
Як працювати з SQL: 17 практичних порад аналітикам-початківцям
Ефективні техніки та інструменти
У сфері аналізу даних SQL (Structured Query Language — мова структурованих запитів) — це ключовий інструмент для роботи з базами даних. З його допомогою аналітики можуть швидко знаходити потрібну інформацію та легко з нею взаємодіяти.
SQL має інтуїтивно зрозумілий синтаксис, що робить його доступним навіть для новачків. Водночас його потужність і функціональність дають змогу досвідченим аналітикам працювати з даними на глибшому рівні. Набути базових навичок SQL нескладно, але, щоб по-справжньому його опанувати, може знадобитися час. Саме тому ми підготували 17 практичних порад, які допоможуть аналітикам-початківцям ефективніше працювати з SQL і швидше досягти професійного рівня.
1. Опануйте команду SELECT
Виділяють 5 видів SQL-запитів, з якими працюють дата-аналітики:
DDL (Data Definition Language) — мова визначення даних для створення та зміни структури БД (таблиці, схеми, індекси).
DCL (Data Control Language) — мова управління для надання або заборони доступу користувачам до даних в БД.
TCL (Transaction Control Language) — мова керування транзакціями. Забезпечує їхню цілісність та узгодженість.
DML (Data Manipulation Language) — мова маніпулювання даними для роботи з інформацією в наявних таблицях (додавання, оновлення, видалення).
DQL (Data Query Language) — мова запитів даних для їхньої вибірки з БД. Формально стосується DML, але часто відокремлюють через специфіку використання основної команди SELECT.
Оператор SELECT є основою SQL. Він витягує дані з однієї або кількох таблиць, використовуючи різні фільтри, сортування та об'єднання. Це оператор, з яким ви найчастіше працюватимете.
Команду SELECT можна доповнювати операторами:
WHERE— фільтрує дані за необхідною умовою;GROUP BY— групує дані за вказаними ознаками;HAVING— фільтрує дані за заданими критеріями, застосовують після групування;JOIN— об’єднує дані з декількох таблиць за допомогою різних типів з’єднань:INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN;LIMIT— обмежує кількість рядків у вибірці даних.
Оператор FROM
Оператор FROM є обов’язковим елементом у запитах SELECT і визначає, з якої таблиці (або таблиць) брати дані. Він задає основне джерело даних для запиту. У випадку використання кількох таблиць, FROM може працювати в парі з JOIN для об'єднання даних з різних таблиць на основі відповідних умов.
Приклади використання
#1. Вибір стовпців ‘name’ та ‘age’ з таблиці ‘users’.
SELECT name, age
FROM users;
#2. Вибір всіх стовпців з таблиці ‘users’ за допомогою *.
SELECT *
FROM users;
#3. Фільтрування даних за допомогою WHERE. Наприклад, нас цікавлять дані користувачів, яким понад 18 років.
SELECT name, age
FROM users
WHERE age > 18;
#4. Додатково можна комбінувати умови вибірки за допомогою логічних операторів AND, OR. Доповнимо попередній запит умовою, щоб користувачі були з Києва.
SELECT name, age
FROM users
WHERE age > 18 AND city = 'Kyiv';
Як бачите, оператор SELECT є основним інструментом для роботи з БД. Тому варто приділити достатньо часу її вивченню та використанню на практиці.
2. Використовуйте вкладені запити
Вкладений запит (підзапит) — це запит всередині іншого SQL-запиту, який розбиває складний процес вибірки або аналізу на менші кроки. Таким чином ви можете отримати дані, які простим запитом нереально було б виділити. Застосовуйте цей інструмент, щоб відкрити нові можливості у роботі з БД й додати гнучкості в процес вибірки. Потренуйтеся писати підзапити для різних сценаріїв, щоб максимально розкрити їх потенціал та розв’язувати складні завдання.
Приклади використання
- Отримання проміжних результатів
Вам потрібно вивести імена покупців, які придбали ноутбуки. Вкладений запит спочатку знаходить всіх користувачів, які замовили ноутбук (проміжний результат), а потім виводить їхні імена.
