
Как работать с SQL: 17 практических советов начинающим аналитикам
Эффективные техники и инструменты
В сфере анализа данных SQL (Structured Query Language — язык структурированных запросов) — это ключевой инструмент для работы с базами данных. С его помощью аналитики могут быстро находить нужную информацию и легко взаимодействовать с ней.
SQL имеет интуитивно понятный синтаксис, что делает его доступным даже для новичков. В то же время его мощность и функциональность позволяют опытным аналитикам работать с данными на более глубоком уровне. Освоить базовые навыки SQL несложно, но, чтобы по-настоящему овладеть им, может потребоваться время. Именно поэтому мы подготовили 17 практических советов, которые помогут начинающим аналитикам эффективнее работать с SQL и быстрее достичь профессионального уровня.
1. Овладейте командой SELECT
Выделяют 5 видов SQL-запросов, с которыми работают дата-аналитики:
DDL (Data Definition Language) — язык определения данных для создания и изменения структуры БД (таблицы, схемы, индексы).
DCL (Data Control Language) — язык управления для предоставления или ограничения доступа пользователей к данным в БД.
TCL (Transaction Control Language) — язык управления транзакциями. Обеспечивает их целостность и согласованность.
DML (Data Manipulation Language) — язык манипулирования данными для работы с информацией в существующих таблицах (добавление, обновление, удаление).
DQL (Data Query Language) —язык запросов данных для их выборки из БД. Формально относится к DML, но часто выделяется из-за специфики использования основной команды SELECT.
Оператор SELECT является базой SQL. Он извлекает данные из одной или нескольких таблиц, используя различные фильтры, сортировки и объединения. Это оператор, с которым вы будете чаще всего работать.
Команду SELECT можно дополнить операторами:
WHERE— фильтрует данные по нужному условию;GROUP BY— группирует данные по указанным признакам;HAVING— фильтрует данные по заданным критериям, применяется после группировки;JOIN— объединяет данные из нескольких таблиц с помощью разных типов соединений:INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN;LIMIT— ограничивает количество строк в выборке данных.
Оператор FROM
Оператор FROM является обязательным элементом в запросах SELECT и определяет, из какой таблицы (или таблиц) брать данные. Он задает основной источник данных по запросу. В случае использования нескольких таблиц, FROM может работать в паре с JOIN для объединения данных из разных таблиц на основе соответствующих условий.
Примеры использовани
#1. Выбор столбцов 'name' и 'age' из таблицы 'users'
SELECT name, age
FROM users;
#2. Выбор всех столбцов из таблицы ‘users’ с помощью *.
SELECT *
FROM users;
#3. Фильтрация данных с помощью WHERE. Например, нас интересуют данные пользователей старше 18 лет.
SELECT name, age
FROM users
WHERE age > 18;
#4. Также можно комбинировать условия выборки с помощью логических операторов AND, OR. Дополним предыдущий запрос условием, чтобы пользователи были из Киева.
SELECT name, age
FROM users
WHERE age > 18 AND city = 'Kyiv';
Как видите, оператор SELECT является основным инструментом для работы с БД. Поэтому стоит уделить достаточно времени ее изучению и практике использования.
2. Используйте вложенные запрос
Вложенный запрос (подзапрос) — это запрос внутри другого SQL-запроса, который разбивает сложный процесс выборки или анализа на более мелкие шаги. Таким образом вы можете получить данные, которые нереально выделить простым запросом. Применяйте этот инструмент, чтобы открыть новые возможности в работе с БД и добавить гибкости в процесс выборки. Потренируйтесь писать подзапросы для различных сценариев, чтобы максимально раскрыть их потенциал и решать сложные задачи.
Примеры использовани
- Получение промежуточных результатов
Вам нужно вывести имена покупателей, которые приобрели ноутбуки. Вложенный запрос сначала находит всех пользователей, которые заказали ноутбук (промежуточный результат), а затем выводит их имена.
SELECT name
FROM buyers
WHERE id IN
(
SELECT user_id
FROM orders
WHERE product = ‘ноутбук’
);
- Фильтрация на основе агрегированных данных
Необходимо найти сотрудников с зарплатой выше средней по компании. КомандойSELECTтакое сделать невозможно напрямую. Для этого процесс нужно разбить на два этапа: сначала посчитать среднюю зарплату в компании, а затем использовать этот результат для поиска соответствующих сотрудников.
