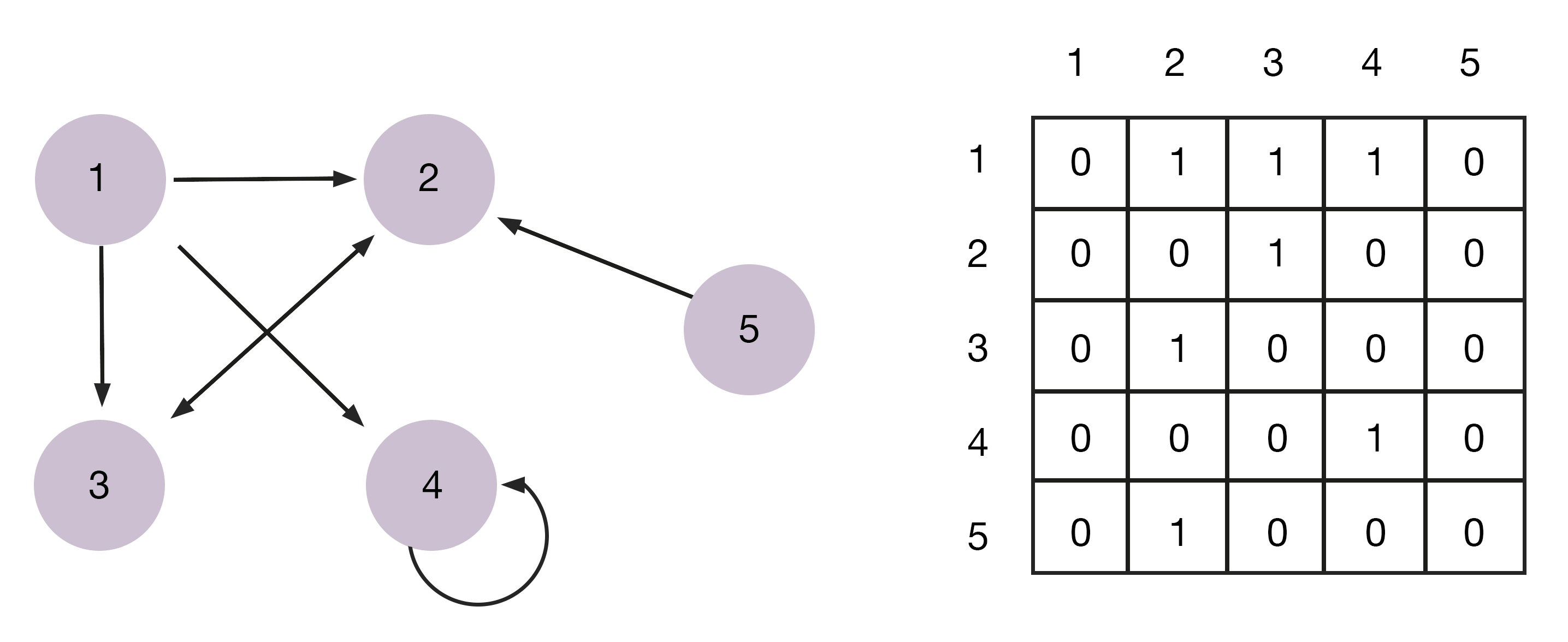
Матриця — двовимірний масив, що виглядає як список стовпців і рядків, на перетині яких знаходяться елементи даних. Це прямокутний масив, у якому кількість рядків та стовпців задає його розмір. У математиці їх використовують для компактного запису лінійних рівнянь алгебри або диференціальних рівнянь.
Матриці використовують для опису ймовірностей. Наприклад, для ранжування сторінок у пошуку Google за допомогою алгоритму PageRank. У комп’ютерній графіці — для роботи з 3D-моделями та проєктування їх на двовимірний екран.
