
9 структур данных, которые вам понадобятся
Матрица, массив, стек и другие.
Структуры данных — способы хранения и извлечения информации. Правильный выбор структуры поможет эффективнее выполнить задачу. СД важны в разработке ПО, от них зависит, как будут работать алгоритмы.
Рассказываем о структурах данных, которые используются чаще всего.
#1. Массив (Array)
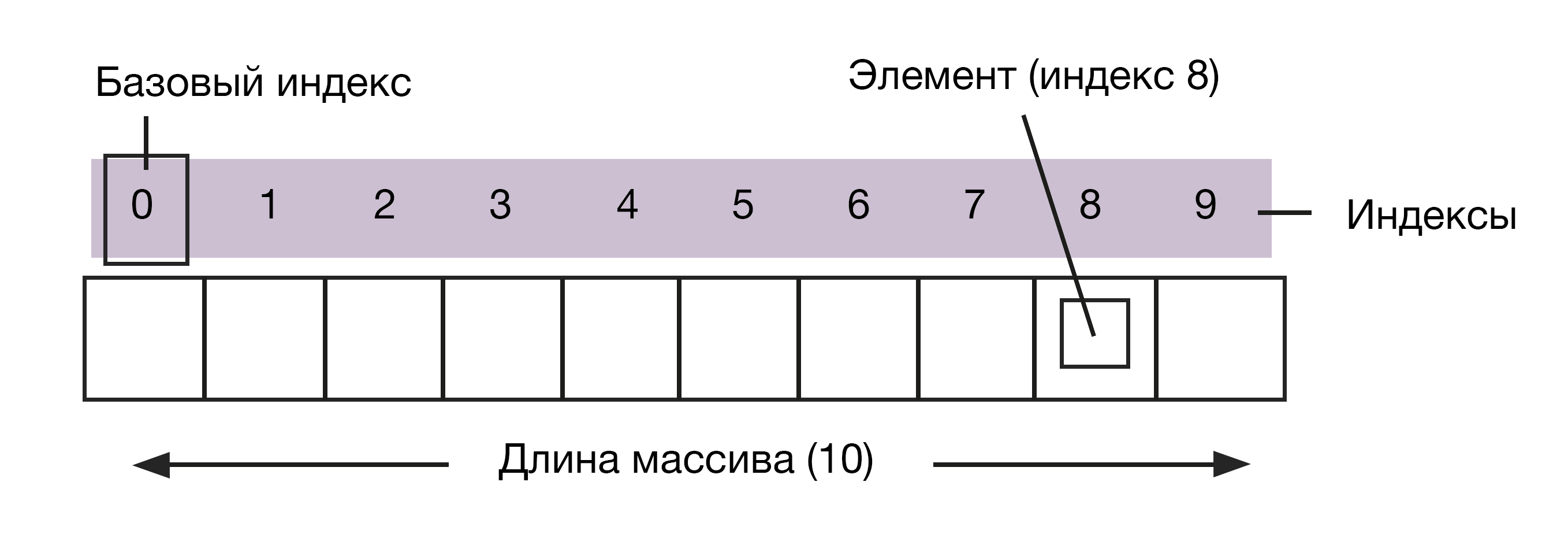
Массив — простая базовая структура. Стеки, очереди и списки — производные от массивов. Единице данных в массиве присваивается число или индекс, который указывает на ее расположение. Чтобы найти ячейку с информацией в массиве, нужно добавить к базовому элементу ее индекс. Базовый элемент, как правило, обозначается именем самого массива.
Представьте себе записную книжку со страницами, пронумерованными от 1 до 10. Каждая из них может содержать информацию или быть пустой. Блокнот — массив страниц, страницы — элементы массива «блокнот». Программно вы извлекаете информацию со страницы, обращаясь к ее индексу, то есть «блокнот+4» будет ссылаться на содержимое четвертой страницы.
Массив — это фиксированная структура, хранящая элементы одного типа в непрерывных ячейках памяти. Есть исключение — гетерогенные массивы, которые могут хранить данные разных типов. Массивы бывают одномерными и многомерными (массивы в массивах). Их размеры фиксированы, поэтому в уже созданный массив нельзя просто вставить новый элемент. Нужно скопировать старый массив и создать новый, увеличив размер.