SELECT name
FROM buyers
WHERE id IN
(
SELECT user_id
FROM orders
WHERE product = ‘ноутбук’
);
- Фільтрування на основі агрегованих даних
Потрібно знайти працівників із зарплатою вище середньої в компанії. КомандоюSELECTзробити таке неможливо. Для цього процес треба розбити на 2 етапи: спочатку порахувати середню зарплату в компанії, а потім використати цей результат для пошуку відповідних працівників.
SELECT name, salary
FROM employees
WHERE salary >
(
SELECT AVG(salary)
FROM employees
);
Обмежуйте кількість вкладених один в одного запитів. Надто складні конструкції збільшують ризик помилки, і з часом ви навряд чи пригадаєте, які дані хотіли отримати. Та й колегам буде важко розібратися в такому коді. Також перевіряйте коректність виконання запитів на проміжних етапах, щоб відловити можливі помилки.
3. Використовуйте загальні табличні вирази (CTE)
Загальний табличний вираз CTE (Common Table Expression) — це тимчасовий результат або віртуальна таблиця, яку можна багаторазово задіювати в межах одного запиту. Аналогічно до вкладених запитів CTE застосовують для складних SQL-запитів. Перевагою CTE є можливість повторного використання без дублювання коду. Завдяки CTE структура ваших запитів буде чіткою та розділеною на логічні блоки.
Застосовуйте CTE у випадках:
- складного, багаторівневого запиту, який потребує проміжних обчислень;
- коли одну й ту саму вибірку або обчислення використовують кілька разів у межах одного запиту;
- коли потрібна рекурсія (рекурсивний CTE) — рекурсивні CTE посилаються самі на себе у своїх описах, що дає змогу працювати з ієрархічними або деревоподібними структурами даних.
CTE задає оператор WITH, і надалі на нього можна посилатися в командах SELECT, INSERT, UPDATE, DELETE або MERGE.
Приклад використання CTE
Припустимо, у нас є таблиця ‘employees’ зі стовпцями:
- id — унікальний ID працівника;
- name — ім’я працівника;
- department — назва відділу;
- salary — зарплата працівника.
В наведеному прикладі SQL-запиту CTE виконує обчислення середньої зарплати для кожного відділу з таблиці ‘employees’. Групує записи за стовпцем ‘department’, а результат обчислення та назви відділу зберігає у віртуальній таблиці ‘DepartmentAverageSalary’.
Основний запит використовує CTE для вибірки відділів, де середня зарплата вища за 5000, виводить назву такого відділу та його середню зарплату.
//CTE
WITH DepartmentAverageSalary AS
(
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department
)
//Основний запит
SELECT department, avg_salary
FROM DepartmentAverageSalary
WHERE avg_salary > 5000;
4. Зверніть увагу на віконні функції
Віконна функція (Winndow function) працює з виділеним набором рядків (вікном) та виконує обчислення для цього набору в окремому стовпці. Так звані «вікна» з набором рядків можуть розташовуватись у різних стовпчиках таблиці, але їх не потрібно попередньо групувати для проведення обчислень. На відміну від агрегатних функцій, які групують дані (GROUP BY), віконні функції обчислюють значення для кожного рядка окремо, дозволяючи використовувати як неопрацьовані, так і опрацьовані дані одночасно.
Найчастіше віконні функції застосовують для ранжування, кумулятивних обчислень, аналізу часових рядів, методу рухомого середнього та обчислення різниць між рядками. Використовуйте їх для спрощення аналізу великих наборів даних та підвищення ефективності своєї роботи.
Приклади віконних функцій:
ROW_NUMBER()— присвоює унікальний номер кожному рядку в межах вікна;RANK()— присвоює ранги рядкам у межах вікна, допускають однакові значення рангу для рядків з однаковим значенням;SUM(), AVG(), MIN(), MAX()— виконують агрегатні обчислення над визначеним вікном рядків;PARTITION BY— розбиває рядки на групи (вікна) для обчислення;ORDER BY— визначає порядок рядків у межах кожного вікна.

