
Развертывание приложения на Ubuntu: настраиваем кластер Kubernetes
Поэтапная инструкция от robot_dreams
Сегодня мы продолжим говорить о Kubernetes и рассмотрим ключевые шаги, необходимые для успешной настройки кластера, начиная от установки обязательных компонентов и заканчивая развертыванием приложений на Ubuntu.
Выбор платформы для развертывания
Первый этап при настройке кластера Kubernetes — выбор подходящей платформы для развертывания. В зависимости от ваших потребностей и доступных ресурсов, вы можете остановить свой выбор на одном из облачных провайдеров, таких как Amazon Web Services (AWS), Google Cloud Platform (GCP) или Microsoft Azure, либо использовать собственное физическое оборудование.
Облачные провайдеры обладают рядом преимуществ (по сравнению с развертыванием собственной инфраструктуры). Из достоинств «облака» можно отметить:
- гибкость;
- масштабируемость;
- удобство управления.
Например, AWS предоставляет сервис Elastic Kubernetes Service (EKS), GCP предлагает Google Kubernetes Engine (GKE), а Azure — Azure Kubernetes Service (AKS). Эти сервисы упрощают развертывание, управление и масштабирование кластеров Kubernetes, предоставляя инструменты для автоматизации ряда рутинных задач.
Так, на AWS EKS вместо настройки серверов и управления операционной системой, вы просто создаете кластер через консоль управления или API. EKS занимается автоматическим обновлением кластера, обеспечивая безопасность и обновления патчей. AWS EKS выполняет автоматические обновления Kubernetes, позволяя вам оставаться на актуальной версии. Также EKS контролирует процесс обновления мастер-нод, экономя время, затрачиваемое на управление апдейтами.
В работе удобно использовать интеграцию EKS с другими сервисами AWS, такими как AWS Identity and Access Management (IAM), Amazon VPC, Amazon CloudWatch и т. д. Это позволяет автоматизировать доступ, мониторинг и настройку сетевых параметров.
В то же время облачные провайдеры годятся не для всех сценариев. Например, если вы имеете дело со сложной сетевой архитектурой, облачный провайдер может не предоставлять гибких инструментов для налаживания сетевых настроек, что ограничит вашу способность управлять трафиком и осуществлять контроль безопасности.
Настройка кластера Kubernetes
Подготовка к развертыванию кластера на Ubuntu
При настройке кластера Kubernetes потребуется установить различные компоненты, такие как kube-apiserver, kube-controller-manager, kube-scheduler, etcd и другие, на управляющих (Master) и рабочих (Worker) узлах.
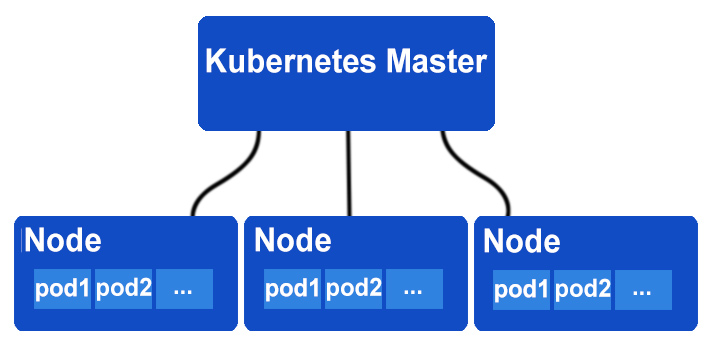
Архитектура Kubernetes
Этот процесс может быть сложным, и для облегчения его проведения разработаны различные инструменты установки и управления кластером Kubernetes. Например, можно выделить следующие:
- kubeadm — упрощает процесс установки и настройки кластера Kubernetes на самых обычных виртуальных машинах или физических серверах. Он предоставляет команды для установки и настройки компонентов кластера, а также автоматически генерирует конфигурационные файлы.
- kops — используется для развертывания и управления кластерами Kubernetes в облачных провайдерах, таких как AWS. Он автоматизирует создание и настройку необходимых ресурсов, как, например, виртуальные машины, сети и хранилища, для развертывания кластера.
