
«Мы обучаем систему принимать решения»
Владимир Кубицкий, Head of AI в ЛУН, о группировке объявлений, определении качества ремонта и борьбе с фейками.
В Flair — AI-команде компаний Flatfy и ЛУН — 6 человек: ML-инженеры, Python-разработчики, дата-менеджер. Также есть удаленные сотрудники, которые занимаются разметкой данных для алгоритмов. Командой руководит Владимир Кубицкий. Он рассказал robot_dreams, почему фасады мешают группировать объявления и как алгоритмы учатся оценивать качество ремонта.
Об особенностях ЛУН и Flatfy
Сначала ЛУН был агрегатором, который собирает объявления с сайтов недвижимости. Сейчас по такому принципу работает поисковик вторичной недвижимости Flatfy. После того как мы спарсили сотни тысяч объявлений, их нужно обработать, чтобы отобразить корректно: превратить сырые данные в качественную и удобную для пользователя информацию.
Одна из наших особенностей — это карта, на которой есть все объявления. Но важно склеить дубли объявлений с разных сайтов, потому что информация на них повторяется. ЛУН начался с этой идеи. Первыми у нас появились алгоритмы географического распознавания и дедупликации объявлений. На старте мы работали на эвристических алгоритмах, ручных правилах, MySQL-запросах. Сравнивали параметры двух квартир: на сколько процентов отличаются цена, площадь, другие показатели, и пытались запрограммировать критерии, по которым квартиры можно отнести к одной группе.
Так же и в вопросе географии: мы собрали геобазу (список всех домов и улиц) — и в объявлениях искали соответствие с ней. Эти подходы работали и позволили ЛУНу запуститься в 2008 году. Но сейчас мы применяем другие ML-решения и постоянно их улучшаем.
Что делать с фасадами
В 2014 году во время работы над улучшением группировки дублей мы столкнулись с тем, что люди добавляют в объявления фото фасадов домов. Если сравнивать фотографии внутри объявления, не зная, фасад на них или комнаты, то все объявления в Киеве «схлопнутся» до нескольких сотен домов на карте.
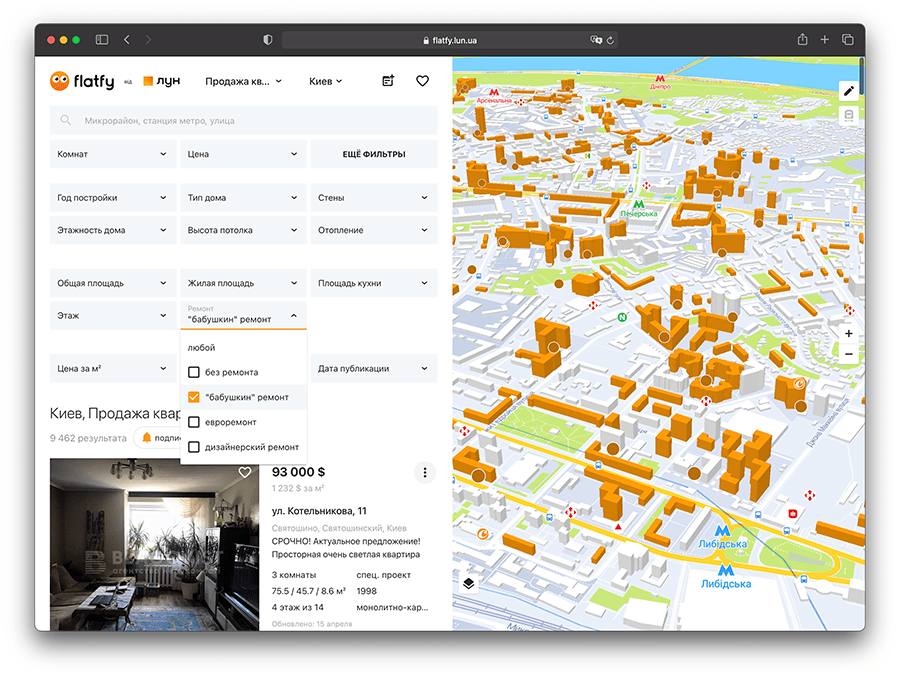
Примеры объявлений с фасадами
Нам нужно было отсеять фото фасадов при сравнении изображений в парах объявлений для дедупликации. Мы перепробовали много эвристических подходов, но нас не удовлетворяли результаты, поэтому мы продолжали «копать» эту задачу.