5. Працюйте з JSON
JSON (JavaScript Object Notation) — це зручний формат для зберігання, обробки, маніпулювання та обміну неструктурованими даними в SQL. Сьогодні дані надходять з багатьох джерел у різних форматах, тому JSON є незамінним інструментом для роботи з ними.
JSON дає змогу:
- зберігати й аналізувати дані, які мають різну структуру, зі збереженням їхньої повноти та зв’язків;
- легко імпортувати дані з різних джерел (зовнішні API, NoSQL БД, логи тощо);
- адаптувати модель даних до нових запитів.
6. Вивчіть оператори PIVOT і UNPIVOT
Трансформуйте таблиці, змінюючи структуру даних за допомогою операторів PIVOT і UNPIVOT.
PIVOT
Потрібен для перетворення рядків на стовпці, агрегації даних та представлення їх у зручнішому для аналізу форматі. Наприклад, є таблиця з даними продажів товарів по місяцях:
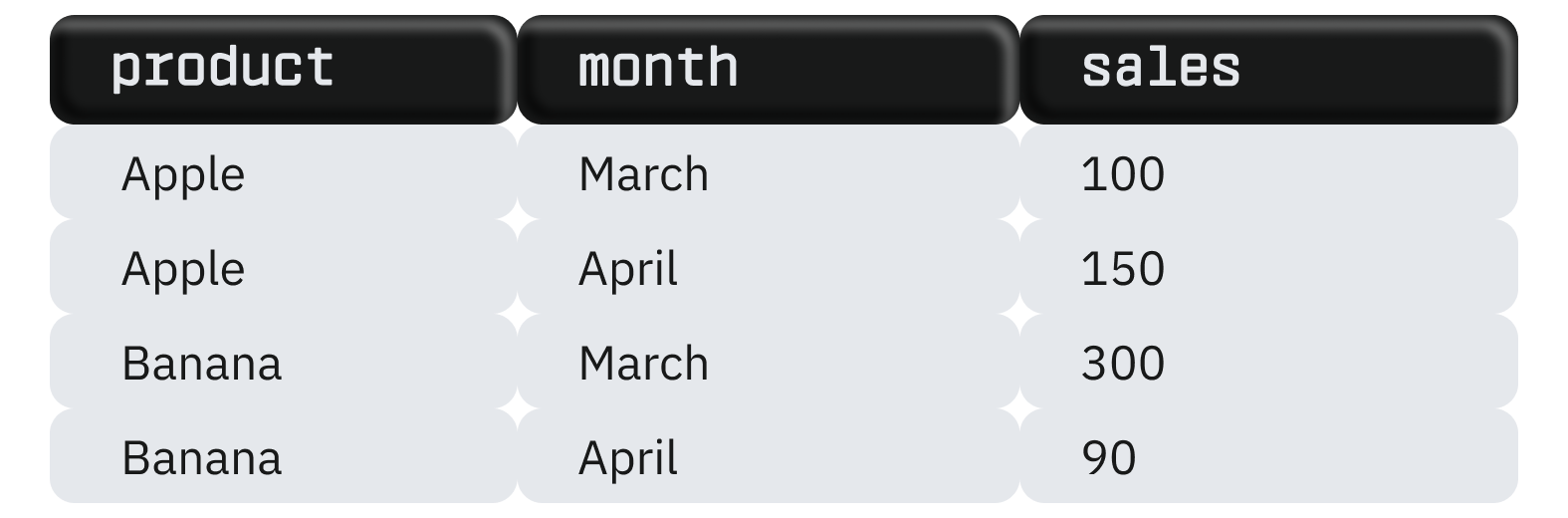
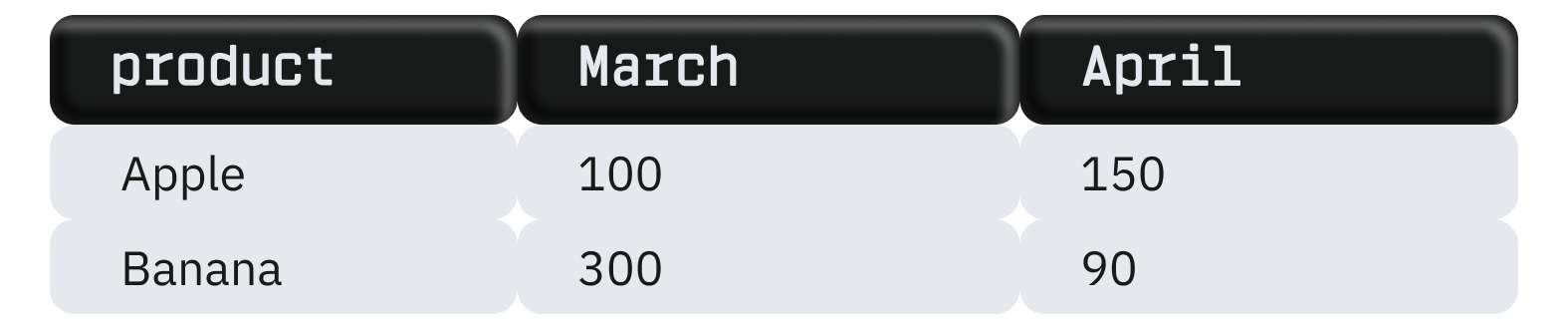
За допомогою PIVOT таблицю можна змінити, перетворивши місяці на стовпці:
SELECT product, [March], [April]
FROM sales
PIVOT
(
SUM(sales)
FOR month IN ([March], [April])
)
AS PivotTable;
Результат:
Оператор PIVOT має певні обмеження у використанні:
- необхідно вказати, які значення повинні стати новими стовпцями;
- оператор не може перетворити рядки на стовпці без застосування агрегатних функцій (
SUM, AVG, COUNTтощо); - деякі типи даних не можна задіювати в
PIVOT— наприклад, текстові типи даних можуть потребувати додаткових перетворень або обробки; - не всі системи управління БД підтримують.
UNPIVOT