#2. Матрица (Matrix)
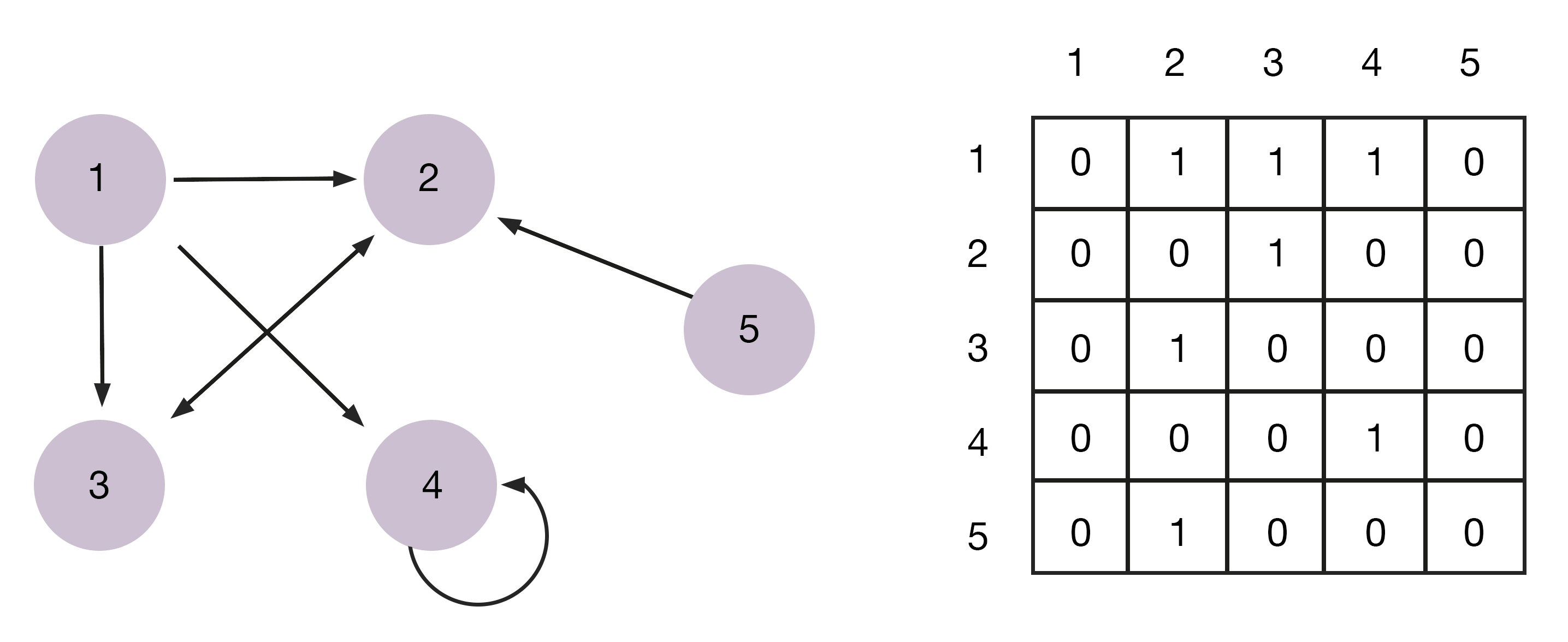
Матрица — двумерный массив, выглядящий как список столбцов и строк, на пересечении которых находятся элементы данных. Это прямоугольный массив, в котором количество строк и столбцов задает его размер. В математике их используют для компактной записи линейных алгебраических или дифференциальных уравнений.
Матрицы используют для описания вероятностей. Например, для ранжирования страниц в поиске Google при помощи алгоритма PageRank. В компьютерной графике — для работы с 3D-моделями и проецирования их на двумерный экран.
#3. Связный список (Linked list)
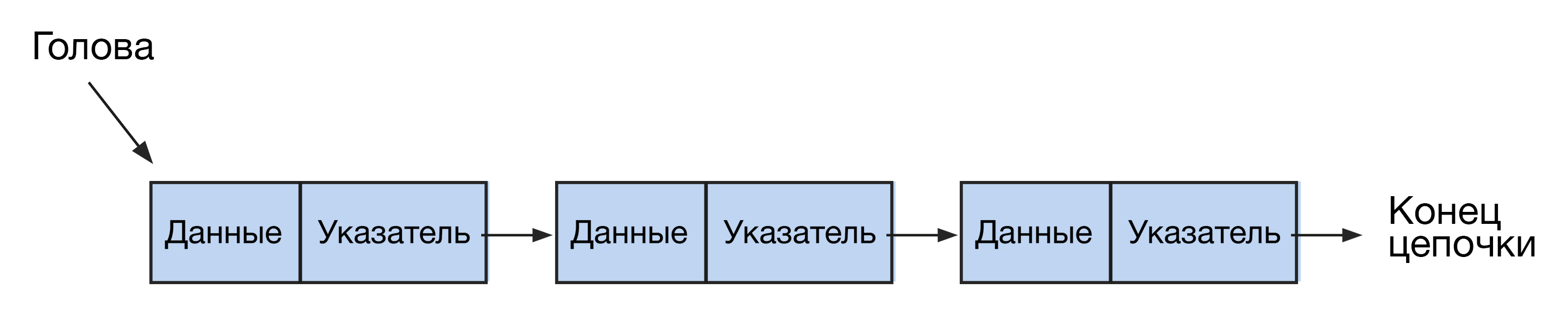
Списки схожи с массивами, но отличаются более гибкой структурой. Они выглядят как цепочки нод или узлов, где каждая нода содержит ссылку на следующую. Доступ к элементам в связном списке осуществляется последовательно, в отличие от массивов с произвольным доступом. Списки бывают односвязными и двусвязными.