- Rancher — инструмент, который позволяет управлять контейнерами, включая Kubernetes, на различных платформах, включая как облачные провайдеры, так и собственную инфраструктуру.
- minikube — инструмент предназначен для разработки и тестирования локальных кластеров Kubernetes. Он позволяет быстро создать миниатюрный кластер на вашей локальной машине для проверки функциональности.
- k3s — легковесная реализация Kubernetes, разработанная для установки на ресурсоограниченных устройствах или в средах с ограниченными ресурсами.
Установка Docker
Поскольку Kubernetes использует Docker для контейнеризации приложений, первым делом устанавливаем Docker:
sudo apt update
sudo apt install docker.io
Установка kubeadm, kubelet и kubectl
Далее устанавливаем kubeadm, kubelet и kubectl:
sudo apt update
sudo apt install -y apt-transport-https curl
sudo curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
sudo echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt update
sudo apt install -y kubelet kubeadm kubectl
Скриншот терминала
После установки kubelet нужно его настроить для корректной работы. Создайте файл /etc/default/kubelet (sudo nano /etc/default/kubelet) и добавьте следующую строку:
KUBELET_EXTRA_ARGS=--cgroup-driver=cgroupfs
Сохраните изменения и перезапустите kubelet:
sudo systemctl restart kubelet
Чтобы убедиться, что файл был создан, наберите в терминале:
cat /etc/default/kubelet
Если вы увидите содержимое файла, это означает, что файл /etc/default/kubelet существует и содержит добавленную вами строку KUBELET_EXTRA_ARGS=--cgroup-driver=cgroupfs.
Проверьте версии установленных компонентов:
kubectl get cs -A
Проверка связности хостов
- Проверьте связность между хостами, чтобы узлы свободно обменивались данными и взаимодействовали между собой.
- Убедитесь, что отсутствуют блокировки сетевого трафика брандмауэрами, что необходимые сетевые порты доступны (например, открыт ли порт для API-сервера Kubernetes — обычно 6443) и что настройки сети не фильтруют или блокируют сетевые запросы между узлами.
- Убедитесь, что DNS настроен правильно, чтобы имена хостов могли разрешаться в IP-адреса. Это важно для обмена данными между узлами по именам.
Напомним, что в Linux есть файл /etc/hosts, который выполняет аналогичную функцию как файл C:\Windows\System32\drivers\etc\hosts на Windows.
Файл /etc/hosts а Linux используется для преобразования имен хостов в IP-адреса без необходимости использования DNS-серверов. Вы можете редактировать этот файл для добавления собственных записей, которые помогут привязывать имена хостов к IP-адресам в вашей локальной сети. Это особенно полезно для обеспечения доступа между узлами в локальных тестовых или разработческих средах.
Общий формат записей:
< IP-адрес > < имя хоста >
Например:
192.168.1.100 master
192.168.1.101 worker1
192.168.1.102 worker2
...
Инициализация мастер-ноды
Подготовим главную ноду (мастер-ноду), которая будет управлять всеми действиями в кластере. Для инициализации мастер-ноды Kubernetes применяется команда kubeadm init. Она выполняет следующие ключевые этапы:
- Установка компонентов мастер-ноды. Команда kubeadm init устанавливает компоненты мастер-ноды, включая API-сервер, контроллеры, планировщик и другие компоненты, которые управляют кластером.
- Генерация конфигурации. После установки kubeadm генерирует конфигурационные файлы для kubeconfig и конфигурации компонентов. Эти файлы используются kubectl для взаимодействия с кластером.
- Создание токена присоединения. При успешной инициализации мастер-ноды генерируется токен присоединения. Этот токен будет использоваться для присоединения рабочих нод к мастер-ноде.
- Создание конфигурации CNI. kubeadm также предоставляет информацию о том, какой плагин CNI (Container Network Interface) использовать и какой драйвер сети будет работать в кластере.
