
Від сирих даних до точних прогнозів: Чому без Feature Engineering алгоритми не працюють на повну
Основа для покращення моделей машинного навчання
Наука про дані (Data Science) нерозривно пов’язана з машинним навчанням (Machine Learning, ML). Використовуючи зібрану інформацію, ML допомагає бізнесам автоматизувати процеси, ухвалювати обґрунтовані рішення та вдосконалювати бізнес-моделі. Наприклад, можна створити персоналізовану систему рекомендацій для клієнтів, яка підвищить продажі або покращить їхній досвід користування сервісами.
Успіх інженерного аналізу даних за допомогою ML значною мірою залежить від попередньої обробки та підготовки сирих даних (Raw Data). Саме на цьому етапі фахівці з Data Science витрачають чимало часу, застосовуючи, зокрема, інженерію ознак (Feature Engineering). Що це за система і як вона працює — розповідаємо далі в нашому матеріалі.
Що таке інженерія ознак
Інженерія ознак для машинного навчання — це процес підготовки даних для того, щоб алгоритми машинного навчання могли працювати краще. Уявіть, що ви маєте великий набір сирих даних, як-от інформацію про покупки в інтернет-магазині. Але щоб навчити комп’ютер передбачати, що клієнт може купити наступного разу, ці дані треба впорядкувати й перетворити на формат, з яким комп’ютеру буде легше працювати.
Інженерія ознак — це і є такий процес. Фахівці аналізують дані, обирають найважливіші частини (ознаки) та організовують їх у такий спосіб, щоб алгоритм міг «навчитися» і давати точні прогнози. Це схоже на те, як ви готуєте інгредієнти перед приготуванням страви, — щоб усе було на своєму місці та працювало разом найкращим чином.
Що таке ознака в машинному навчанні
Кожен окремий параметр даних називають ознакою. Наприклад, якщо потрібно передбачити рівень продажів, важливими характеристиками можуть бути місце проживання клієнта, його вік, рівень доходу й останні покупки. Ці ознаки можна доповнити або замінити новими, щоб отримати повнішу картину. Такий підхід допомагає машинному навчанню робити точніші прогнози, а отже, й бізнесу.
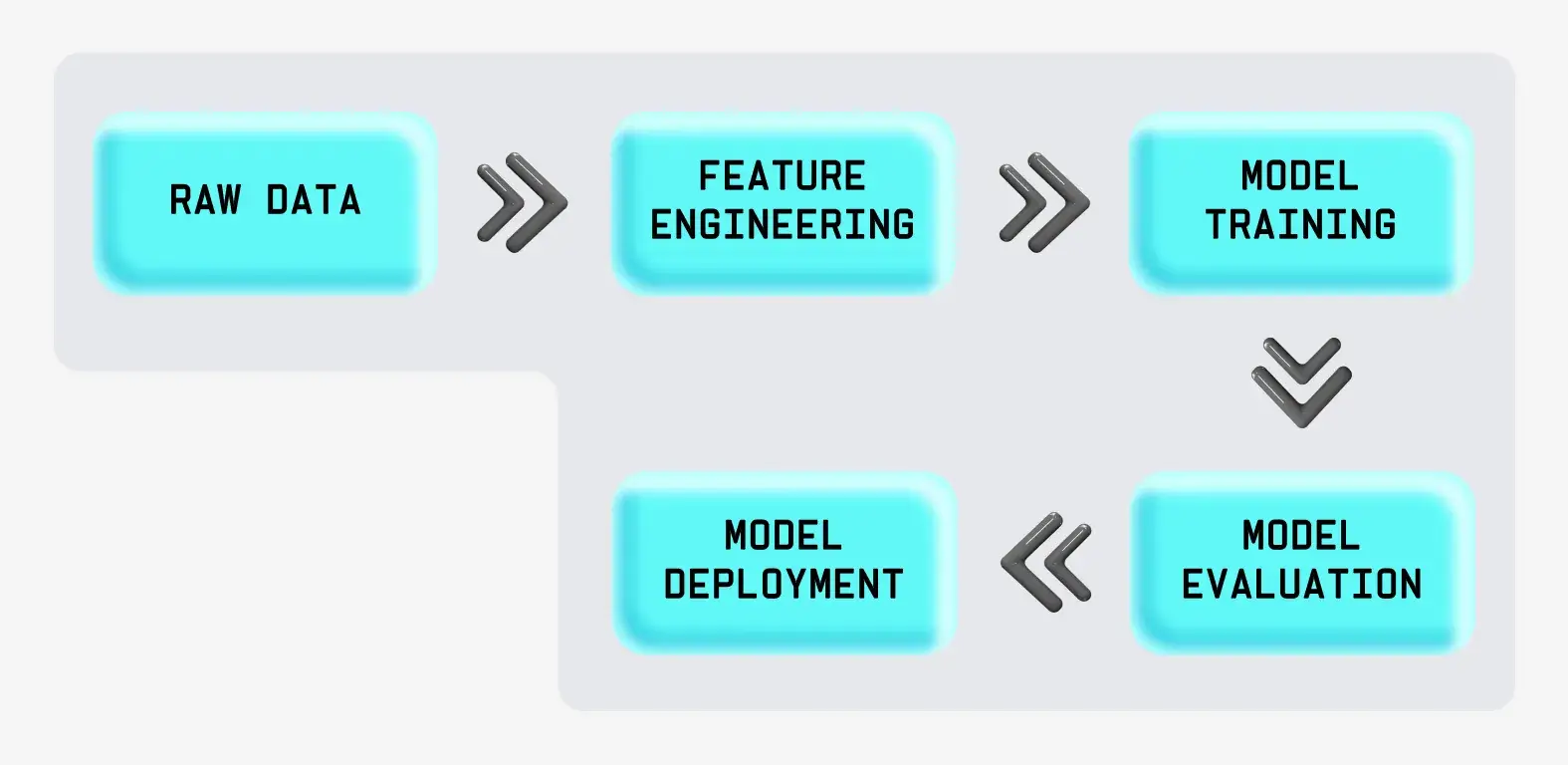
Етапи інженерії ознак
Креативний процес, що вимагає використання різних методів для обробки даних та виокремлення певного набору ознак. Сюди входять такі техніки, як-от заповнення пропущених даних, кодування категоріальних змінних, масштабування даних та інші. Розгляньмо основні методи інженерії ознак.
Дослідження даних
Інформація для аналізу надходить з різних джерел. Важливо її ретельно вивчити, щоб зрозуміти структуру та контекст. Це допоможе визначити ключові ознаки, їхні взаємозв’язки та користь.