Начальный элемент этой структуры называется головой, а все последующие узлы цепочки — хвостом. Хвост состоит из элементов двух типов: с информацией (info) и с указанием на следующий узел (next). Конец цепочки обозначается как null.
#4. Стек (Stack)
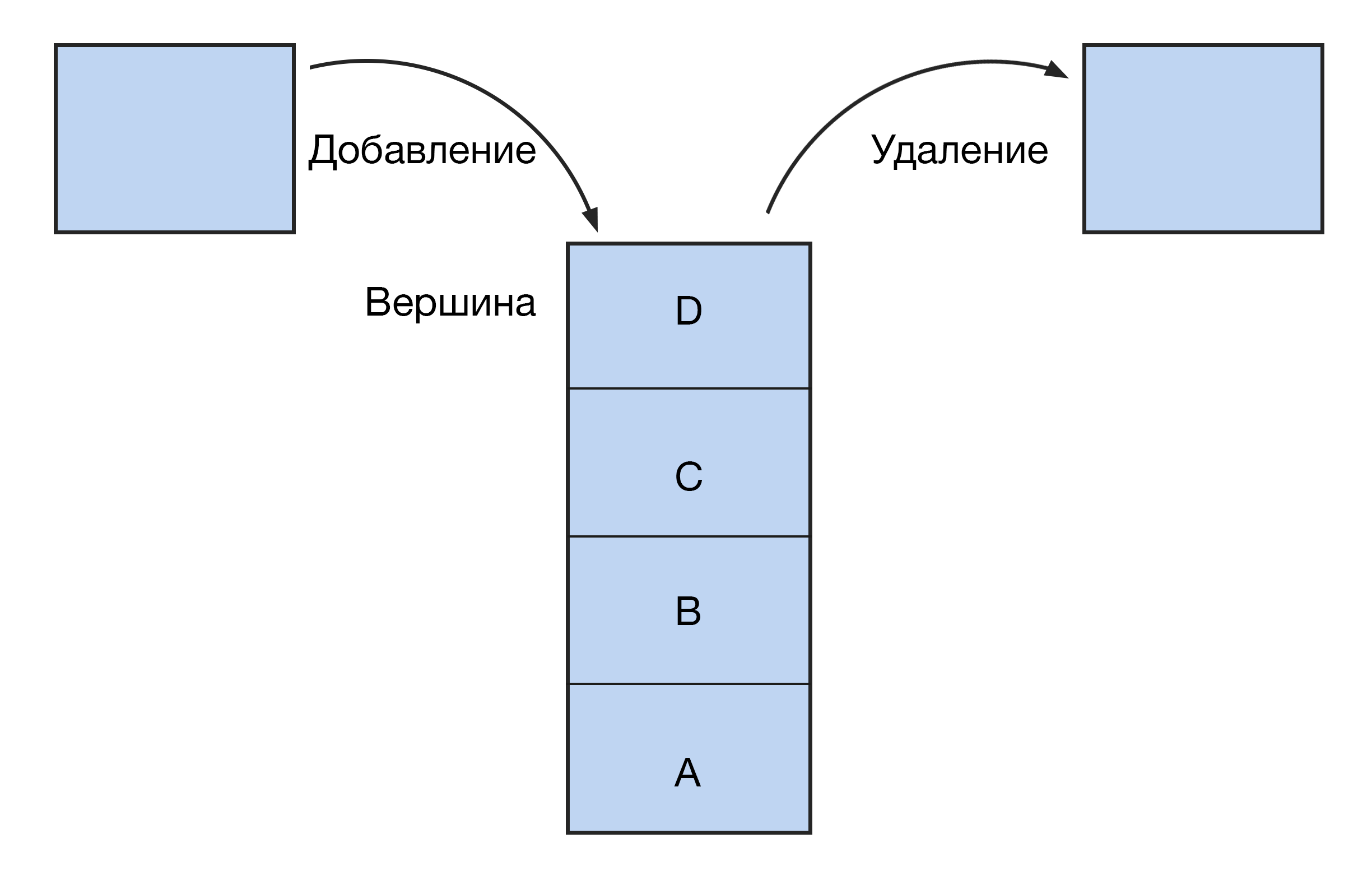
Это вертикальный столбец с блоками, доступ к которым можно получить только с одного конца: сверху или снизу. Как в стопке книг — чтобы добраться до нижней, нужно сначала убрать все книги сверху.
