
Розгортання застосунку на Ubuntu: налаштовуємо кластер Kubernetes
Поетапна інструкція від robot_dreams
Сьогодні ми продовжимо говорити про Kubernetes і розглянемо ключові кроки, потрібні для успішного налаштування кластера — від встановлення обов'язкових компонентів до розгортання застосунків на Ubuntu.
Вибір платформи для розгортання
Перший етап під час налаштування кластера Kubernetes — вибір відповідної платформи для розгортання. Залежно від ваших потреб та доступних ресурсів, ви можете зупинити свій вибір на одному з хмарних провайдерів, як-от Amazon Web Services (AWS), Google Cloud Platform (GCP) чи Microsoft Azure, або використовувати власне фізичне обладнання.
Хмарні провайдери мають низку переваг (порівняно з розгортанням власної інфраструктури). З переваг «хмари» можна відзначити:
- гнучкість;
- масштабованість;
- зручність керування.
Наприклад, AWS надає сервіс Elastic Kubernetes Service (EKS), GCP пропонує Google Kubernetes Engine (GKE), а Azure — Azure Kubernetes Service (AKS). Ці сервіси спрощують розгортання, керування та масштабування кластерів Kubernetes, надаючи інструменти для автоматизації низки рутинних завдань.
Так, на AWS EKS замість налаштування серверів та керування операційною системою ви просто створюєте кластер через консоль керування або API. EKS займається автоматичним оновленням кластера, забезпечуючи безпеку та оновлення патчів. AWS EKS виконує автоматичні оновлення Kubernetes, дозволяючи залишатися на актуальній версії. Також EKS контролює процес оновлення майстер-нод, заощаджуючи час, що витрачається на управління апдейтами.
У роботі зручно використовувати інтеграцію EKS з іншими сервісами AWS, як-от AWS Identity and Access Management (IAM), Amazon VPC, Amazon CloudWatch тощо. Це дає змогу автоматизувати доступ, моніторинг та налаштування параметрів мережі.
Водночас хмарні провайдери годяться не для всіх сценаріїв. Наприклад, якщо ви маєте справу зі складною мережевою архітектурою, хмарний провайдер може не надавати гнучких інструментів для налагодження мережевих налаштувань, що обмежить вашу здатність керувати трафіком і контролювати безпеку.
Налаштування кластера Kubernetes
Підготовка до розгортання кластера на Ubuntu
Під час налаштування кластера Kubernetes потрібно встановити різні компоненти, як-от kube-apiserver, kube-controller-manager, kube-scheduler, etcd та інші, на керівних (Master) та робочих (Worker) вузлах.
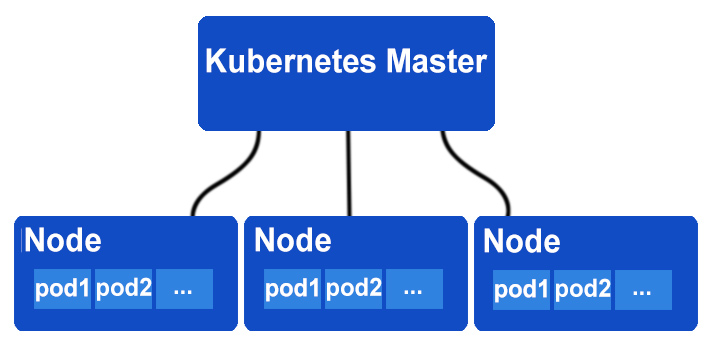
Архітектура Kubernetes
Цей процес може бути складним, і для полегшення його проведення розроблено різні інструменти встановлення та керування кластером Kubernetes. Наприклад, можна виділити такі:
- kubeadm — спрощує процес встановлення та налаштування кластера Kubernetes на звичайних віртуальних машинах або фізичних серверах. Він надає команди для встановлення та налаштування компонентів кластера, а також автоматично генерує конфігураційні файли.
- kops — використовують для розгортання та керування кластерами Kubernetes у хмарних провайдерах, як-от AWS. Він автоматизує створення та налаштування потрібних ресурсів, наприклад, віртуальних машин, мереж та сховищ, для розгортання кластера.