Використовують для перетворення стовпців на рядки, якщо потрібен більш гнучкий аналіз даних. Наприклад, є таблиця з інформацією про суму виторгу товарів за місяцями:
Нам потрібна таблиця, де сума виторгу буде в ролі стовпчиків. На допомогу прийде оператор UNPIVOT.
Оператор UNPIVOT має певні обмеження:
- розвертає кілька стовпців в один рядок — перетворення кількох незалежних груп стовпців на рядки одночасно доведеться робити за допомогою декількох запитів;
- вимагає одного типу даних для стовпців, що розвертаються;
- не всі системи управління БД підтримують.
7. Прискорюйте запити за допомогою індексів
Використовуйте індекси для швидкого доступу, сортування та групування даних в БД. Вони працюють подібно до змісту книги: дозволяють швидко знайти потрібні рядки без потреби переглядати всю таблицю. Індекси можуть значно підвищити продуктивність запитів, але важливо знати, коли і як їх застосовувати.
Дамо вам кілька порад щодо використання індексів:
- створюйте індекси на рядки, які часто задіюють для фільтрації даних;
- застосовуйте індекси для первинних ключів
(PRIMARY KEY)— це убезпечить від повторення значень; - обмежуйте кількість індексів — їхнє надмірне залучення може сповільнити операції вставки
(INSERT), оновлення(UPDATE)та видалення(DELETE), оскільки кожна з цих операцій також повинна оновлювати індекси.
8. Оптимізуйте запити
Під час роботи з великим обсягом даних вам як дата-аналітику, окрім точності вибірки, важлива ще й швидкість обробки інформації. Саме тому радимо оптимізувати запити, щоб підвищувати продуктивність вашої роботи. Зробити це можна за допомогою команди EXPLAIN та розумного застосування SELECT *.