#3. Зв’язковий список (Linked list)
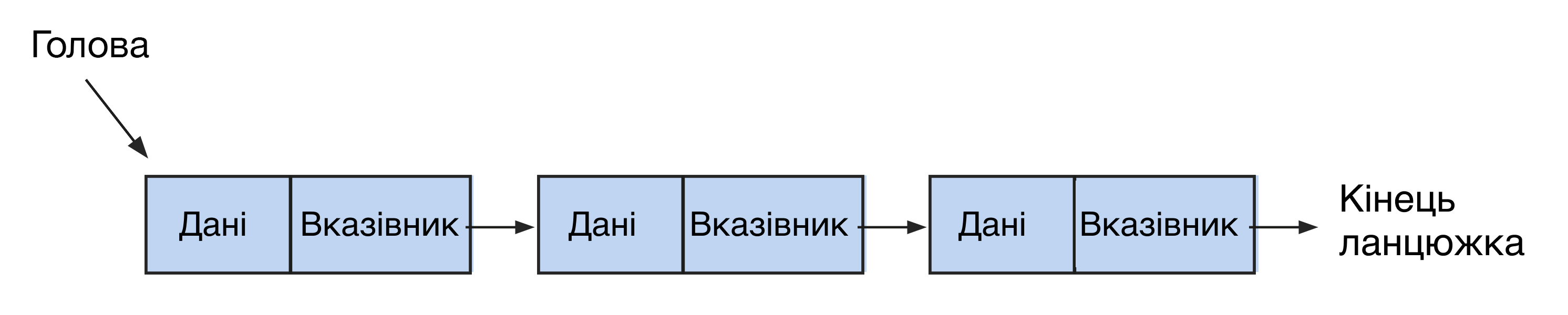
Списки схожі з масивами, але відрізняються гнучкішою структурою. Вони виглядають як ланцюжки нод або вузлів, де кожна нода містить посилання на наступне. Доступ до елементів у зв’язкові списку здійснюється послідовно, на відміну від масивів із довільним доступом. Списки бувають однозв’язковими та двозв’язковими.
Початковий елемент цієї структури називається головою, а наступні вузли ланцюжка — хвостом. Хвіст складається з елементів двох типів: з інформацією (info) та із зазначенням на наступний вузол (next). Кінець ланцюжка позначається як null.
#4. Стек (Stack)
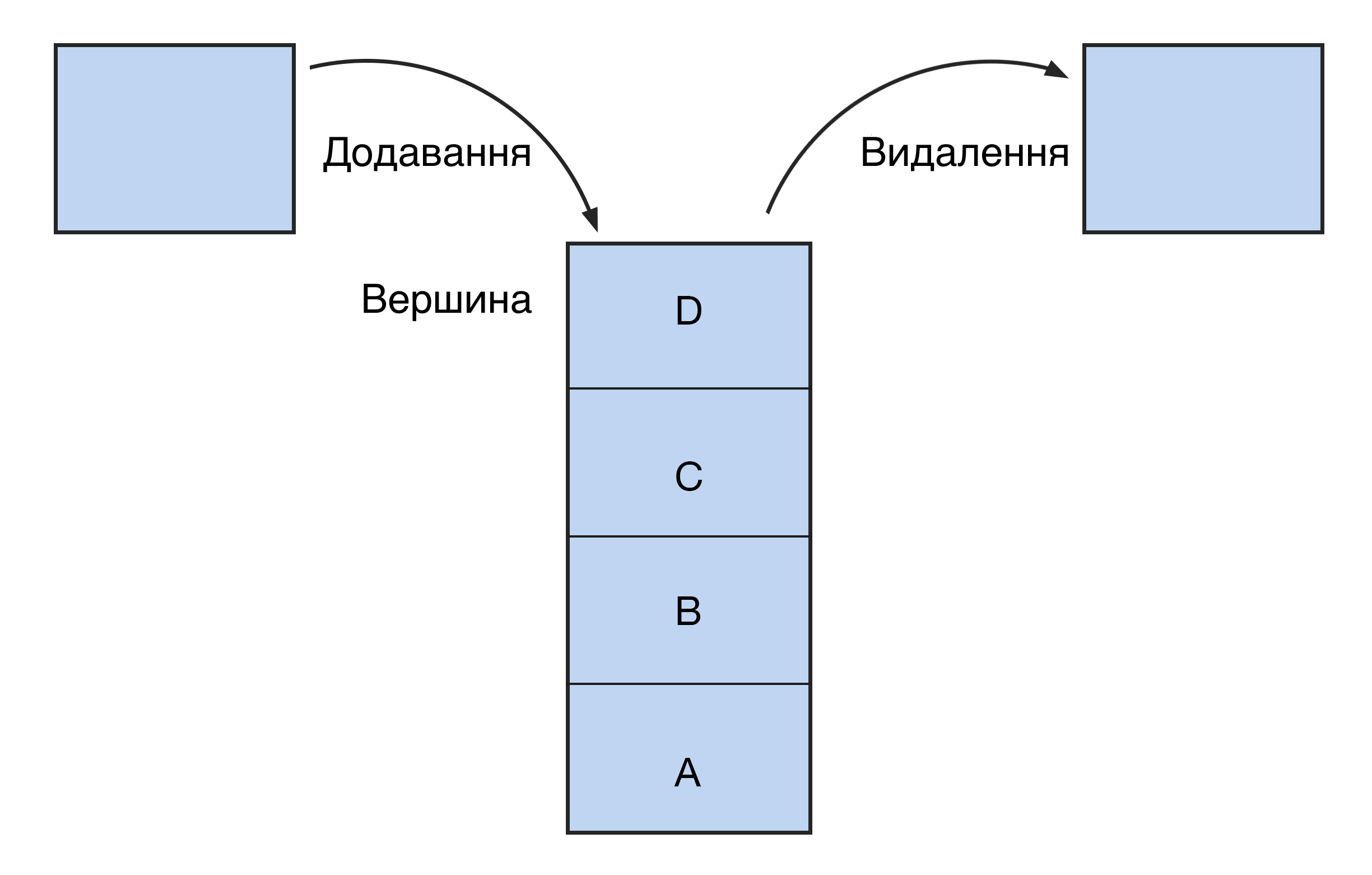
Це вертикальний стовпець із блоками, доступ до яких можна отримати лише з одного кінця: згори чи знизу. Як у стосі книг — щоби дістатися до нижньої, потрібно спочатку забрати всі книги зверху.