- Rancher — інструмент, який дає змогу керувати контейнерами, зокрема Kubernetes, на різних платформах, включно з хмарними провайдерами та власною інфраструктурою.
- minikube — Інструмент призначений для розробки та тестування локальних кластерів Kubernetes. Він дає змогу швидко створити мініатюрний кластер на вашій локальній машині для перевірки функціональності.
- k3s — легковажна реалізація Kubernetes, розроблена для встановлення на ресурсообмежених пристроях чи середовищах з обмеженими ресурсами.
Встановлення Docker
Оскільки Kubernetes використовує Docker для контейнеризації програм, насамперед встановлюємо Docker:
sudo apt update
sudo apt install docker.io
Встановлення kubeadm, kubelet і kubectl
Далі встановлюємо kubeadm, kubelet та kubectl:
sudo apt update
sudo apt install -y apt-transport-https curl
sudo curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
sudo echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt update
sudo apt install -y kubelet kubeadm kubectl
Скриншот термінала
Після встановлення kubelet потрібно налаштувати його для коректної роботи. Створіть файл /etc/default/kubelet (sudo nano /etc/default/kubelet) і додайте такий рядок:
KUBELET_EXTRA_ARGS=--cgroup-driver=cgroupfs
Збережіть зміни та перезапустіть kubelet:
sudo systemctl restart kubelet
Щоб переконатися, що файл створено, наберіть у терміналі:
cat /etc/default/kubelet
Якщо ви побачите вміст файлу, це означає, що файл /etc/default/kubelet існує і містить доданий вами рядок KUBELET_EXTRA_ARGS=--cgroup-driver=cgroupfs.
Перевірте версії встановлених компонентів:
kubectl get cs -A
Перевірка зв'язності хостів
- Перевірте зв'язок між хостами, щоб вузли вільно обмінювалися даними та взаємодіяли між собою.
- Переконайтеся, що брандмауери не мають блокування мережевого трафіку, що потрібні мережеві порти доступні (наприклад, чи відкрито порт для API-сервера Kubernetes — зазвичай 6443) і що налаштування мережі не фільтрують або блокують мережеві запити між вузлами.
- Переконайтеся, що DNS налаштований правильно, аби імена хостів могли дозволятися в IP-адреси. Це важливо для обміну даними між вузлами за іменами.
Нагадаємо, що в Linux є файл /etc/hosts, який виконує аналогічну функцію як файл C:\Windows\System32\drivers\etc\hosts на Windows.
Файл /etc/hosts на Linux використовується для перетворення імен хостів на IP-адреси без потреби використання DNS-серверів. Ви можете редагувати цей файл для додавання власних записів, які допоможуть прив'язувати імена хостів до IP-адрес у вашій локальній мережі. Це особливо корисно для забезпечення доступу між вузлами у локальних тестових чи розробницьких середовищах.
Загальний формат записів:
< IP-адреса > < ім'я хоста >
Наприклад:
192.168.1.100 master
192.168.1.101 worker1
192.168.1.102 worker2
...
Ініціалізація майстер-ноди
Підготуємо головну ноду (майстер-ноду), яка керуватиме всіма діями у кластері. Для ініціалізації майстер-ноди Kubernetes застосовують команда kubeadm init. Вона виконує такі ключові етапи:
- Установка компонентів майстер-ноди. Команда kubeadm init встановлює компоненти майстер-ноди, включно з API-сервером, контролерами, планувальником та іншими компонентами, які керують кластером.
- Генерація конфігурації. Після встановлення kubeadm генерує конфігураційні файли для kubeconfig і конфігурації компонентів. Ці файли використовуються kubectl для взаємодії з кластером.
- Створення токена приєднання. За успішної ініціалізації майстер-ноди генерується токен приєднання. Цей токен використовуватиметься для приєднання робочих нод до майстер-ноди.
- Створення конфігурації CNI. kubeadm також надає інформацію про те, який плагін CNI (Container Network Interface) використовувати і який драйвер мережі працюватиме в кластері.