Команда kubeadm init на мастер-ноде для инициализации кластера:
sudo kubeadm init --pod-network-cidr=192.168.0.0/16
Выражение --pod-network-cidr определяет диапазон IP-адресов для сети контейнеров. После успешного выполнения этой команды вы увидите вывод, в котором будет важная информация, включая токен для присоединения рабочих нод. Примерно такой:
...
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.100:6443 --token abcdef.1234567890abcdef \
--discovery-token-ca-cert-hash sha256:hash_value
Обратите внимание на команду kubeadm join — она содержит --token и --discovery-token-ca-cert-hash. Эти параметры предоставляют рабочим нодам аутентификационный токен и хэш сертификата CA для присоединения к мастер-ноде.
После инициализации мастер-ноды присоединяем к кластеру рабочие ноды. Для этого применяется команда, которая была предоставлена после успешного выполнения kubeadm init на мастер-ноде. Эта команда включает в себя токен и хэш сертификата CA.
Например, для присоединения кластера на рабочей ноде можно выполнить команду:
sudo kubeadm join 192.168.1.100:6443 --token
abcdef.1234567890abcdef \
--discovery-token-ca-cert-hash sha256:hash_value
Нужно заменить 192.168.1.100 на IP-адрес вашей мастер-ноды и использовать определенные значения --token и --discovery-token-ca-cert-hash, которые были предоставлены вам после kubeadm init. После успешного присоединения рабочей ноды к кластеру вы увидите следующее:
This node has joined the cluster: *
Certificate signing request was sent to master and a response was
received. * The Kubelet was informed of the new secure connection
details. Run 'kubectl get nodes' on the master to see this node
join the cluster.
Этот вывод подтверждает, что рабочая нода успешно присоединилась к кластеру. Теперь вы можете выполнить kubectl get nodes на мастер-ноде, чтобы увидеть новую рабочую ноду в списке активных узлов.
Вывод команды kubectl get nodes на мастер-ноде после успешного присоединения рабочей ноды может выглядеть следующим образом:
NAME STATUS ROLES AGE VERSION
master-node Ready master 1d v1.21.2
worker-node1 Ready <none> 1h v1.21.2
worker-node2 Ready <none> 30m v1.21.2
Здесь NAME — это имена узлов, STATUS показывает состояние, ROLES указывает на роль (мастер, рабочий и т. д.), значение AGE показывает время работы узла, а VERSION показывает версию Kubernetes на узле.
Рабочие ноды (worker-node1 и worker-node2) имеют статус Ready, что подтверждает успешное присоединение кластера.
Настройка kubectl
Для управления кластером Kubernetes используется kubectl (можно установить отдельно). С помощью kubectl вы можете взаимодействовать с вашим кластером, управлять приложениями, создавать и управлять ресурсами, выполнять отладку и мониторинг и пр. Для успешной работы с кластером через kubectl необходимо настроить конфигурационный файл ~/.kube/config, который пишется в формате YAML. Он содержит информацию о кластере, пользователях и контекстах.
Контекстом называется набор параметров, который определяет взаимодействие с кластером Kubernetes; контексты позволяют вам переключаться между разными кластерами и пользователями без необходимости повторного ввода данных при каждой команде kubectl.
Если у вас еще нет файла ~/.kube/config, вы можете его создать самостоятельно. Чтобы добавить информацию о кластере в файл ~/.kube/config, в текстовом редакторе (например, nano или vim) откройте файл:
nano ~/.kube/config
Затем добавьте следующий блок конфигурации, заменив значения server и certificate-authority на соответствующие для вашего кластера:
apiVersion: v1
kind: Config
clusters:
- name: my-cluster-name
cluster:
server: https://your-cluster-server.com
certificate-authority: /path/to/ca.crt


После сохранения файла вы получаете добавленный кластер в вашем конфигурационном файле. В этот же файл можно добавить информацию о пользователях и контекстах:
apiVersion: v1
kind: Config
clusters:
- name: my-cluster-name
cluster:
server: https://your-cluster-server.com
certificate-authority: /path/to/ca.crt
users:
- name: my-user
user:
client-certificate: /path/to/user.crt
client-key: /path/to/user.key
contexts:
- name: my-context
context:
cluster: my-cluster-name
user: my-user
В приведенном выражении необходимо заменить /path/to/ca.crt, /path/to/user.crt и /path/to/user.key на пути к соответствующим сертификатам и ключам.