Нові елементи стека замінюють старі. Принцип роботи такої структури — LIFO (last in — first out, «останнім прийшов — першим пішов»). Тому стек ще називають магазином — за аналогією з вогнепальною зброєю: вистрілить патрон, який був заряджений останнім.
Ця структура даних реалізована у функції «скасувати» (undo). Програма зберігає статус роботи так, що остання дія стає першою в черзі на скасування. У стеку можливі лише три операції: додавання елемента (push), видалення (pop), читання (peek).
Стек може бути реалізований у вигляді зв’язкового списку або одновимірного масиву. У першому випадку кожен елемент містить посилання на наступний, у другому — впорядкований індексом.
Є схожа СД — дек (deque — double ended queue, «двостороння черга»). Це стек із двостороннім доступом.
#5. Черга (Queue)
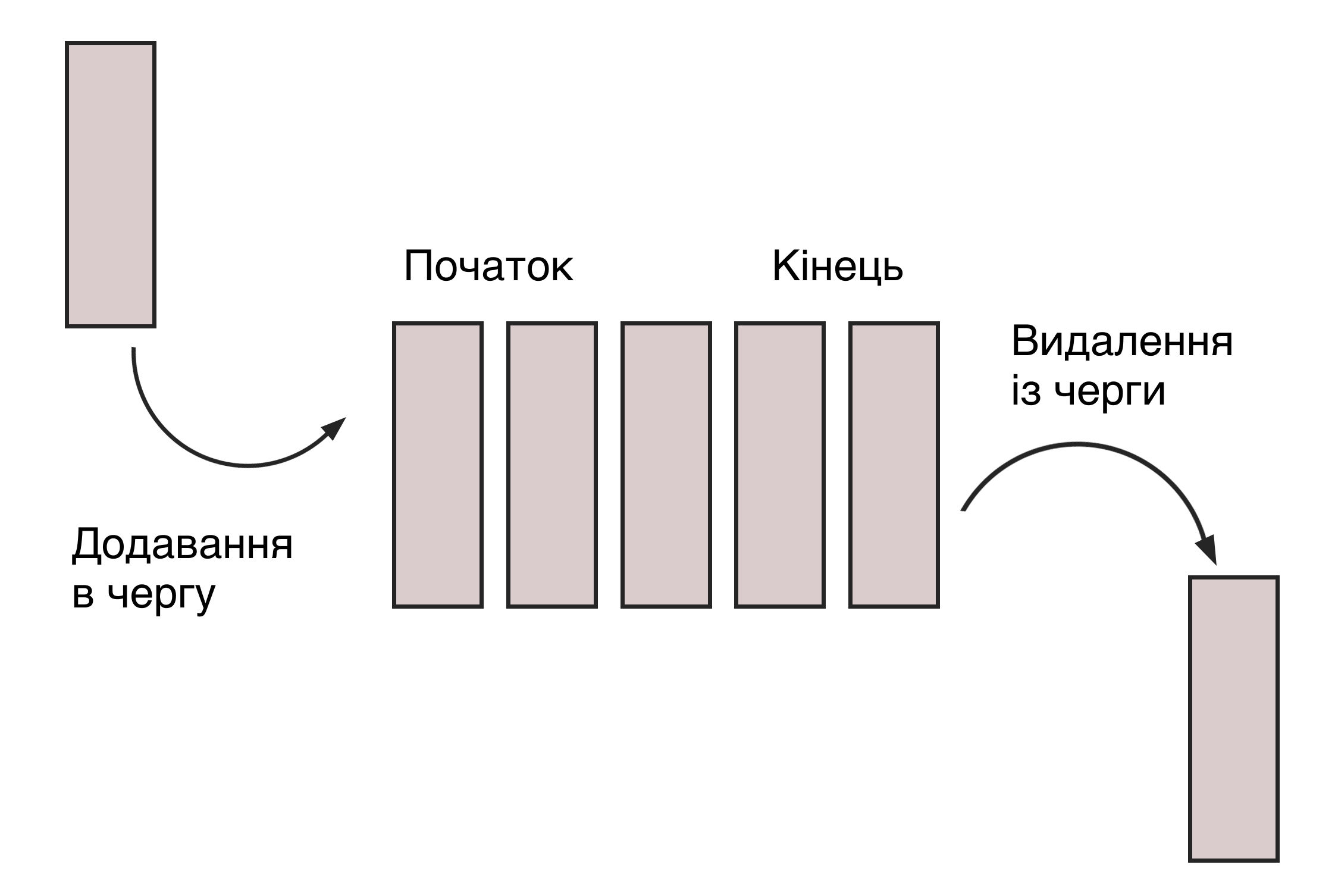
Цей тип СД нагадує стеки, але принцип роботи реалізований як FIFO (first in — first out, «першим прийшов — першим пішов»). Як у супермаркеті: першим покупки забере додому той, хто найпершим займе чергу.
Черги використовуються, коли потрібно розподілити ресурс між кількома споживачами (робота ЦП, пропускна спроможність роутера). Або коли дані передаються асинхронно, тобто швидкості приймання та віддачі — різні.
У цій СД можна виконати дві операції: додавання елемента до кінця черги (enqueue) і видалення першого елемента (dequeue). Черги бувають у вигляді зв’язкових списків чи масивів, аналогічно зі стеками.
#6. Дерево (Tree)
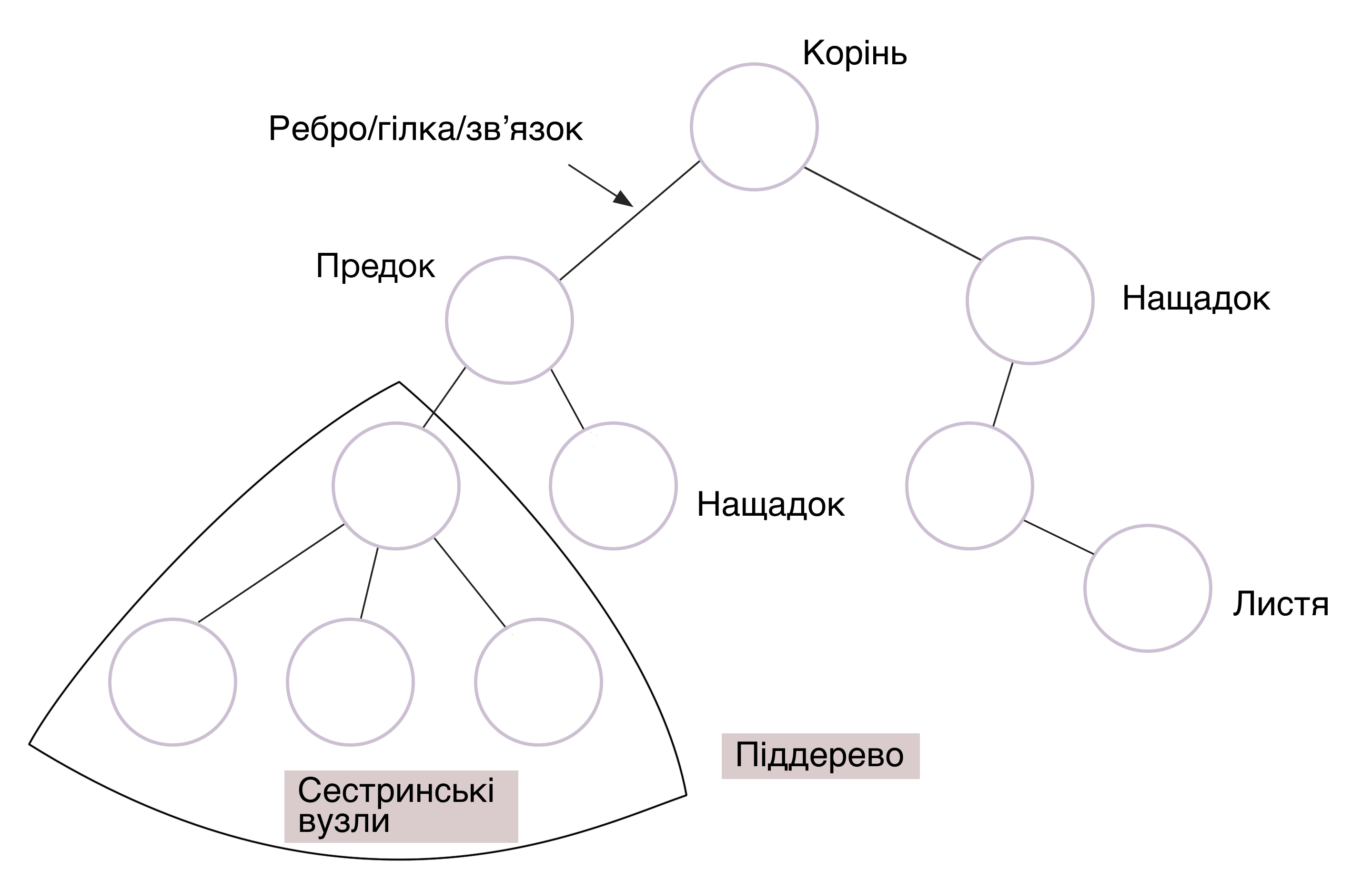
Дерева — структура, у якій дані пов’язані між собою вузлами, і навіть розташовані ієрархічно. Розрізняють двійкове дерево пошуку, розширене, чорно-червоне та ще десяток видів.
Як і в справжнього дерева, тут є коріння, гілки та листя. Найвищий вузол у цій СД, що не має предків, називається кореневим. Інші вузли — нащадками чи дочірніми елементами. Дочірні вузли з тим самим батьком — це вузли-брати. А листя — це вузли, які не мають нащадків.
Дерева використовують, наприклад, для розробки відеоігор. Вони дають змогу розділити простір та швидко знаходити об’єкти. Так, дерево з чотирма дочірніми вузлами (quadtree) — квадрант — використовується для створення карти та орієнтації за чотирма сторонами світу в грі.
Але дерева складно зберігати і вони мають невисоку швидкість роботи.