Команда SELECT * може витягувати непотрібні вам дані та сповільнювати запити. Замість постійного вибору всіх стовпців вказуйте лише ті, які вам треба.
Команда EXPLAIN дозволяє побачити, як саме система управління БД планує виконати ваш запит, надаючи детальну інформацію про використання індексів, способи з’єднання таблиць та порядок обробки даних. Застосовуючи EXPLAIN, ви можете зрозуміти, чому запит працює повільно, і знайти способи його оптимізації.
Щоб скористатися командою EXPLAIN, додайте її перед вашим запитом. Результатом буде таблиця з детальним планом виконання.
EXPLAIN SELECT name, age
FROM users
WHERE age > 30;
9. Використовуйте ефективні команди з’єднання (JOIN)
Без команд об’єднання майже неможливо уявити аналіз великого обсягу даних. Найчастіше вони необхідні для отримання пов’язаних даних з декількох таблиць. Застосовуючи неефективні з’єднання, ви ризикуєте значно сповільнити запити. Водночас розуміння методів об’єднання додасть інформативності вашим запитам.
В SQL є кілька типів команд JOIN:
INNER JOIN. Об’єднує рядки двох таблиць, повертаючи лише ті записи, де є відповідність між значеннями в обох таблицях. Якщо в обох таблицях знайдено рядки з однаковими значеннями, їх буде додано в результат.LEFT JOIN / LEFT OUTER JOIN. Повертає всі рядки з лівої таблиці (першої зазначеної в запиті) і відповідні рядки з правої. Якщо в правій таблиці немає відповідності, результат міститимеNULLдля її стовпців.RIGHT JOIN / RIGHT OUTER JOIN. Повертає всі рядки з правої таблиці (другої зазначеної в запиті) і відповідні рядки з лівої. Якщо в лівій таблиці немає відповідності, результат міститимеNULLдля її стовпців.FULL JOIN / FULL OUTER JOIN. Повертає всі рядки, де є відповідність або в лівій, або в правій таблиці. Якщо в обох таблицях немає, то результат міститимеNULLдля відсутніх значень з них обох.CROSS JOIN. Повертає декартовий добуток двох таблиць. Тобто кожен рядок з першої таблиці поєднується з кожним рядком другої.SELF JOIN. Окремий приклад командиJOIN, коли таблиця об’єднується сама із собою. Корисно для аналізу даних у таблицях, які містять ієрархічні відносини (наприклад, співробітники та їхні менеджери).
Команда INNER JOIN зазвичай працює швидше, оскільки повертає лише відповідні рядки з таблиць, що об’єднуються. Але її треба використовувати в залежності від завдання, це не універсальне рішення.
Переконайтеся, що стовпцям, які беруть участь у командах об’єднання, особливо зовнішнім ключам, присвоєно індекси.
10. Опановуйте роботу зі сховищами та базами даних
Сховища даних (Data Warehouses), на відміну від баз даних (Databases), краще підходять для комплексних і складних обчислень, необов’язково оновлюють інформацію в реальному часі й можуть містити дані різної структури. Працюючи в сучасних компаніях, ви найчастіше матимете справу саме з хмарними сховищами даних. Однак ми радимо навчитися робити SQL-запити як в локальні бази даних, так і в хмарні сховища.
Ви краще зрозумієте відмінності в підходах до оптимізації запитів та особливостях обробки даних. Локальні бази даних потребують оптимізації під конкретне обладнання та структуру. Вам як аналітику корисно буде вміти працювати в умовах обмеженого обсягу зберігання та обчислювальних ресурсів.
Хмарні сховища пропонують гнучкість, масштабованість і простий доступ до великих обсягів даних з будь-якого місця. Проте для роботи з ними потрібно розуміти особливості хмарної архітектури, вартість обробки запитів та безпеку даних.
Можете, наприклад, скористатися навчальними матеріалами Google про SQL-запити в їхньому хмарному сховищі.