Продолжим настройку kubectl и добавление дополнительных кластеров, пользователей и контекстов к вашему конфигурационному файлу ~/.kube/config. Контекст объединяет кластер, пользователя и название контекста. Пример добавления кластера пользователя:
apiVersion: v1
kind: Config
current-context: my-k8s-cluster
clusters:
- name: my-k8s-cluster
cluster:
server: https://your-cluster-server.com
certificate-authority: /path/to/ca.crt
users:
- name: my-k8s-user
user:
client-certificate: /path/to/user.crt
client-key: /path/to/user.key
contexts:
- name: my-k8s-context
context:
cluster: my-k8s-cluster
user: my-k8s-user
Выбрать активный контекст, который будет использоваться для kubectl, можно с помощью команды kubectl config use-context.
Основные команды kubectl:
• kubectl get nodes — Получение списка всех узлов в кластере.
• kubectl get pods — Получение списка подов (запущенных контейнеров) в кластере.
• kubectl get services — Получение списка сервисов в кластере.
• kubectl create — Создание ресурсов (поды, сервисы и т. д.).
• kubectl застосувати — Применение конфигурационных файлов для создания или обновления ресурсов.
• kubectl delete — Удаление ресурсов.
• kubectl describe — Получение подробной информации о ресурсе.
• kubectl logs — Получение логов контейнера.
• kubectl exec — Запуск команды внутри контейнера.
Примеры развертывания приложений
Простое Hello world
Напишем несложный манифест для развертывания Hello world в виде пода:
apiVersion: v1
kind: Pod
metadata:
name: hello-world-pod
spec:
containers:
- name: hello-world-container
image: busybox
command: ["echo", "Hello, World!"]
Сохраняем его в виде hello-world-pod.yaml и применяем командой:
kubectl apply -f hello-world-pod.yaml
Развертывание микросервисного приложения
Предположим, у нас есть два микросервиса — frontend и backend. Создадим YAML-манифесты для каждой части приложения:
# frontend-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend-deployment
spec:
replicas: 2
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend-container
image: my-frontend-image:latest
ports:
- containerPort: 80
# backend-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend-deployment
spec:
replicas: 2
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend-container
image: my-backend-image:latest
ports:
- containerPort: 8080
Применяем эти два файла командами:
kubectl apply -f frontend-deployment.yaml
kubectl apply -f backend-deployment.yaml
Масштабирование приложений
Для обеспечения адекватной производительности в зависимости от нагрузки приходится динамично менять количество экземпляров приложения. Масштабировать можно как горизонтально (меняя количество экземпляров), так и вертикально (изменяя ресурсы внутри одного экземпляра).
Вы можете задать ограничения на использование ресурсов CPU и памяти для каждого пода в манифесте развертывания. Это позволит Kubernetes эффективно распределять ресурсы между подами.
Например:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-app-image
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Репликация и контроллеры репликации
Суть репликации состоит в том, что, когда в работе приложения имеется сбой, у пользователя есть возможность прибегнуть к резервной копии приложения (экземпляр или реплика), чтобы обеспечить бесперебойное функционирование сервисов. Контроллеры репликации следят за количеством и состоянием реплик, автоматически восстанавливая их, если они выходят из строя. Это позволяет обеспечить стабильность приложения даже в случае непредвиденных событий.
Иначе говоря, контроллеры репликации в Kubernetes управляют процессом создания и поддержания заданного количества реплик. Они мониторят состояние подов, и, если они выходят из строя или удаляются, контроллеры репликации автоматически создают новые поды.