Новые элементы стека заменяют старые. Принцип работы такой структуры — LIFO (last in — first out, «последним пришел — первым ушел»). Поэтому стек еще называют магазином — по аналогии с огнестрельным оружием: выстрелит патрон, который был заряжен последним.
Эта структура данных реализована в функции «отменить» (undo). Программа сохраняет статус работы так, что последнее действие становится первым в очереди на отмену. В стеке возможны всего три операции: добавление элемента (push), удаление (pop), чтение (peek).
Стек может быть реализован в виде связного списка или одномерного массива. В первом случае, каждый элемент содержит ссылку на следующий, во втором — упорядочен индексом.
Существует похожая СД — дек (deque — double ended queue, «двусторонняя очередь»). Это стек с двусторонним доступом.
#5. Очередь (Queue)
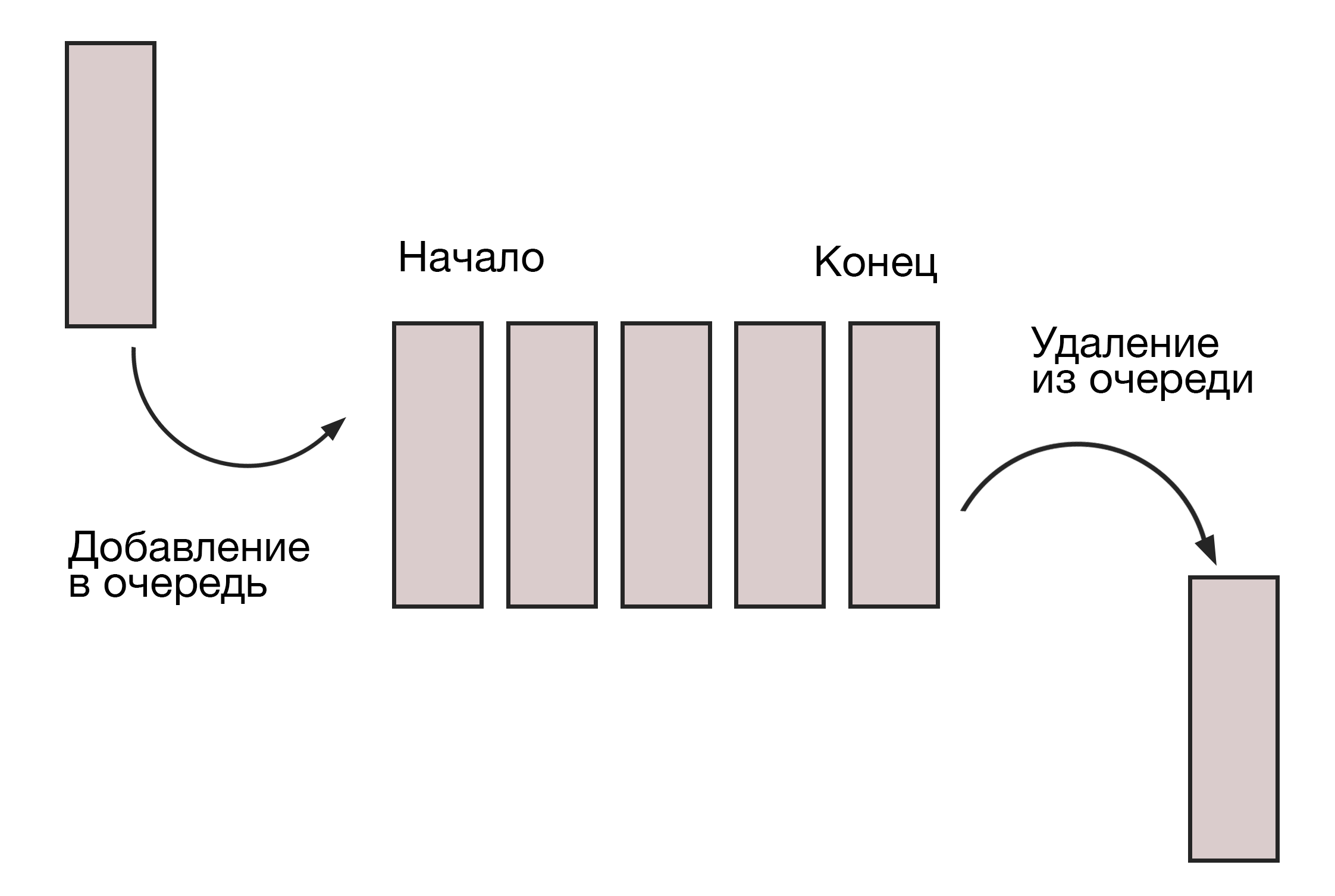
Этот тип СД напоминает стеки, но принцип работы реализован как FIFO (first in — first out, «первым пришел — первым ушел»). Как в супермаркете: первым покупки унесет домой тот, кто раньше всех займет очередь.