#7. Купа (Heap)
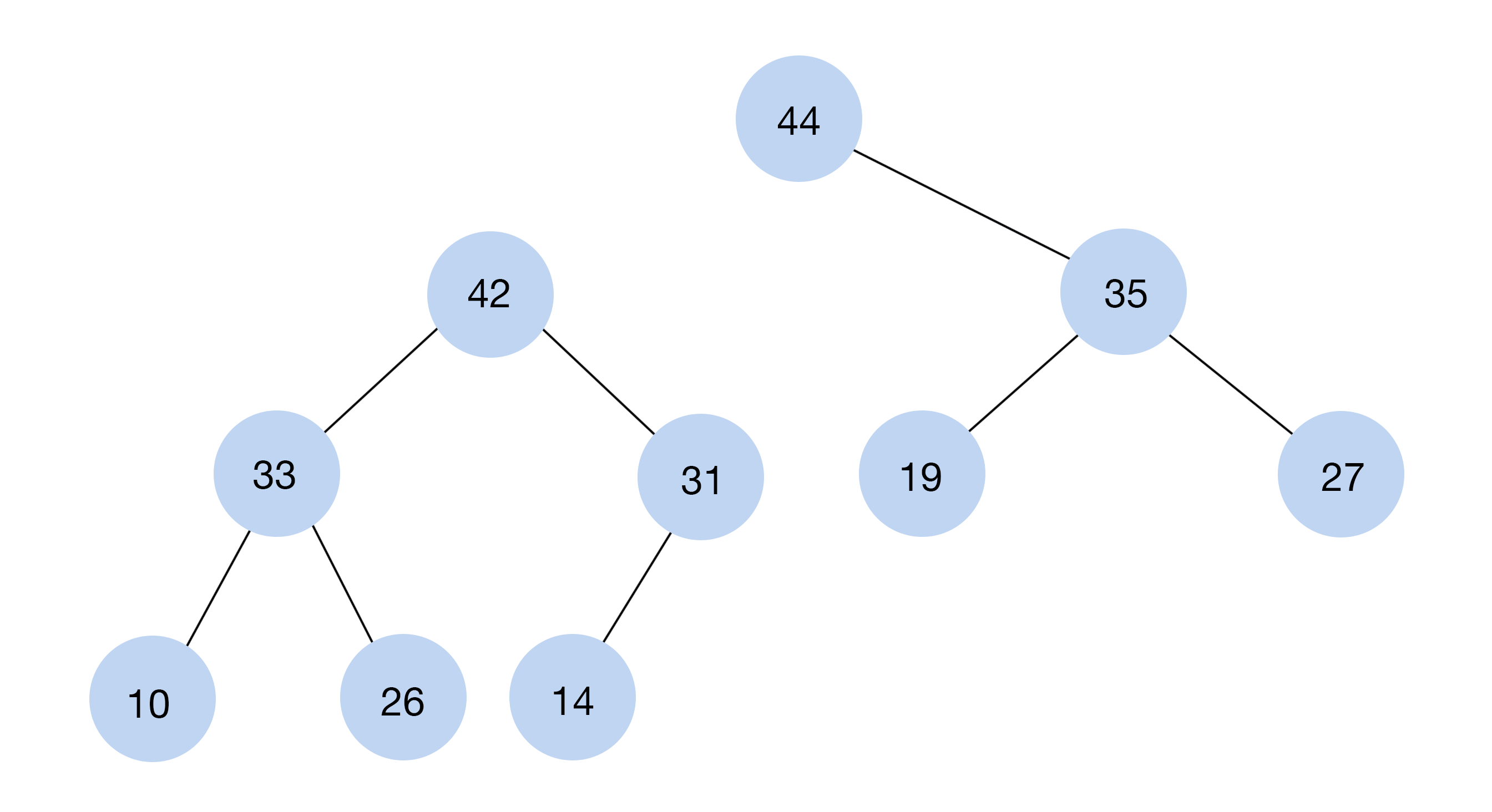
Купи — майже те саме, що й дерева: вони також мають кореневі та дочірні вузли. Відрізняється система ієрархії: купи бувають двох видів — ті, де значення кореневих вузлів менші й ті, де значення більші, ніж у дочірніх. Ці СД можна зберігати в простому або динамічному масиві, тобто вони займають набагато менше місця, ніж дерева.
Щоби додати новий елемент до купи, потрібно переглянути всі інші. Елементи розташовані за спаданням — від великих до маленьких.
Купи використовують для сортування об’єктів або реалізації черг із пріоритетом.