Тогда набирали популярность подходы на сверточных нейросетях. Появился фреймворк Caffe — Convolutional Architecture for Fast Feature Embedding от подразделений Berkeley Artificial Intelligence Research.
Семь лет назад мощностей для обучения подобных сетей с нуля в компании не было (пришлось бы потратить месяцы на проверку того, подойдет ли нам подобное решение).
Поэтому мы попросили предобученную модель на ImageNet у Berkeley, выбросили ее верхний слой и дообучили на своих данных, разбив все картинки на 7 категорий (в первый раз).
До применения сверточной нейросети лучший показатель точности классификации фасадов составлял 80%, а после — 97%. При этом алгоритм также научился определять кухни, ванные комнаты, изображения планировок.
С этого момента мы начали использовать ML-based подходы.
Как определить качество ремонта
Мы научили систему в ЛУНе оценивать субъективный параметр — качество ремонта. Этот алгоритм мы придумали для людей, которые знают, какие квартиры им не подходят.
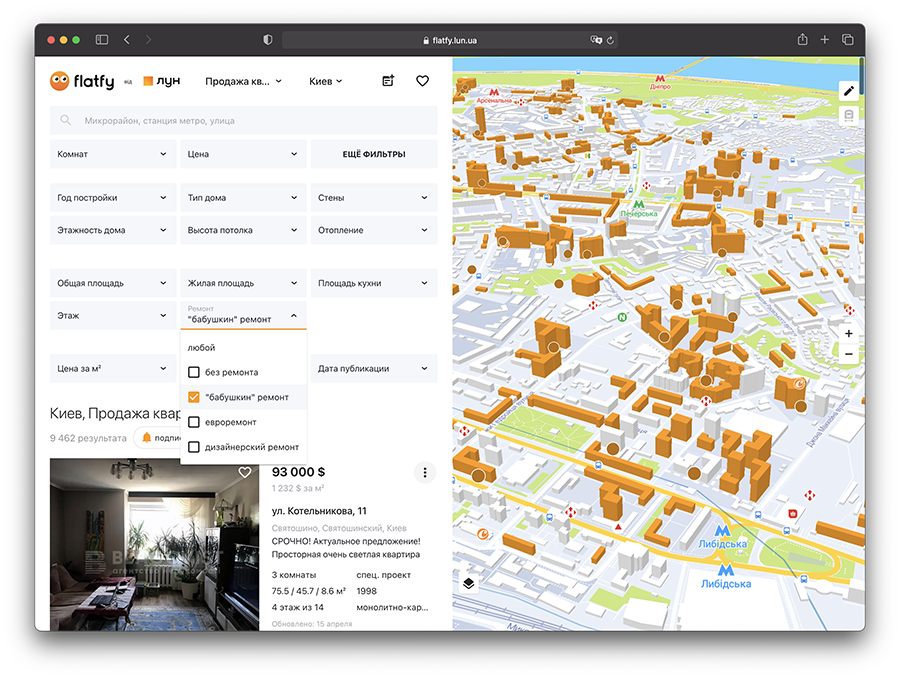
Фильтр для выбора качества ремонта
Собирая данные и обучая модель, мы столкнулись с трудностями. Например, было непонятно, как сформулировать критерии оценки качества для data-модераторов. Мы не смогли формализовать эту задачу, поэтому просмотрели множество фото квартир и, основываясь на них, создали для троих разметчиков примерную шкалу. Они разделили все фото на четыре категории, где 1 — голые стены, а 4 — суперсовременный ремонт. Это визуальные характеристики, в которых нет четких критериев.