Очереди используются, когда ресурс нужно распределить между несколькими потребителями (работа ЦП, пропускная способность роутера). Или когда данные передаются асинхронно, то есть скорости приема и отдачи — разные.
В этой СД можно выполнить две операции: добавление элемента в конец очереди (enqueue) и удаление первого элемента (dequeue). Очереди бывают в виде связных списков или массивов, по аналогии со стеками.
#6. Дерево (Tree)
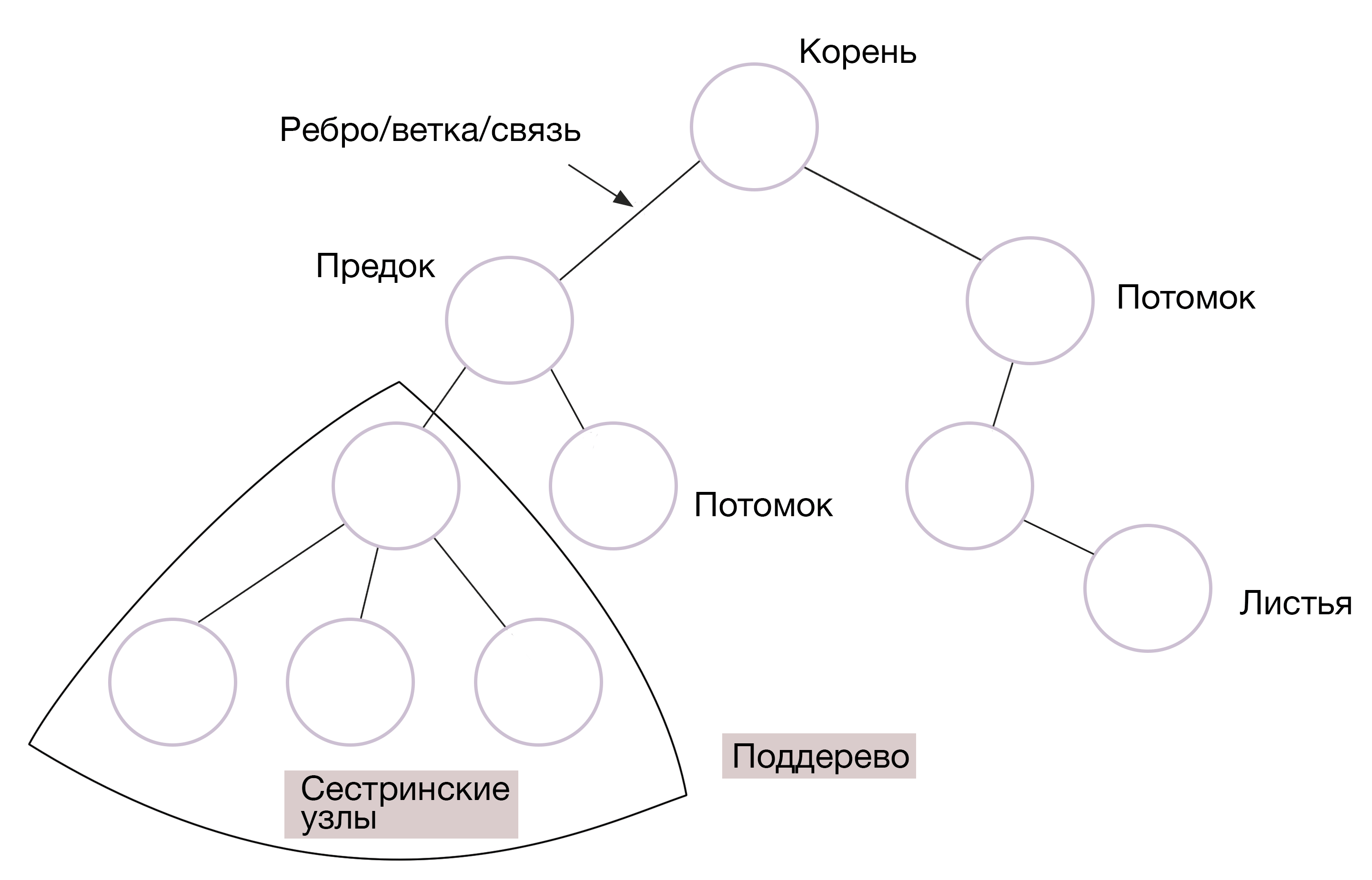
Деревья — структура, в которой данные связаны между собой узлами, и при этом расположены иерархически. Различают двоичное дерево поиска, расширенное, черно-красное и еще десяток видов.