11. Підготуйте дані для аналізу
Ефективний аналіз даних можливий лише за їхньої якісної підготовки. Вміння стандартизувати й очистити дані від зайвої інформації не менш важливе за розуміння ефективних SQL-запитів. Приділіть увагу вивченню перелічених операторів та спробуйте застосувати їх на практиці:
UPPERіLOWER— прописують значення рядків верхнім або нижнім регістром відповідно;REPLACE— замінює вказані рядкові значення іншим рядковим значенням (наприклад, можна замінити ‘вул.’ на ‘вулиця’);SUBSTRING— повертає вказаний в команді фрагмент тексту;TRIM— видаляє пробіли на початку та в кінці рядка;DATE_FORMAT— дає змогу задати потрібний формат для дати й часу;CASE WHEN— перетворює дані відповідно до умов.
12. Застосовуйте зразки баз даних
Незалежно від вашого рівня знань SQL, експерименти з різними базами даних завжди допоможуть підсилити власні навички. Якщо ви починаючий аналітик, рекомендуємо звернути особливу увагу на зразки баз даних (Datasets). Вони є загальні, фінансово-економічні, зі сфери охорони здоров’я, E-commerce, SMM, з набором геопросторових даних тощо. Кожна з них містить різний набір даних, з якими цікаво і корисно попрацювати. Наприклад:
- Northwind Sample Database — це класика для вивчення SQL, оскільки імітує БД невеликої вигаданої компанії;
- AdventureWorks Sample Database — створена компанією Microsoft для демонстрації можливостей SQL Server. Є відмінним варіантом БД для початківців;
- World Bank Economic Data — це великий набір фінансових та економічних даних з країн світу, наданих Світовим банком. БД буде корисною для аналізу економіки та прогнозування;
- CDC Datasets — містять інформацію, надану Центром контролю та профілактики захворювань (CDC), яка пов’язана з моніторингом захворювань, епідеміологією та громадським здоров’ям. Може бути цікавою для аналізу та відстежування тенденцій у сфері охорони здоров’я.
13. Використовуйте ChatGPT
Думаємо, що не здивуємо вас, але не нехтуйте цією порадою. ChatGPT може стати справжнім помічником у вивченні та покращенні ваших навичок SQL. Його можна застосовувати для:
- перевірки SQL-коду;
- розшифровки повідомлень про помилки;
- пояснення, який результат видасть код або які дії він виконує;
- вивчення відмінностей між командами та ухвалення рішення, яка з них найкраща у вашому випадку;
- «перекладу» людської мови запиту на SQL-код.
Можливості ChatGPT не обмежуються наведеними прикладами. Ви можете його легко доповнити на власному досвіді та вже сьогодні почати підсилювати свої навички SQL. Головне, пам’ятайте, що ChatGPT може помилятись і не з першого разу видавати потрібний результат. Додатково перевіряйте інформацію, перепитуйте його, надавайте більше контексту і ставте чіткі запитання.

14. Форматуйте код
Цю пораду можна вважати універсальною для всіх, хто пише код. Правильне форматування SQL-коду допомагає зробити його більш читабельним, зрозумілим і легким для підтримки. Ось кілька основних принципів форматування SQL-коду, яких варто дотримуватися:
Використовуйте верхній регістр для команд та операторів SQL
Хоча всі редактори коду позначають команди та оператори іншим кольором, застосування верхнього регістру додатково виділить їх на тлі іншого тексту:
❌ select, from, where, join, order by;
✅ SELECT, FROM, WHERE, JOIN, ORDER BY;
Розбивайте код на декілька рядків
Завдяки цьому його можна швидше прочитати й зрозуміти суть.
❌
SELECT name, age FROM users WHERE age > 18;
✅
SELECT name, age
FROM users
WHERE age > 18;
Робіть відступи для вкладених запитів
Аналогічно попередньому пункту це покращить читабельність коду.