Очищення даних
Неякісні дані можуть погіршити продуктивність моделі. На цьому етапі важливо визначити й опрацювати прогалини. Для цього існують різні алгоритми: індикаторний метод, регресійна імпутація, заміна довільним значенням тощо.

Також потрібно виявити й видалити аномальні значення, які суттєво відрізняються від інших показників, усунути дублювання та привести дані до відповідних форматів.
Робота з аномаліями
Аномалії (outliers) — це значення, які суттєво відрізняються від решти значень змінної та можуть погіршити результати ML-моделі. Робота з аномаліями передбачає видалення таких значень. Цю процедуру потрібно виконати до навчання моделі. Для роботи з аномаліями можна використовувати методи:
- trimming — видалення відхилень з діапазону значень;
- winsorizing — заміна аномального значення на найближче, яке не є відхиленням.
Створення ознак (feature creation)
Після аналізу даних може виникнути потреба створити нові ознаки на основі наявних. Цей процес відбиває складні взаємозв'язки та закономірності в даних.
Наприклад, створювати ознаки можна шляхом:
- Взаємопов’язаних ознак (interaction features). У процесі створення нових ознак беруть до уваги спільний вплив двох або більше ознак.
- Арифметичних операцій. Наприклад, можна обчислити суму значень із наявних ознак та створити нову.
- Поліноміальних ознак (polynomial features). Нову ознаку створюють шляхом піднесення до ступеня значень наявних ознак. Це допомагає моделі виявляти приховані взаємозв’язки між змінними.
- Агрегатних ознак. Створення ознаки за допомогою функцій для узагальнення або агрегації численних вхідних даних.
- Дискретизація або квантування (binning). Перетворення неперервних даних на дискретні. Це відбувається шляхом заміни значень відрізками, кожен з яких належить певному діапазону, або розбиття їх на категорії. Наприклад, вік можна розбити на категорії «молодий», «середній», «літній».
Кодування категоріальних змінних
На цьому етапі обрані ознаки потребують перетворення на формат, який може опрацювати ML-модель. Категоріальні змінні представляють типи даних, які можна розділити на групи: стать, раса, рівень освіти тощо. Наприклад, ви зібрали інформацію про марки автомобілів клієнтів: Mercedes, KIA, Peugeot тощо. Ці відповіді можна поділити на фіксований набір категорій. Однак ви отримаєте помилку, якщо спробуєте підставити ці змінні в ML-модель без попередньої конвертації. Моделі працюють із числовим, а не з текстовим або категорійним форматом змінних.