Как и у настоящего дерева, тут есть корни, ветви и листья. Самый верхний узел в этой СД, не имеющий предков, называется корневым. Остальные узлы — потомками или дочерними элементами. Дочерние узлы с одним и тем же родителем — это узлы-братья. А листья — это узлы, не имеющие потомков.
Деревья используют, например, в разработке видеоигр. Они позволяют разделить пространство и быстро находить объекты. Так, дерево с четырьмя дочерними узлами (quadtree) — квадрант — используется для создания карты и ориентации по четырем сторонам света в игре.
Но деревья сложно хранить и у них невысокая скорость работы.


#7. Куча (Heap)
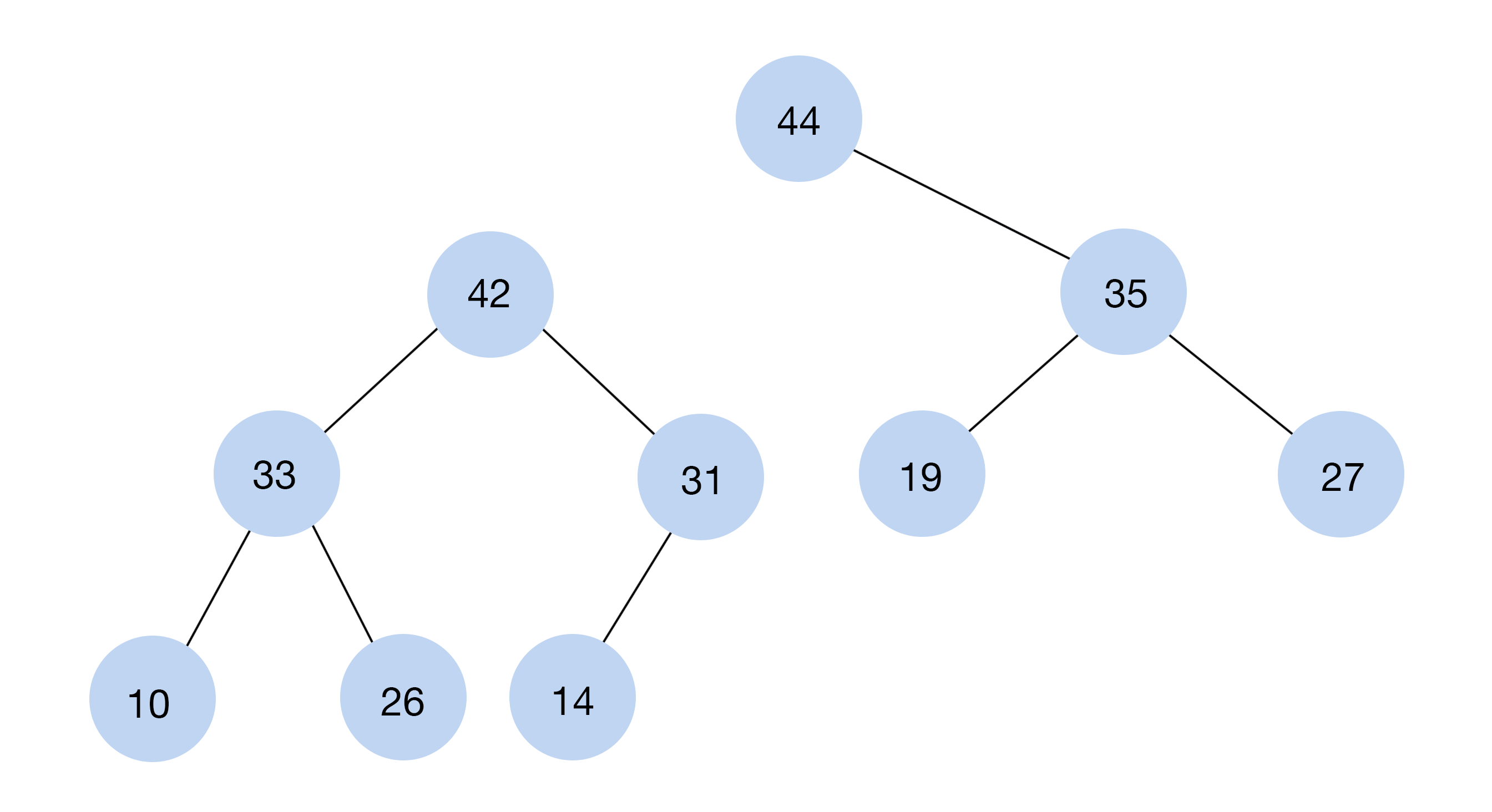
Кучи — почти то же самое, что и деревья: у них также есть корневые и дочерние узлы. Отличается система иерархии: кучи бывают двух видов — те, где значения корневых узлов меньше и те, где значения больше, чем у дочерних. Эти СД можно хранить в простом или динамическом массиве, то есть они занимают гораздо меньше места, чем деревья.