Команда kubeadm init на майстер-ноді для ініціалізації кластера:
sudo kubeadm init --pod-network-cidr=192.168.0.0/16
Вираз --pod-network-cidr визначає діапазон IP-адрес для мережі контейнерів. Після успішного виконання цієї команди ви побачите висновок, у якому буде важлива інформація, включно з токеном для приєднання робочих нод. Приблизно такий:
...
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.100:6443 --token abcdef.1234567890abcdef \
--discovery-token-ca-cert-hash sha256:hash_value
Зверніть увагу на команду kubeadm join — Вона містить --token та --discovery-token-ca-cert-hash. Ці параметри надають робочим нодам автентифікаційний токен і хеш сертифіката CA для приєднання до майстер-ноди.
Після ініціалізації майстер-ноди приєднуємо до кластера робочі ноди. Для цього застосовують команду, яку було надано після успішного виконання kubeadm init на майстер-ноді. Ця команда охоплює токен і хеш сертифіката CA.
Наприклад, для приєднання кластера на робочій ноді можна виконати команду:
sudo kubeadm join 192.168.1.100:6443 --token
abcdef.1234567890abcdef \
--discovery-token-ca-cert-hash sha256:hash_value
Потрібно замінити 192.168.1.100 на IP-адресу вашої майстер-ноди та використовувати певні значення --token і --discovery-token-ca-cert-hash, які було надано вам після kubeadm init. Після успішного приєднання робочої ноди до кластера ви побачите таке:
This node has joined the cluster: *
Certificate signing request was sent to master and a response was
received. * The Kubelet was informed of the new secure connection
details. Run 'kubectl get nodes' on the master to see this node
join the cluster.
Цей висновок підтверджує, що робоча нода успішно приєдналася до кластера. Тепер ви можете виконати kubectl get nodes на майстер-ноді, щоб побачити нову робочу ноду у списку активних вузлів.
Виведення команди kubectl get nodes на майстер-ноді після успішного приєднання робочої ноди може мати такий вигляд:
NAME STATUS ROLES AGE VERSION
master-node Ready master 1d v1.21.2
worker-node1 Ready <none> 1h v1.21.2
worker-node2 Ready <none> 30m v1.21.2
Тут NAME — це імена вузлів, STATUS показує стан, ROLES вказує на роль (майстер, робітник тощо), значення AGE показує час роботи вузла, а VERSION показує версію Kubernetes на вузлі.
Робочі ноди (worker-node1 та worker-node2) мають статус Ready, що підтверджує успішне приєднання кластера.
Налаштування kubectl
Для керування кластером Kubernetes використовується kubectl (можна встановити окремо). За допомогою kubectl ви можете взаємодіяти з вашим кластером, керувати програмами, створювати та керувати ресурсами, виконувати налагодження та моніторинг тощо. Для успішної роботи з кластером через kubectl потрібно налаштувати конфігураційний файл ~/.kube/config, що пишеться у форматі YAML. Він містить інформацію про кластер, користувачів та контексти.
Контекстом називають набір параметрів, що визначає взаємодію з кластером Kubernetes; контексти дозволяють перемикатися між різними кластерами та користувачами без потреби повторного введення даних за кожної команди kubectl.
Якщо у вас ще немає файлу ~/.kube/config, ви можете створити його самостійно. Щоб додати інформацію про кластер у файл ~/.kube/config, у текстовому редакторі (наприклад, nano або vim) відкрийте файл:
nano ~/.kube/config
Потім додайте наступний блок конфігурації, замінивши значення server та certificate-authority на відповідні для вашого кластера:
apiVersion: v1
kind: Config
clusters:
- name: my-cluster-name
cluster:
server: https://your-cluster-server.com
certificate-authority: /path/to/ca.crt


Після збереження файлу ви отримуєте доданий кластер у конфігураційному файлі. У цей самий файл можна додати інформацію про користувачів та контексти:
apiVersion: v1
kind: Config
clusters:
- name: my-cluster-name
cluster:
server: https://your-cluster-server.com
certificate-authority: /path/to/ca.crt
users:
- name: my-user
user:
client-certificate: /path/to/user.crt
client-key: /path/to/user.key
contexts:
- name: my-context
context:
cluster: my-cluster-name
user: my-user
У наведеному виразі потрібно замінити /path/to/ca.crt, /path/to/user.crt та /path/to/user.key на шляху до відповідних сертифікатів та ключів.