SELECT name, salary
FROM employees
WHERE salary >
(
SELECT AVG(salary)
FROM employees
);
Ограничивайте количество вложенных запросов. Слишком сложные конструкции увеличивают риск ошибки, и со временем вы вряд ли вспомните, какие данные хотели получить. Коллегам тоже будет сложно разобраться в таком коде. Также проверяйте корректность выполнения запросов на промежуточных этапах, чтобы вовремя выявить возможные ошибки.
3. Используйте общие табличные выражения (CTE)
Общее табличное выражение CTE (Common Table Expression) — это временный результат или виртуальная таблица, которую можно многократно задействовать в рамках одного запроса. Аналогично вложенным запросам CTE применяются для создания сложных SQL-запросов. Преимущество CTE заключается в возможности повторного использования без дублирования кода. Благодаря CTE структура запросов становится более четкой и разделенной на логические блоки.
Применяйте CTE в случаях:
- сложного, многоуровневого запроса, который требует промежуточных вычислений;
- когда одна и та же выборка или вычисление используются несколько раз в пределах одного запроса;
- когда необходима рекурсия (рекурсивный CTE) — рекурсивные CTE ссылаются сами на себя в своих описаниях, что позволяет работать с иерархическими или древовидными структурами данных.
CTE задаются оператором WITH, и затем на них можно ссылаться в командах SELECT, INSERT, UPDATE, DELETE или MERGE.
Пример использования CTE
Предположим, у нас есть таблица ‘employees’ с колонками:
- id — унікальний ID працівника;
- name — имя сотрудника;
- department — название отдела;
- salary — зарплата сотрудника.
В данном примере SQL-запроса CTE вычисляет среднюю зарплату для каждого отдела в таблице ‘employees’. Он группирует записи по колонке ‘department’, а результат вычисления и название отдела сохраняет во временной таблице ‘DepartmentAverageSalary’.
Основной запрос использует CTE для выборки отделов, где средняя зарплата превышает 5000, выводя название такого отдела и его среднюю зарплату.
//CTE
WITH DepartmentAverageSalary AS
(
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department
)
//Основной запрос
SELECT department, avg_salary
FROM DepartmentAverageSalary
WHERE avg_salary > 5000;
4. Обратите внимание на оконные функци
Оконная функция (Window function) работает с выделенным набором строк (окном) и выполняет вычисления для этого набора в отдельном столбце. Так называемые «окна» со строками могут быть расположены в разных столбцах таблицы, но их не нужно предварительно группировать для проведения вычислений. В отличие от агрегатных функций, которые группируют данные с помощью(GROUP BY), оконные функции вычисляют значения для каждой строки отдельно, что позволяет использовать как исходные, так и обработанные данные одновременно.
Чаще всего оконные функции применяются для ранжирования, кумулятивных вычислений, анализа временных рядов, метода скользящего среднего вычисления разниц между строками. Используйте эти функции для упрощения анализа больших наборов данных и повышения эффективности своей работы.
Примеры оконных функций:
ROW_NUMBER()— присваивает уникальный номер каждой строке в пределах окна;RANK()— присваивает ранги строкам в пределах окна, допускаются одинаковые значения ранга для строк с равными значениями;SUM(), AVG(), MIN(), MAX()— выполняют агрегатные вычисления над определенным окном строк;PARTITION BY— разбивает строки на группы (окна) для вычислений;ORDER BY— определяет порядок строк в пределах каждого окна.

5. Работайте с JSO
JSON (JavaScript Object Notation) — это удобный формат для хранения, обработки, манипуляции и обмена неструктурированными данными в SQL. Сегодня много данных поступает из разных источников в разных форматах, поэтому JSON является незаменимым инструментом для работы с ними.
JSON позволяет:
- хранить и анализировать данные с различной структурой, сохраняя их полноту и связи;
- легко импортировать данные из различных источников (внешние API, NoSQL БД, логи и т. д.);
- адаптировать модель данных к новым запросам.
6. Изучите операторы PIVOT и UNPIVOT
Эти операторы позволяют трансформировать таблицы, изменяя структуру данных для более удобного анализа.