❌
SELECT name
FROM buyers
WHERE id IN (SELECT user_id FROM orders WHERE product = ‘ноутбук’);
✅
SELECT name
FROM buyers
WHERE id IN
(
SELECT user_id
FROM orders
WHERE product = ‘ноутбук’
);
Вирівнюйте оператори
Для складних арифметичних або логічних запитів використовуйте відступи та вирівнювання коду, а також переносьте оператори на нові рядки.
❌
SELECT name, age
FROM users
WHERE age > 18
AND city = 'Kyiv'
AND status = 'active';
✅
SELECT name, age
FROM users
WHERE age > 18
AND city = 'Kyiv'
AND status = 'active';
Додавайте коментарі
Використовуйте коментарі, щоб пояснити складні блоки коду або його призначення. Це допоможе і вам, якщо відкриєте код пізніше, і вашим колегам розібратися із запитами.
Залежно від редактора коду коментарі можна позначати різними символами. Наприклад --, // або /* */ (для багаторядкових коментарів).
-- знаходимо працівників із зарплатою вище середньої
// знаходимо працівників із зарплатою вище середньої
/*знаходимо працівників
із зарплатою вище середньої */
SELECT name, salary
FROM employees
WHERE salary >
(
SELECT AVG(salary)
FROM employees
);
15. Найголовніше — практика
Початківцям завжди непросто знайти роботу, адже більшість роботодавців цікавлять практичні навички. Де ж їх взяти, якщо не на роботі? Можна скористатися спеціальними тренажерами, наприклад, SQL Zoo. Зазвичай подібні ресурси містять різні завдання з SQL для покращення навичок формування запитів та роботи з даними.
16. Візуалізація даних
SQL дозволяє робити запити й отримувати у відповідь потрібні дані. Всі попередні поради були спрямовані на роботу з інформацією: підготовку, отримання, фільтрування, групування тощо. Але дата-аналітику потрібно концентруватися не лише на отриманні необхідних даних за допомогою SQL, але й на їхній візуалізації.
Візуалізація даних в SQL має вирішальне значення для розуміння великих обсягів даних та ухвалення рішень. Саме тому радимо приділити увагу опануванню інструментів для візуалізації та обрати той, що задовольняє ваші бізнес-потреби.
Наприклад, це можуть бути:
- Toucan — інструмент, який можна швидко інтегрувати в будь-яку БД. Має простий інтерфейс та підходить для початківців.
- Looker Studio є частиною Google Cloud. Має власну мову LookML для створення SQL-запитів і моделювання даних. Пропонує широкі можливості для візуалізації.
17. Оберіть зручний редактор коду
Існує багато редакторів SQL-коду, кожен з яких має свої переваги та особливості. Їхнє призначення — допомогти дата-аналітикам виконувати та оптимізувати SQL-запити. Редактори SQL спрощують роботу з базами даних, забезпечують зручне середовище для написання коду, перевірки та виконання SQL-запитів. Вони також можуть:
- підсвічувати синтаксис для покращення читабельності коду;
- підказувати функції SQL, щоб спростити написання коду;
- перевіряти код на наявність синтаксичних помилок;
- візуалізувати результати запитів.
Прикладами редакторів коду є:
- MySQL Workbench — офіційний редактор від MySQL для управління MySQL-серверами та базами даних.
- DBeaver — універсальний безоплатний редактор для роботи з багатьма типами баз даних;
- Visual Studio Code (VS Code) — створений Microsoft для Windows, Linux й macOS. Вважають легким редактором коду. Він не є самостійним спеціалізованим інструментом для роботи з SQL або базами даних. Проте за допомогою розширень VS Code може підтримувати майже будь-яку мову, включно з SQL, Python, R та іншими інструментами, які часто використовують у дата-аналітиці.
Редакторів коду багато. Всі вони мають приблизно однакову функціональність, проте підтримують роботу з різними базами даних. Звертайте на це увагу, обираючи редактор для роботи.
Сподіваємося, що наші поради допоможуть вам не розгубитись у великому світі дата-аналізу, а вправно опанувати його за допомогою SQL.