По очень условным визуальным примерам мы собрали большую выборку и попытались обучить классификатор делать так же. Для этой задачи мы тоже используем каскад сверточных нейросетей: создаем выборку, подбираем архитектуру. Затем внутри системы происходит фиксация на признаках. Сверточные нейросети тяжело интерпретировать (установить, почему алгоритмы приняли такое решение). Но суть в том, чтобы отдать это решение самой сети. Ее эффективность сейчас составляет 82%. У группировщика объявлений, например, этот показатель выше 99,99%, но его мы улучшаем много лет, и он работает с более конкретной проблемой.
О коврах и первоапрельском фильтре
В 2018 году, когда мы начали работать над прототипом алгоритма по оценке качества ремонта, то заметили, что обычно в категорию совсем плохого ремонта попадали квартиры с коврами.
Мы решили сделать смешной фильтр к первому апреля: взять те данные, которые уже собрали для системы, дообучить на коврах и посмотреть, что выйдет. Потом мы прогнали через нейросеть всю нашу базу — 30 млн картинок. Добавили фильтр в интерфейс и запустили. Фильтр был в открытом доступе неделю, его точность составляла 99%. Чтобы проверить, размещен ли ковер на стене, мы доработали локализатор, который определял ковер как плоский (на полу) или прямоугольный (на стене) предмет.
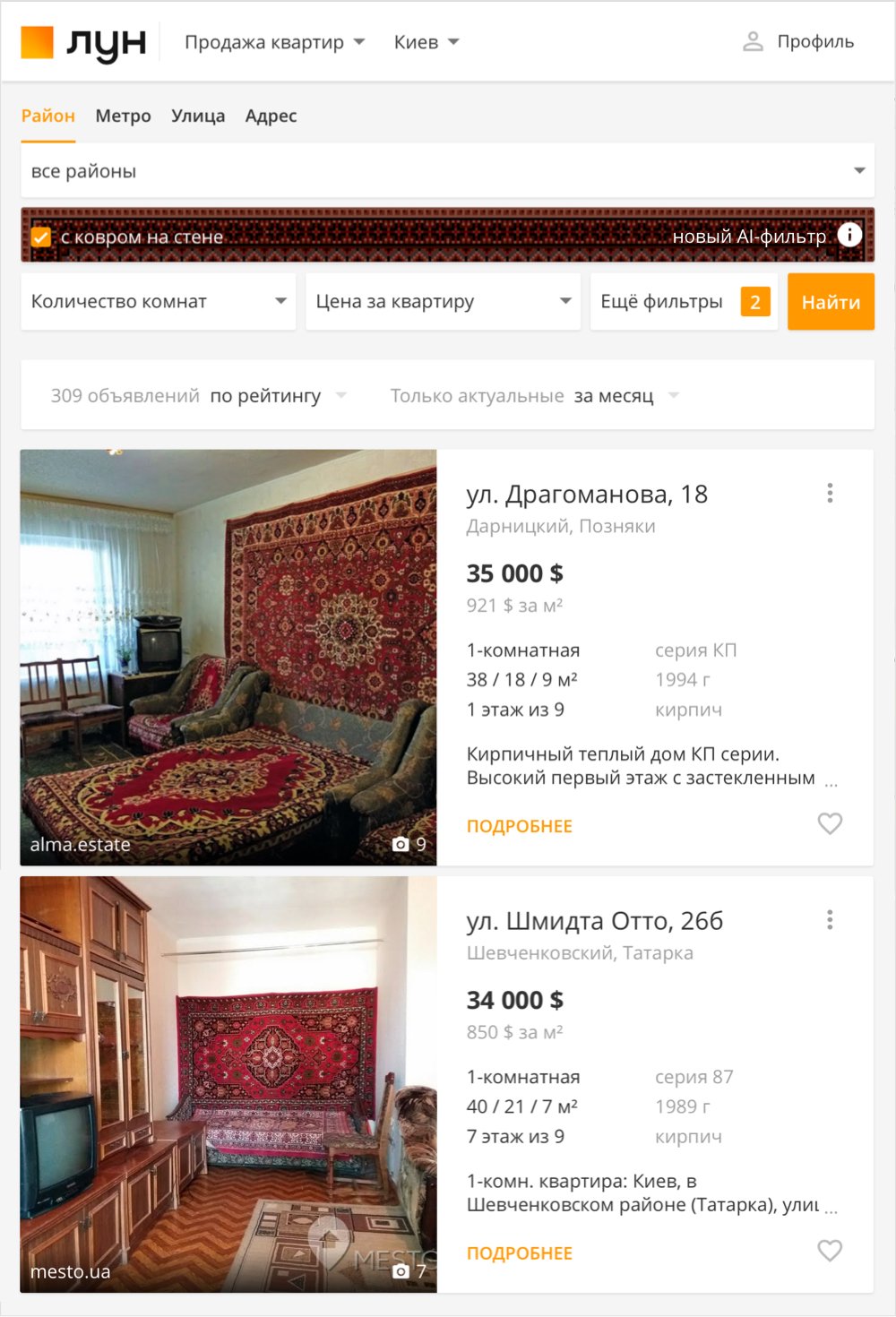
Фильтр, который показывал квартиры с коврами
Это не было спланированной рекламой, но идею подхватили. Об этом кейсе написали многие СМИ, люди активно пользовались фильтром и шерили информацию.