Чтобы добавить новый элемент в кучу, нужно пересмотреть все остальные. Элементы расположены по убыванию — от больших к маленьким.
Кучи используют для сортировки объектов или реализации очередей с приоритетом.
#8. Префиксное дерево (Prefix tree)
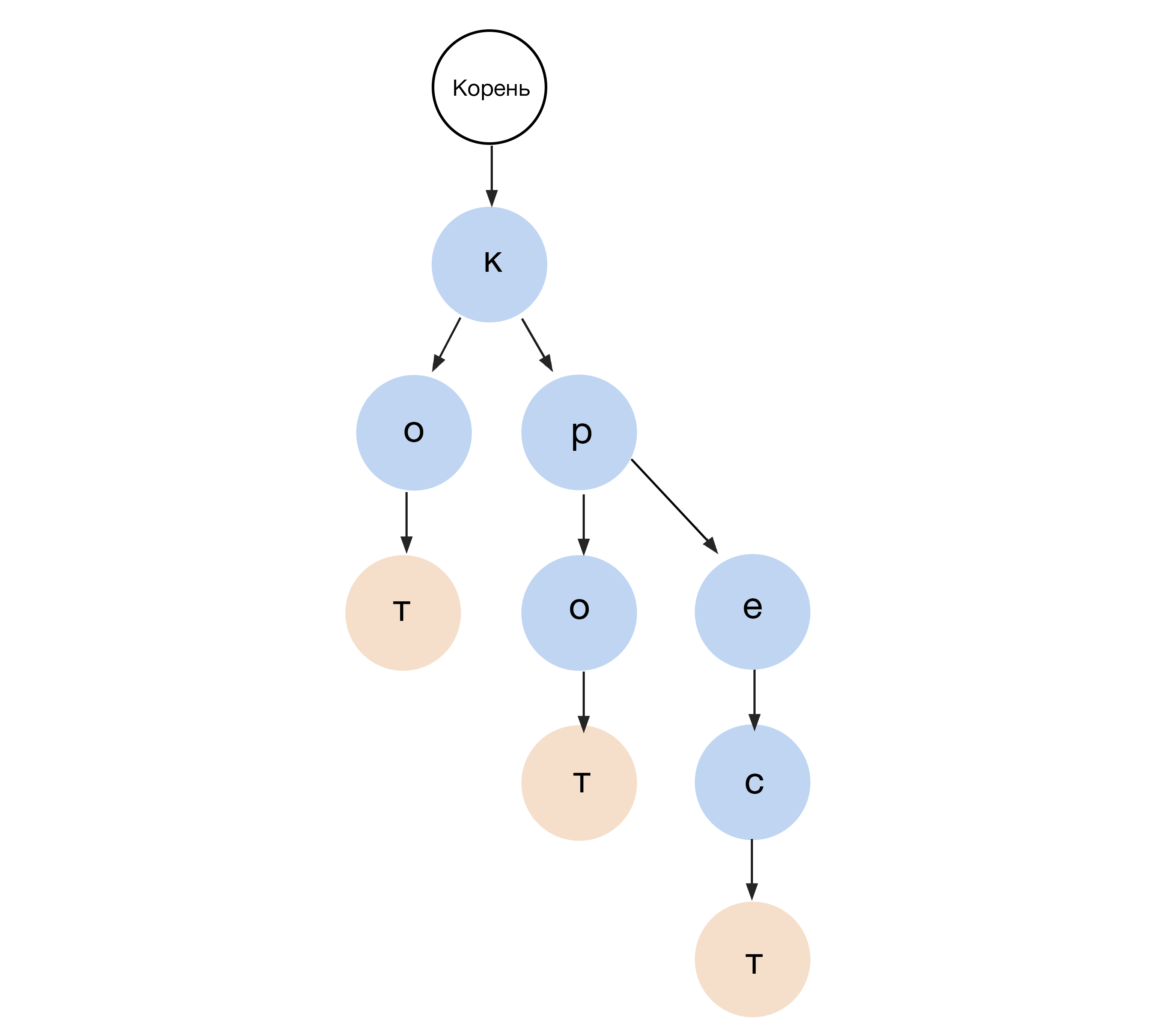
Когда мы пользуемся автозаполнением, срабатывает структура данных, которая называется префиксным деревом. Это один из видов дерева поиска, который применяется, например, для хранения слов и быстрого поиска по ним. Узлы в этом дереве называются метками. Каждая метка содержит одну букву, поиск идет последовательно по меткам. Когда порядок букв начинает отличаться, дерево ветвится. Представьте, как смартфон предлагает целое слово, когда мы напечатали несколько букв.
Префиксное дерево используют в NLP и для синтаксического анализа естественных языков.