Создадим манифест для репликации пода. Предположим, имеем три реплики пода my-app. Если одна из них выйдет из строя, контроллер репликации автоматически создаст новую, чтобы обеспечить желаемое количество реплик:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-replicaset
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: my-app-image
Управление состоянием
«Управляя состоянием» в Kubernetes, вы определяете, как именно приложения сохраняют и следят за своими данными. В среде контейнеров, где поды могут быстро создаваться и закрываться, сохранение данных и обеспечение их постоянного состояния — задача не из легких.
В Kubernetes есть несколько способов решения этой проблемы:
- Persistent Volumes (PV) — это как сейф для данных вашего приложения. Это специальное место, где данные хранятся даже тогда, когда контейнеры закрываются.
- Persistent Volume Claims (PVC) — то как ваш запрос на сейф. Когда ваше приложение хочет сохранить данные, оно говорит Kubernetes «Я хочу сейф», и Kubernetes находит подходящее место для этого.
- Snapshotting — это как создание фотографии. Вы можете делать снимки данных, чтобы сохранить текущее состояние и в случае чего вернуться к нему.
- StatefulSets — это как вести список. Если у вас есть несколько копий одного приложения, они могут иметь уникальные имена и номера. Это полезно, когда приложение хранит важные данные, такие как базы данных.
Предположим, идет работа с базой данных, в которой хранятся данные пользователей. Вы хотите запустить эту базу данных в Kubernetes с помощью StatefulSet, чтобы она была надежной и сохраняла данные даже при изменениях.
Делается это так:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres-statefulset
spec:
replicas: 3
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:latest
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: mydb
- name: POSTGRES_USER
value: myuser
- name: POSTGRES_PASSWORD
value: mypassword
volumeMounts:
- name: postgres-persistent-storage
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: postgres-persistent-storage
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
Что мы сделали:
- Создали StatefulSet с именем postgres-statefulset, чтобы управлять тремя копиями базы данных. Каждая копия будет иметь уникальное имя в стиле postgres-statefulset-<індекс>.
- Определили контейнер с базой данных PostgreSQL, который будет работать в каждой копии.
- Сообщили базе данных, как называется база данных, пользователь и пароль.
- Создали отдельное место для хранения данных, которое будет сохранять данные даже при изменениях в подах.
Таким образом, с помощью StatefulSet и Persistent Volume в Kubernetes мы гарантируем, что наша база данных всегда будет доступной и сохранит данные, даже если мы добавим новые экземпляры или перезапустим поды.
Основы аутентификации
Чтобы контролировать, кто и как может взаимодействовать с ресурсами, в вашем кластере задействуются механизмы аутентификации, авторизации, ролей и доступа в Kubernetes.
Аутентификация — это процесс проверки, что пользователь (или, например, приложение) действительно тот, за кого себя выдает. В Kubernetes этот механизм можно реализовать с помощью токенов, сертификатов или внешних систем аутентификации.
Авторизация — это процесс определения, имеет ли пользователь или сущность право на выполнение конкретных действий в системе. В Kubernetes это регулируется через управление ролями и доступом (Role-Based Access Control — RBAC).
Роли и доступ (RBAC) — это метод управления правами доступа в Kubernetes. Он позволяет дать различные уровни доступа разным пользователям или группам пользователей. Вы определяете роли, которые могут быть связаны с пользователями, сервисами или другими объектами в кластере. Эти роли могут иметь разрешения на выполнение определенных операций над ресурсами.
В приведенном ниже коде:
- Создается роль pod-reader, которая позволяет пользователю (или иной сущности) выполнять операции get и list над ресурсами pods в пространстве имен default.
- Мы создаем привязку роли (RoleBinding), которая связывает роль pod-reader с пользователем alice. Теперь alice может читать информацию о подах в пространстве имен default.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: alice
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
Заключение
Корректная настройка кластера — это не только гарантия надежной работы ваших приложений, но и средство обеспечения безопасности, масштабируемости и управляемости. Неправильные настройки могут привести к потере данных, недоступности приложения или даже уязвимостям. Поэтому важно уделить должное внимание каждому шагу настройки и удостовериться, что все компоненты работают в гармонии.