Сейчас у нас в Bird (iOS-приложении для аренды квартир в Киеве. — Ред.) есть фильтр «не бабцін ремонт», который отсекает все квартиры с «советским» стилем: коврами, сервантами. Если итоговая оценка не совпадает с критериями — объявление не отображается.
О фейках и посредниках
Мы боремся с фейковыми объявлениями на рынке аренды квартир — парсим выдачу поисковиков, чтобы понять, были ли украдены фото.
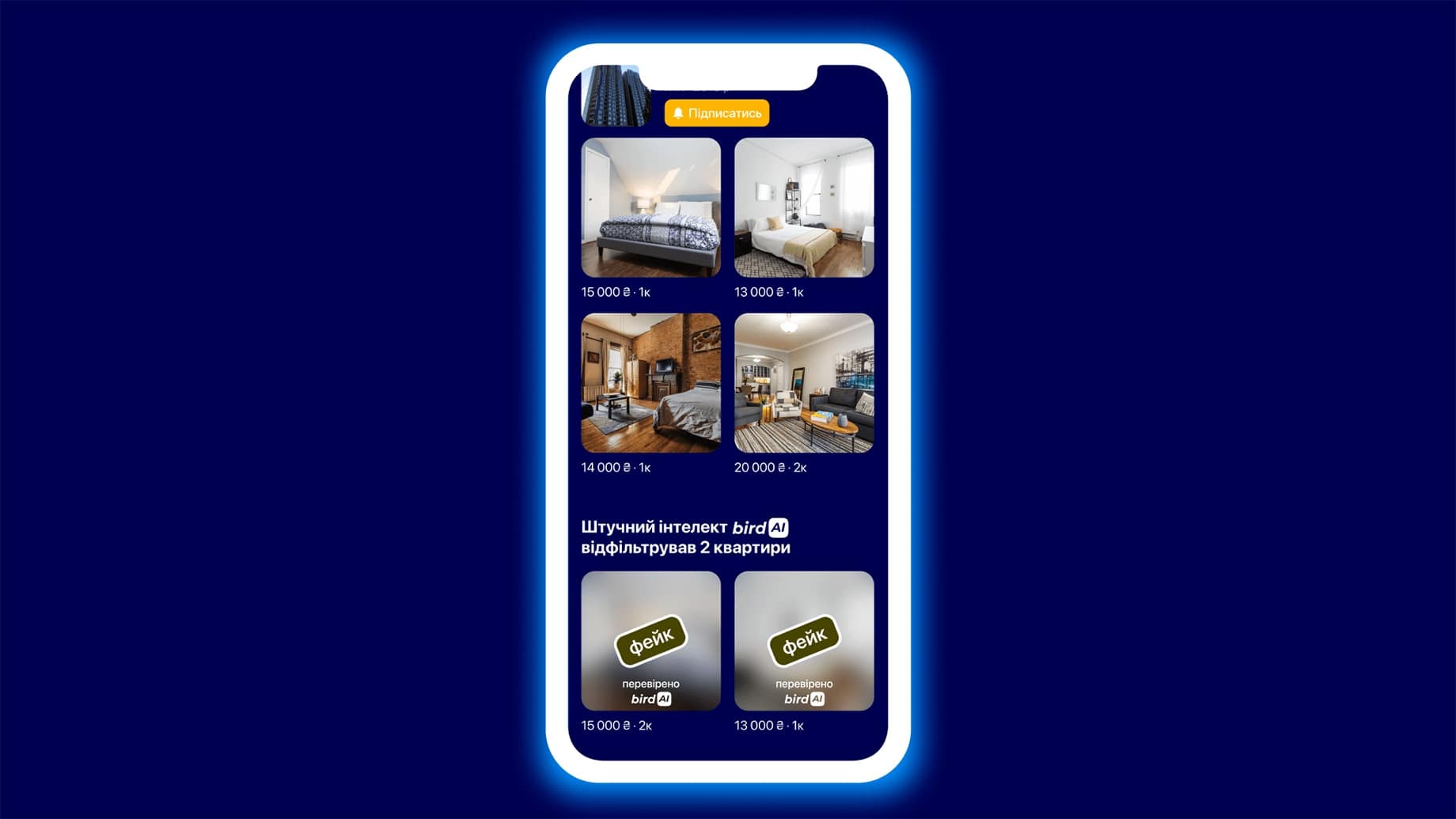
Отсев фейковых объявлений в Bird
В фейковых объявлениях часто публикуют рендеры, а не реальные снимки, поэтому мы построили классификатор, определяющий, что перед нами: дизайнерский рендер или реальное фото. Также мы анализируем, насколько реальной может быть цена за такую квартиру в этом ЖК в сравнении с рыночной стоимостью. Мы реализовали эту систему в поиске Flatfy и в Bird.
Кроме того, у нас есть фильтр, который удаляет посредников из выдачи. Алгоритм анализирует поведение автора и обращает внимание на частоту публикации объявлений, их количество и периодичность. Например, если у автора еще 300 объявлений в городе, маловероятно, что он владелец квартиры.
В фильтре мы также применяем анализ текста — сообщения риелторов часто однотипны. Если similarity score текстов разных объявлений одного автора высокий (больше 0,9), это один из признаков, что сообщение написано посредником.


Об анализе текста в объявлениях