Для конвертації змінних є різні методи, наприклад:
- One-Hot Encoding — створення окремих бінарних стовпців для кожної категорії;
- Label Encoding — перетворення категорій на числа.
Вибір цих або інших методів кодування залежить від типу змінних, кількості категорій, алгоритмів машинного навчання та інших факторів.
Масштабування змінних
Для навчання ML-моделі потрібні дані з відомим набором ознак, які треба масштабувати відповідно до ситуації. Після операції масштабування неперервні змінні стають наближеними з огляду на їхній діапазон. Масштабувати змінні можна за допомогою нормалізації або стандартизації.
Нормалізація масштабує всі значення у визначеному діапазоні від 0 до 1. Такий метод підсилює вплив аномальних відхилень (outliers), тому бажано їх усувати перед нормалізацією.
Стандартизація перетворює дані таким чином, щоб вони мали середнє значення 0 і стандартне відхилення 1. Після стандартизації дані буде розподілено симетрично навколо середнього значення.
Масштабування важливе, якщо використовують алгоритм машинного навчання, чутливий до ознак (наприклад, алгоритмів на основі градієнтного спуску або кластерного аналізу).

Обробка текстових даних
Щоб підготувати текстові дані для машинного навчання, потрібно виконати кілька кроків:
- Токенізація (tokenization). Процес розбиття тексту на менші одиниці — токени (слова, фрази або символи). Це перший крок у підготовці тексту до подальшої обробки.
- Стемінг (stemming). Зведення слів до їхньої базової або кореневої форми. Це допомагає зменшити кількість варіантів одного і того самого слова.
Прикладом інженерії ознак на цьому етапі буде скорочення слів: «бігає», «бігала», «бігти» до «біг». - Видалення стоп-слів. Для зменшення обсягу даних видаляють слова, які не мають змістового навантаження. Наприклад, «я», «на», «у» тощо.
Ознаки часових рядів
Часовий ряд — це ряд точок даних, перелічених у хронологічному порядку. Наприклад, інформація про продажі за місяцями. Для аналізу таких даних потрібно створювати специфічні ознаки, які враховують залежність від часу:
- Лагові ознаки (lag features). Обирають попередні значення часового ряду для передбачення майбутніх.
- Ковзна статистика (rolling statistics). Статистичні показники (середнє, стандартне відхилення тощо) обчислюють на основі певного інтервалу часу.
Векторні ознаки
Це стандартний формат представлення даних для машинного навчання. Вектор — це об’єкт прикладної математики, який має величину і напрямок, і його можна представити у вигляді масиву чисел. Наприклад, в один вектор можна об’єднати ознаки [вік, дохід, кількість покупок].
Вибір ознак (Feature Selection)
Для уникнення перенавантаження моделі та її ефективного навчання важливо правильно обрати ознаки. Для цього є різні методи, серед яких:
- Одновимірний вибір ознак. Відбір найкращих ознак на основі одновимірних статистичних тестів.
- Рекурсивне виключення ознак. Вибір ознаки на основі рекурсивного розгляду дедалі меншого і меншого набору ознак.
Виділення ознак (Feature Extracion)
Процес спрямований на зменшення складності (розмірності) даних зі збереженням корисної інформації. Це дає змогу покращити продуктивність алгоритмів машинного навчання. Виділення ознак може охоплювати створення нових ознак та обробку даних для відсіювання неважливих характеристик.
Для зменшення розмірності використовуйте метод головних компонент (Principal Component Analysis, PDA) або T-розподілене вкладення стохастичної близькості (t-Distributed Stochastic Neighbor Embedding, t-DSNE).
Перехресна перевірка
Перехресна перевірка — це статистичний метод перевірки та оцінки ML-моделей шляхом їхнього навчання на різних підмножинах наявних даних і тестування на решті даних. Перехресна перевірка допомагає виявити, коли модель добре працює на навчальних даних, але не може узагальнити нові невідомі дані.
Інженерія ознак вимагає багаторазових ітерацій для досягнення найкращих результатів у машинному навчанні. Ці етапи можуть змінюватися залежно від типу даних та конкретного завдання. Регулярно перевіряйте та вдосконалюйте дані, щоб сформувати надійний та ефективний набір ознак.