Продовжимо налаштування kubectl та додавання додаткових кластерів, користувачів та контекстів до вашого конфігураційного файлу ~/.kube/config. Контекст поєднує кластер, користувача та назву контексту. Приклад додавання кластера користувача:
apiVersion: v1
kind: Config
current-context: my-k8s-cluster
clusters:
- name: my-k8s-cluster
cluster:
server: https://your-cluster-server.com
certificate-authority: /path/to/ca.crt
users:
- name: my-k8s-user
user:
client-certificate: /path/to/user.crt
client-key: /path/to/user.key
contexts:
- name: my-k8s-context
context:
cluster: my-k8s-cluster
user: my-k8s-user
Вибрати активний контекст, який використовуватиметься для kubectl, можна за допомогою команди kubectl config use-context.
Основні команди kubectl:
• kubectl get nodes — Отримання списку всіх вузлів у кластері.
• kubectl get pods — Отримання списку подів (запущених контейнерів) у кластері.
• kubectl get services — Отримання списку сервісів у кластері.
• kubectl create — Створення ресурсів (поди, послуги тощо).
• kubectl застосувати — Застосування файлів конфігурації для створення або оновлення ресурсів.
• kubectl delete — Видалення ресурсів.
• kubectl describe — Отримання детальної інформації про ресурс.
• kubectl logs — Отримання контейнерів логів.
• kubectl exec — Запуск команди всередині контейнер.
Приклади розгортання програм
Просте Hello world
Напишемо нескладний маніфест для розгортання Hello world у вигляді пода:
apiVersion: v1
kind: Pod
metadata:
name: hello-world-pod
spec:
containers:
- name: hello-world-container
image: busybox
command: ["echo", "Hello, World!"]
Зберігаємо його у вигляді hello-world-pod.yaml та застосовуємо командою:
kubectl apply -f hello-world-pod.yaml
Розгортання мікросервісної програми
Припустимо, у нас є два мікросервіси — frontend та backend. Створимо YAML-маніфести для кожної частини програми:
# frontend-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend-deployment
spec:
replicas: 2
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend-container
image: my-frontend-image:latest
ports:
- containerPort: 80
# backend-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend-deployment
spec:
replicas: 2
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend-container
image: my-backend-image:latest
ports:
- containerPort: 8080
Застосовуємо ці два файли командами:
kubectl apply -f frontend-deployment.yaml
kubectl apply -f backend-deployment.yaml
Масштабування застосунків
Для забезпечення адекватної продуктивності залежно від навантаження доводиться динамічно змінювати кількість екземплярів програми. Масштабувати можна як горизонтально (змінюючи кількість екземплярів), так і вертикально (змінюючи ресурси всередині одного екземпляра).
Ви можете встановити обмеження на використання ресурсів CPU та пам'яті для кожного пода в маніфесті розгортання. Це дасть змогу Kubernetes ефективно розподіляти ресурси між подами.
Наприклад:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-app-image
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Реплікація та контролери реплікації
Суть реплікації полягає в тому, що, коли в роботі програми є збій, користувач має змогу вдатися до резервної копії програми (екземпляр або репліка), щоб забезпечити безперебійне функціонування сервісів. Контролери реплікації стежать за кількістю та станом реплік, автоматично відновлюючи їх, якщо вони виходять із ладу. Це допомагає забезпечити стабільність програми навіть у разі непередбачених подій.
Іншими словами, контролери реплікації в Kubernetes керують процесом створення та підтримки заданої кількості реплік. Вони моніторять стан подів, і, якщо вони виходять з ладу або видаляються, контролери реплікації автоматично створюють нові поди.