PIVOT
Нужен для преобразования строк в столбцы, агрегации данных и представления их в более удобном для анализа формате. Например, есть таблица с данными продаж товаров по месяцам:
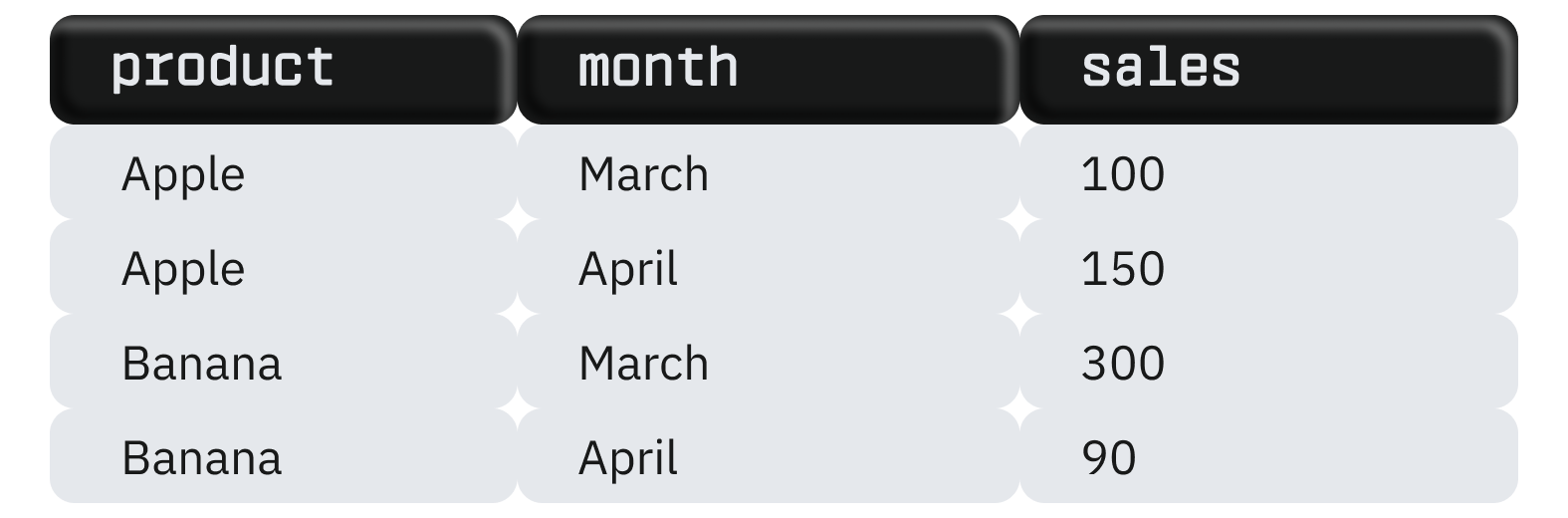
С помощью PIVOT таблицу можно изменить, превратив месяцы в столбцы:
SELECT product, [March], [April]
FROM sales
PIVOT
(
SUM(sales)
FOR month IN ([March], [April])
)
AS PivotTable;
Результат:
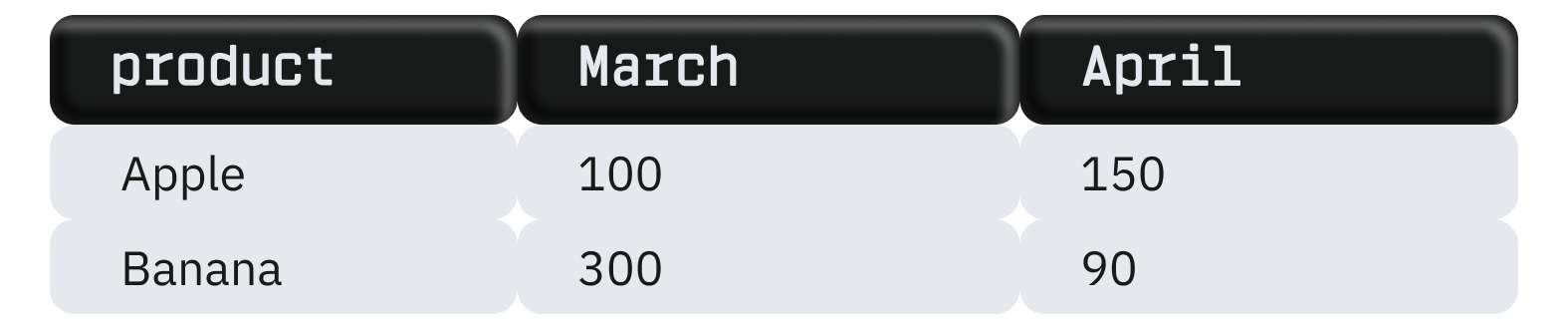
Оператор PIVOT имеет определенные ограничения в использовании:
- необходимо указать, какие значения должны стать новыми столбцами;
- оператор не может преобразовать строки в столбцы без применения агрегатных функций (
SUM, AVG, COUNTтощо); - некоторые типы данных не могут быть задействаны в
PIVOT— например, текстовые типы данных могут потребовать дополнительных преобразований или обработки; - поддерживается не всеми системами управления БД.