#8. Префіксне дерево (Prefix tree)
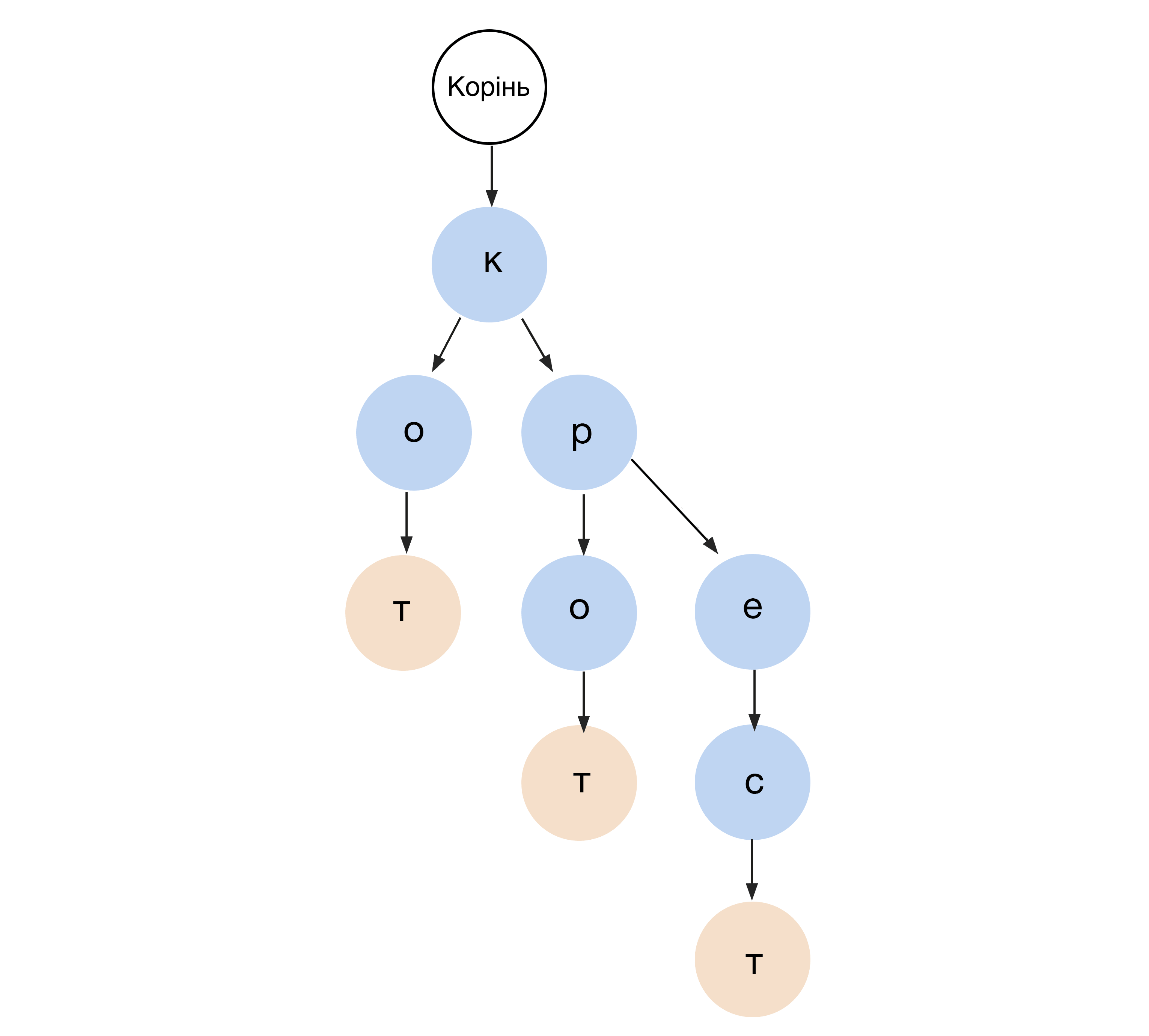
Коли ми користуємося автозаповненням, спрацьовує структура даних, яка називається префіксним деревом. Це один із видів дерева пошуку, який застосовується, наприклад, для зберігання слів та швидкого пошуку за ними. Вузли в цьому дереві називаються мітками. Кожна мітка містить одну літеру, пошук іде послідовно за мітками. Коли порядок літер починає відрізнятися, дерево розгалужується. Уявіть, як смартфон пропонує слово, коли ми надрукували кілька літер.
Префіксне дерево використовують у NLP і для синтаксичного аналізу природних мов.