#9. Хеш-таблица (Hash table)
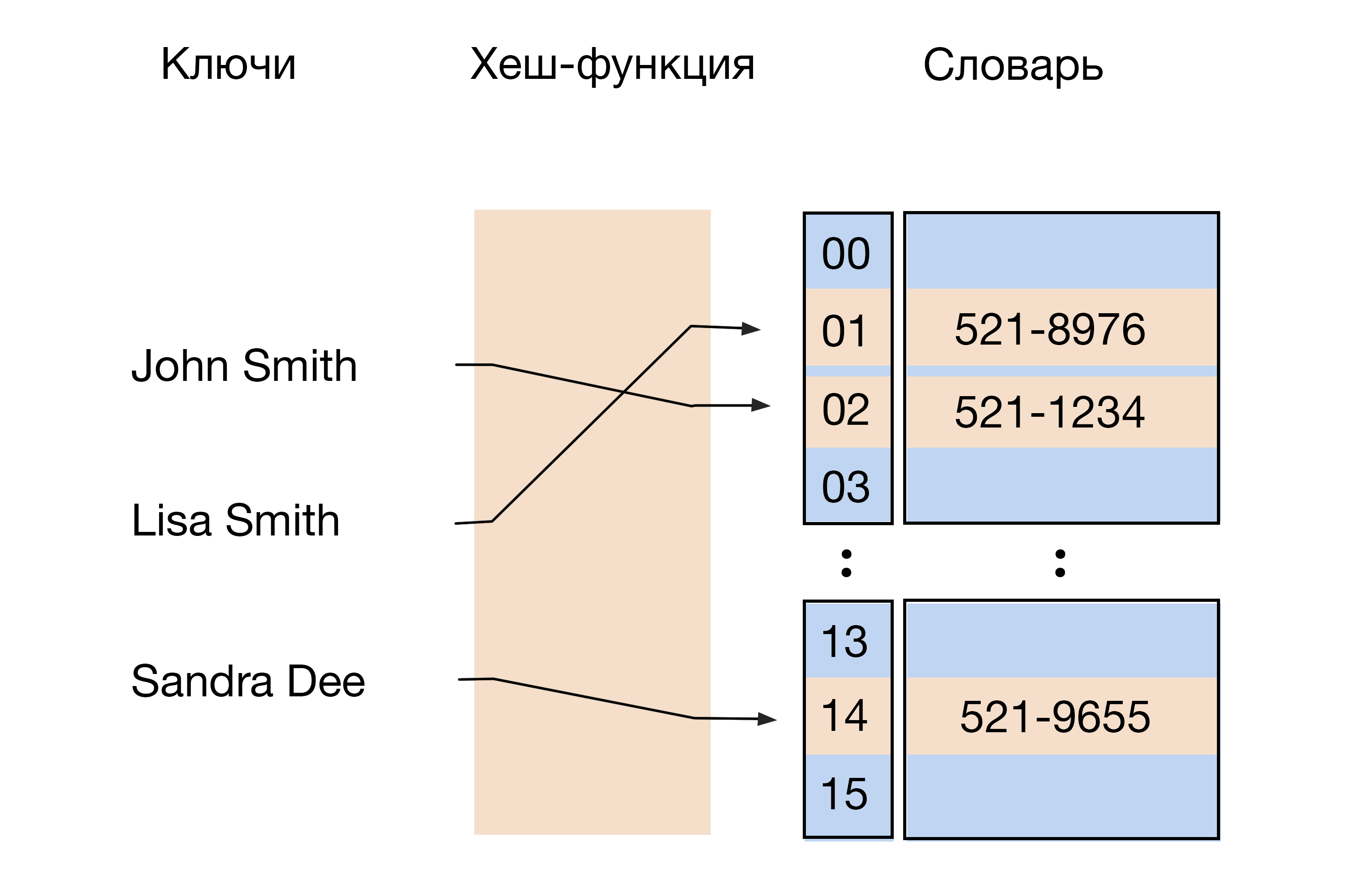
Хеш-таблица — это СД, в которой хранятся значения и связанные с ними ключи. Представьте большую библиотеку. Обычно для поиска книги там нужен справочник. Но можно использовать алгоритм хеширования, тогда функция сразу выдаст номер шкафа и расположение книги в нем. Это происходит благодаря ключам. Они содержат информацию для доступа к файлу и о его расположении. Хеширование используют в криптографии для шифрования информации.
Хеш-функция сокращает длинную строку символов до короткого значения. Это и будет ключом или индексом элемента данных в хеш-таблице. Набор данных в ней называется словарем.
Производительность хеш-таблицы зависит от функции хеширования, размера таблицы и метода обработки коллизий.
По материалам GeeksforGeeks, freeCodeCamp, Towards Data Science, а также исследованиям Альфреда Ахо, Джона Хопкрофта и Джеффри Ульмана.