UNPIVOT
Используется для преобразования столбцов в строки, если нужен более гибкий анализ данных. Например, есть таблица с информацией о сумме выручки товаров по месяцам.
Нам нужна таблица, где сумма выручки будет в виде столбцов. На помощь придет оператор UNPIVOT.
Оператор UNPIVOT имеет определенные ограничения:
- разворачивает несколько столбцов в одну строку — преобразование нескольких независимых групп столбцов в строки одновременно придется выполнять с помощью нескольких запросов;
- требует одного типа данных для разворачиваемых столбцов;
- поддерживается не всеми системами управления БД.
7. Ускоряйте запросы с помощью индексов
Используйте индексы для быстрого доступа, сортировки и группировки данных в БД. Они работают подобно содержанию книги: позволяют быстро найти нужные строки без необходимости просматривать всю таблицу. Индексы могут значительно повысить производительность запросов, но важно знать, когда и как их применять.
Вот несколько советов по использованию индексов:
- создавайте индексы на строки, которые часто задействуются для фильтрации данных;
- применяйте индексы для первичных ключей
(PRIMARY KEY)— это защитит от дублирования значений; - ограничивайте количество индексов — их чрезмерное задействование может замедлить операции вставки
(INSERT), обновления(UPDATE)и удаления(DELETE), так как каждая из этих операций также должна обновлять индексы.
8. Оптимизируйте запросы
Во время работы с большим объемом данных вам как дата-аналитику, кроме точности выборки, важна еще и скорость обработки информации. Именно поэтому советуем оптимизировать запросы для повышения производительности вашей работы. Сделать это можно с помощью команды EXPLAIN и разумного применения SELECT *.
Команда SELECT * может извлекать ненужные вам данные и замедлять запросы. Вместо постоянного выбора всех столбцов указывайте только те, которые вам необходимы.
Команда EXPLAIN позволяет увидеть, как именно система управления БД планирует выполнить ваш запрос, предоставляя подробную информацию об использовании индексов, способах соединения таблиц и порядке обработки данных. Применяя EXPLAIN, вы можете понять, почему запрос работает медленно, и найти способы его оптимизации.
Чтобы воспользоваться командой EXPLAIN, добавьте ее перед вашим запросом. Результатом будет таблица с детальным планом выполнения.
EXPLAIN SELECT name, age
FROM users
WHERE age > 30;
9. Используйте эффективные команды соединения (JOIN)
Без команд объединения почти невозможно представить анализ большого объема данных. Чаще всего они необходимы для получения связанных данных из нескольких таблиц. Применяя неэффективные соединения, вы рискуете значительно замедлить запросы. В то же время владение методами объединения добавит информативности вашим запросам.
В SQL есть несколько типов команд JOIN:
INNER JOIN. Объединяет строки двух таблиц, возвращая только те записи, где есть соответствие между значениями в обеих таблицах. Если в обеих таблицах найдены строки с одинаковыми значениями, они будут включены в результат.LEFT JOIN / LEFT OUTER JOIN. Возвращает все строки из левой таблицы (первой указанной в запросе) и соответствующие строки из правой. Если в правой таблице нет соответствия, результат будет содержатьNULLдля ее столбцов.RIGHT JOIN / RIGHT OUTER JOIN. Возвращает все строки из правой таблицы (второй указанной в запросе) и соответствующие строки из левой. Если в левой таблице нет соответствия, результат будет содержатьNULLдля ее столбцов.FULL JOIN / FULL OUTER JOIN. Возвращает все строки, где есть соответствие или в левой, или в правой таблице. Если в обеих нет, то результат будет содержатьNULLдля отсутствующих значений из них обеих.CROSS JOIN. Возвращает декартово произведение двух таблиц. То есть каждая строка из первой таблицы соединяется с каждой строкой второй.SELF JOIN. Отдельный пример командыJOIN, когда таблица объединяется сама с собой. Полезно для анализа данных в таблицах, которые содержат иерархические отношения (например, сотрудники и их менеджеры).
Команда INNER JOIN обычно работает быстрее, поскольку возвращает только соответствующие строки из объединяемых таблиц. Но ее нужно использовать в зависимости от задачи, это не универсальное решение.