#9. Хеш-таблиця (Hash table)
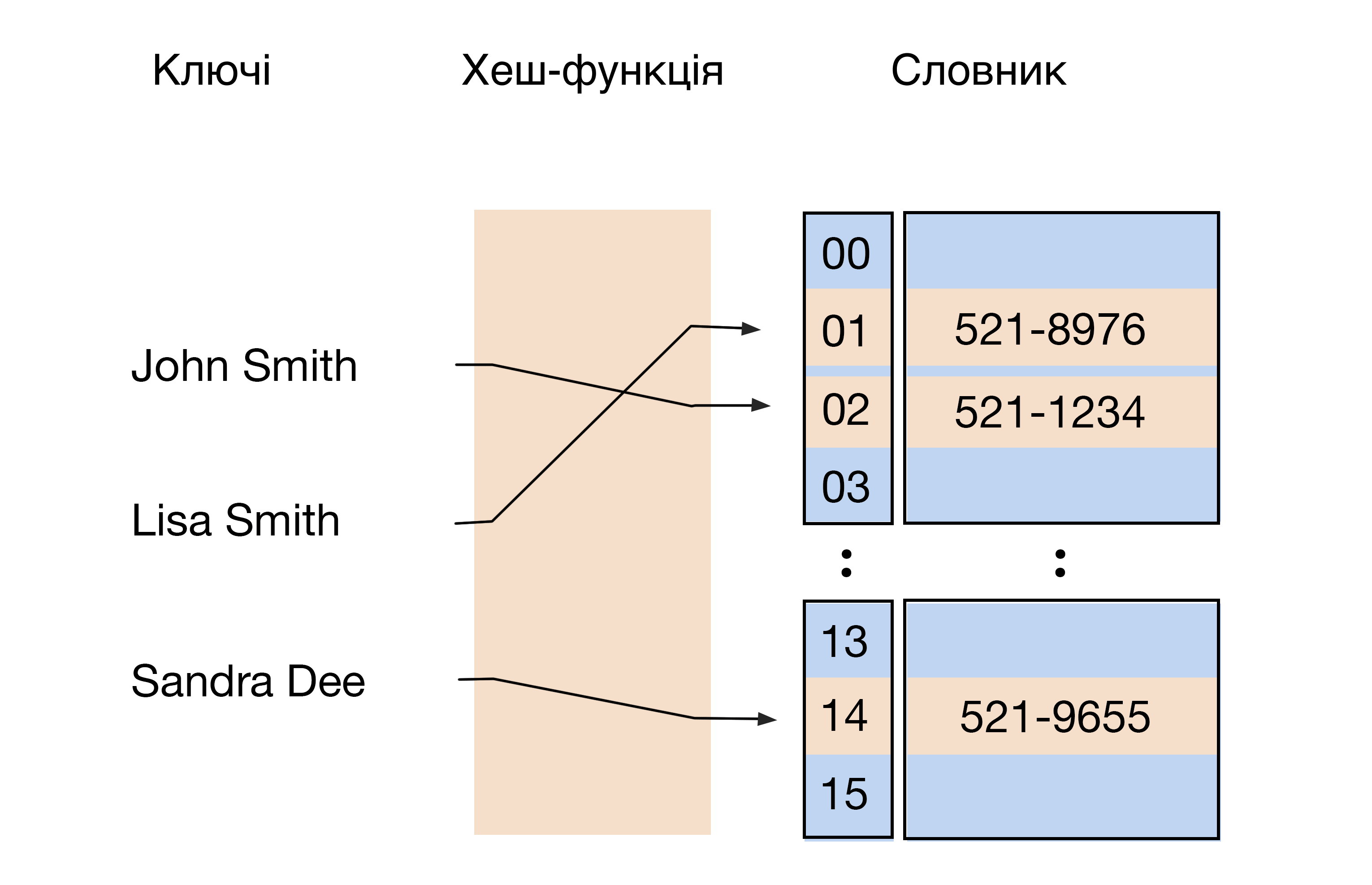
Хеш-таблиця — це СД, у якій зберігаються значення та пов’язані з ними ключі. Уявіть велику бібліотеку. Зазвичай для пошуку книги там потрібний довідник. Але можна використовувати алгоритм хешування, тоді функція відразу видасть номер шафи та розташування книги в ньому. Це відбувається завдяки ключам. Вони містять інформацію для доступу до файлу та його розташування. Хешування використовують у криптографії для шифрування інформації.
Хеш-функція скорочує довгий рядок символів до короткого значення. Це й буде ключем чи індексом елемента даних у хеш-таблиці. Набір даних називається словником.
Продуктивність хеш-таблиці залежить від функції хешування, розміру таблиці та методу обробки колізій.
За матеріалами GeeksforGeeks, freeCodeCamp, Towards Data Science, а також дослідженням Альфреда Ахо, Джона Хопкрофта та Джеффрі Ульмана.