Створимо маніфест для реплікації пода. Припустимо, маємо три репліки подання my-app. Якщо одна з них вийде з ладу, контролер реплікації автоматично створить нову, щоб забезпечити бажану кількість реплік:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-replicaset
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: my-app-image
Управління станом
«Керуючи станом» у Kubernetes, ви визначаєте, як саме програми зберігають і стежать за своїми даними. У середовищі контейнерів, де поди можуть швидко створюватися та закриватися, збереження даних та забезпечення їхнього постійного стану — завдання не з легких.
У Kubernetes є кілька способів розв'язання цієї проблеми:
- Persistent Volumes (PV) — це як сейф для даних вашої програми. Це спеціальне місце, де дані зберігаються навіть тоді, коли контейнери закриваються.
- Persistent Volume Claims (PVC) — це як ваш запит на сейф. Коли ваш застосунок хоче зберегти дані, він каже Kubernetes «Я хочу сейф», і Kubernetes знаходить відповідне місце для цього.
- Snapshotting — це як створення фотографії. Ви можете робити знімки даних, щоб зберегти поточний стан і в разі чого повернутися до нього.
- StatefulSets — це як вести список. Якщо у вас є кілька копій однієї програми, вони можуть мати унікальні імена та номери. Це корисно, коли програма зберігає важливі дані, як-от бази даних.
Припустимо, йде робота з базою даних, де зберігаються дані користувачів. Ви хочете запустити цю базу даних у Kubernetes за допомогою StatefulSet, щоб вона була надійною та зберігала дані навіть за змін.
Роблять це так:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres-statefulset
spec:
replicas: 3
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:latest
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: mydb
- name: POSTGRES_USER
value: myuser
- name: POSTGRES_PASSWORD
value: mypassword
volumeMounts:
- name: postgres-persistent-storage
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: postgres-persistent-storage
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
Що ми зробили:
- Створили StatefulSet з ім'ям postgres-statefulset, щоб керувати трьома копіями бази даних. Кожна копія матиме унікальне ім'я у стилі postgres-statefulset-<індекс>.
- Визначили контейнер із базою даних PostgreSQL, який працюватиме у кожній копії.
- Повідомили базі даних, як називається база даних, користувач та пароль.
- Створили окреме місце для зберігання даних, яке зберігатиме дані навіть за змін у подах.
Таким чином, за допомогою StatefulSet та Persistent Volume у Kubernetes ми гарантуємо, що наша база даних завжди буде доступною і збереже дані, навіть якщо ми додамо нові екземпляри або перезапустимо поди.
Основи автентифікації
Щоб контролювати, хто і як може взаємодіяти з ресурсами, у вашому кластері задіяні механізми автентифікації, авторизації, ролей і доступу в Kubernetes.
Аутентифікація — це процес перевірки, що користувач (або, наприклад, застосунок) справді той, за кого себе видає. У Kubernetes цей механізм можна реалізувати за допомогою токенів, сертифікатів чи зовнішніх систем автентифікації.
Авторизація — це процес визначення, чи має користувач або сутність право виконання конкретних дій у системі. У Kubernetes це регулюється через управління ролями та доступом (Role-Based Access Control — RBAC).
Ролі та доступ (RBAC) — це метод управління правами доступу Kubernetes. Він дозволяє дати різні рівні доступу різним користувачам чи групам користувачів. Ви визначаєте ролі, які можуть бути пов'язані з користувачами, сервісами та іншими об'єктами в кластері. Ці ролі можуть мати дозволи виконання певних операцій над ресурсами.
У наведеному нижче коді:
- Створюється роль pod-reader, яка дозволяє користувачеві (чи іншій сутності) виконувати операції get і list над ресурсами pods у просторі імен default.
- Ми створюємо прив'язку ролі (RoleBinding), яка пов'язує роль pod-reader з користувачем alice. Тепер alice може читати інформацію про поди у просторі імен default.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: alice
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
Висновок
Коректне налаштування кластера — це не тільки гарантія надійної роботи ваших застосунків, а й засіб забезпечення безпеки, масштабованості та керованості. Неправильні налаштування можуть призвести до втрати даних, недоступності програми або навіть вразливості. Тому важливо приділити належну увагу кожному кроку налаштування та переконатися, що всі компоаненти працюють у гармонії.