Убедитесь, что столбцам, которые участвуют в командах объединения, особенно внешним ключам, присвоены индексы.
10. Осваивайте работу с хранилищами и базами данных
Хранилища данных (Data Warehouses), в отличие от баз данных (Databases), лучше подходят для комплексных и сложных вычислений, необязательно обновляют информацию в реальном времени и могут содержать данные разной структуры. Работая в современных компаниях, вы чаще всего будете иметь дело именно с облачными хранилищами данных. Однако мы советуем научиться делать SQL-запросы как в локальные базы данных, так и в облачные хранилища.
Вы лучше поймете разницу в подходах к оптимизации запросов и особенностях обработки данных. Локальные базы данных требуют оптимизации под конкретное оборудование и структуру. Вам как аналитику полезно будет уметь работать в условиях ограниченного объема хранения и вычислительных ресурсов.
Облачные хранилища предлагают гибкость, масштабируемость и простой доступ к большим объемам данных из любого места. Однако для работы с ними нужно понимать особенности облачной архитектуры, стоимость обработки запросов и безопасность данных.
Вы можете, например, воспользоваться учебными материалами Google об SQL-запросах в их облачном хранилище.


11. Подготовьте данные для анализа
Эффективный анализ данных возможен только при их качественной подготовке. Умение стандартизировать и очищать данные от лишней информации не менее важно, чем владение эффективными SQL-запросами. Обратите внимание на изучение следующих операторов и попробуйте применить их на практике:
UPPERіLOWER— приводят значения строк к верхнему или нижнему регистру соответственно;REPLACE— заменяет указанные строковые значения на другое строковое значение (например, можно заменить ‘вул.’ на ‘вулиця’);SUBSTRING— возвращает указанный в команде фрагмент текста;TRIM— удаляет пробелы в начале и в конце строки;DATE_FORMAT— позволяет задать необходимый формат для даты и времени;CASE WHEN— преобразует данные в соответствии с условиями.
12. Применяйте образцы баз данных
Независимо от вашего уровня владения SQL, эксперименты с различными базами данных всегда помогут укрепить собственные навыки. Если вы начинающий аналитик, рекомендуем обратить особое внимание на образцы баз данных (Datasets). Они могут быть общими, финансово-экономическими, из сферы здравоохранения, E-commerce, SMM, с набором геопространственных данных и т. д. Каждая из них содержит различный набор данных, с которыми интересно и полезно поработать. Например:
- Northwind Sample Database — это классика для изучения SQL, поскольку имитирует БД небольшой вымышленной компании;
- AdventureWorks Sample Database — создана компанией Microsoft для демонстрации возможностей SQL Server. Отличный вариант БД для начинающих;
- World Bank Economic Data — это большой набор финансовых и экономических данных из стран мира, предоставленных Всемирным банком. БД будет полезна для анализа экономики и прогнозирования;
- CDC Datasets — содержат информацию, предоставленную Центром контроля и профилактики заболеваний (CDC), связанную с мониторингом заболеваний, эпидемиологией и общественным здоровьем. Может быть интересна для анализа и отслеживания тенденций в сфере здравоохранения.
13. Используйте ChatGPT
Думаем, что не удивим вас, но не пренебрегайте этой рекомендацией. ChatGPT может стать настоящим помощником в изучении и улучшении ваших навыков SQL. Его можно применять для:
- проверки SQL-кода;
- расшифровки сообщений об ошибках;
- объяснения, какой результат выдаст код или какие действия он выполняет;
- изучения различий между командами и принятия решения, какая из них лучше в вашем случае;
- «перевода» человеческого языка запроса на SQL-код.
Возможности ChatGPT не ограничиваются приведенными примерами. Вы можете легко дополнить его своим опытом и уже сегодня начать укреплять свои навыки SQL. Главное, помните, что ChatGPT может ошибаться и не всегда с первого раза выдавать необходимый результат. Дополнительно проверяйте информацию, переспросите его, предоставляйте больше контекста и задавайте четкие вопросы.

14. Форматируйте код
Эту рекомендацию можно считать универсальной для всех, кто пишет код. Правильное форматирование SQL-кода помогает сделать его более читабельным, понятным и легким для поддержки. Вот несколько основных принципов форматирования SQL-кода, которых стоит придерживаться:
Используйте верхний регистр для команд и операторов SQL
Хотя все редакторы кода обозначают команды и операторы другим цветом, применение верхнего регистра дополнительно выделит их на фоне другого текста:
❌ select, from, where, join, order by;
✅ SELECT, FROM, WHERE, JOIN, ORDER BY;
Разбивайте код на несколько строк
Благодаря этому его можно быстрее прочитать и понять суть.