Кроме фото, в объявлении обрабатывается и текст. Основная задача алгоритмов — распознать географию. Чтобы сопоставить адрес, который указан в тексте объявления, с точкой на карте, нам надо найти этот адрес в самом тексте, а затем смэтчить его с геобазой. Чтобы качественно находить кандидатов в геотокены из текста, мы построили систему экстракции, используя BertForTokenClassification. Flair собрал выборку текстов с размеченными геотокенами (названия городов, улиц, номера домов, ЖК). Объявление подают в систему, и она определяет, какие токены из текста являются информацией о местоположении. Затем мэтчер строит связь текстовых токенов с геобазой. Экстрактор и мэтчер также понимают типичные ошибки.

Пример работы системы экстракции
Мы использовали multilingual-модели из Bert и комбинации наших данных, собранных в разных странах, поэтому наша система мультиязычна (может работать с русским, украинским, английским, венгерским и другими языками).
Другая система — группировщик объявлений — проверяет, принадлежит ли текст разных объявлений одному автору. Здесь мы строим текстовые эмбеддинги и сравниваем их, чтобы установить similarity score — коэффициент похожести текста.
Среди алгоритмов работы с текстами есть разные классификаторы, например, «можно ли с животными». Сейчас мы занимаемся сбором данных для нового фильтра, который по тексту будет определять объявления, где аренда с животными возможна. Мы планируем создать классификаторы для других условий аренды, например, подходит ли объявление для аренды паре с детьми.
Все изображения предоставлены Владимиром Кубицким.