❌
SELECT name, age FROM users WHERE age > 18;
✅
SELECT name, age
FROM users
WHERE age > 18;
Делайте отступы для вложенных запросов
Аналогично предыдущему пункту это улучшит читаемость кода.
❌
SELECT name
FROM buyers
WHERE id IN (SELECT user_id FROM orders WHERE product = ‘ноутбук’);
✅
SELECT name
FROM buyers
WHERE id IN
(
SELECT user_id
FROM orders
WHERE product = ‘ноутбук’
);
Выравнивайте операторы
Для сложных арифметических или логических запросов используйте отступы и выравнивание кода, а также переносите операторы на новые строки.
❌
SELECT name, age
FROM users
WHERE age > 18
AND city = 'Kyiv'
AND status = 'active';
✅
SELECT name, age
FROM users
WHERE age > 18
AND city = 'Kyiv'
AND status = 'active';
Добавляйте комментарии
Используйте комментарии, чтобы объяснить сложные блоки кода или его назначение. Это поможет и вам, если откроете код позже, и вашим коллегам разобраться с запросами.
В зависимости от редактора кода комментарии можно обозначать разными символами. Например, --, // или /* */ (для многострочных комментариев).
-- находим сотрудников с зарплатой выше средней
// находим сотрудников с зарплатой выше средней
/* находим сотрудников
с зарплатой выше средней */
SELECT name, salary
FROM employees
WHERE salary >
(
SELECT AVG(salary)
FROM employees
);
15. Самое главное — практика
Начинающим всегда сложно найти работу, ведь большинство работодателей интересуют практические навыки. Где же их взять, если не на работе? Можно воспользоваться специальными тренажерами, например, SQL Zoo. Обычно подобные ресурсы содержат разные задания по SQL для улучшения навыков формирования запросов и работы с данными.
16. Візуалізація даних
SQL позволяет делать запросы и получать в ответ необходимые данные. Все предыдущие советы были направлены на работу с информацией: подготовку, получение, фильтрацию, группировку и т. д. Но дата-аналитику нужно концентрироваться не только на получении необходимых данных с помощью SQL, но и на их визуализации.
Визуализация данных в SQL имеет решающее значение для понимания больших объемов данных и принятия решений. Именно поэтому рекомендуем уделить внимание освоению инструментов для визуализации и выбрать тот, который удовлетворяет ваши бизнес-потребности.
Например, это могут быть:
- Toucan — инструмент, который можно быстро интегрировать в любую БД. Имеет простой интерфейс и подходит для начинающих.
- Looker Studio является частью Google Cloud. Имеет собственный язык LookML для создания SQL-запросов и моделирования данных. Предлагает широкие возможности для визуализации.
17. Выберите удобный редактор кода
Существует много редакторов SQL-кода, каждый из которых имеет свои преимущества и особенности. Их назначение — помочь дата-аналитикам выполнять и оптимизировать SQL-запросы. Редакторы SQL упрощают работу с базами данных, обеспечивают удобную среду для написания кода, проверки и выполнения SQL-запросов. Они также могут:
- подсвечивать синтаксис для улучшения читаемости кода;
- подсказывать функции SQL, чтобы упростить написание кода;
- проверять код на наличие синтаксических ошибок;
- визуализировать результаты запросов.
Примеры редакторов кода:
- MySQL Workbench — официальный редактор от MySQL для управления MySQL-серверами и базами данных.
- DBeaver — универсальный бесплатный редактор для работы со многими типами баз данных;
- Visual Studio Code (VS Code) — созданный Microsoft для Windows, Linux и macOS. Считается легким редактором кода. Он не является самостоятельным специализированным инструментом для работы с SQL или базами данных. Однако с помощью расширений VS Code может поддерживать почти любой язык, включая SQL, Python, R и другие инструменты, которые часто используются в дата-аналитике.
Редакторов кода много. Все они обладают примерно одинаковой функциональностью, однако поддерживают работу с разными базами данных. Обращайте на это внимание, выбирая редактор для работы.
Надеемся, что наши советы помогут вам не растеряться в большом мире дата-анализа, а уверенно освоить его с помощью SQL.


