
Что такое tidy data
Структурируем данные.
Дата-сайентисты говорят, что 80% времени тратят на подготовку данных, а на анализ — только 20%. Качественная информация позволяет построить эффективную модель и провести точные вычисления.
Рассказываем, в чем суть tidy data и как упростить структурирование данных.
Кто описал концепцию tidy data
Термин ввел дата-сайентист Хэдли Уикем в 2014 году.
Уикем — создатель нескольких десятков библиотек для языка R. В публикации для JSS (Journal of Statistical Software) он говорит, что tidy data (опрятные данные) — это стандартизированный способ соединить структуру набора данных и его семантику. Другими словами — физическое воплощение информации (например, в виде таблицы) и значения в наборе данных (числа, названия, номера, характеристики). Каждое значение определяется двумя параметрами — переменной и наблюдением. Переменная — это одна характеристика набора данных (например, возраст, город, профессия). Наблюдение — это группирование значений переменных по одному общему признаку. Например, информация об одном человеке.
В большинстве датасетов данные — в виде таблиц. Уикем называет три условия, при которых данные называют опрятными (tidy).
#1. Все переменные создают столбцы.
#2. Все наблюдения создают строчки.
#3. Каждый тип наблюдения создает одну таблицу.
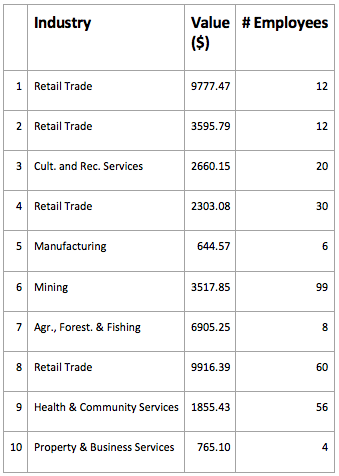
Источник: Displayr
Если любое из условий нарушено, то данные считаются неопрятными (dirty data).
Большинство задач дата-аналитиков сосредоточены на массивах информации, операции с которыми требуют разных инструментов и команд. Иногда обработку данных осложняют аномалии БД:
- модификации (изменение данных влияет на другие записи из таблицы);
- удаления (при удалении столбца пропадает информация, не связанная с ним напрямую);
- добавления (невозможность добавить информацию в базу).
Если формат данных правильный, аномалии не проявляются.
Использование инструментов, которые при обработке создают опрятные данные, сокращает время на рефакторинг БД. Его основная задача — упрощение работы c моделью без изменения функций. Обычно он необходим в работе с таблицами, в которых слишком большое количество строк или столбцов для баз конкретного типа либо содержится разнородная или несортированная информация. Большинство этих проблем устраняет tidy data.
Опрятные данные хорошо работают с R, потому что это векторный язык программирования. Информация в R сохраняется в виде кадров данных. Если ваши данные опрятны, показатели каждой переменной попадают в собственный вектор столбца.
Неструктурированные данные не выполняют одно или больше условий «опрятности». Уикем выделяет пять признаков беспорядочной информации:
- Единица наблюдения присутствует в разных таблицах.
Пример: в каталоге библиотеки информация о книге находится одновременно в таблицах «зарубежная литература» и «классика». - В одной таблице — много типов наблюдения.
Пример: в одном файле содержится и список книг, и список посетителей. - И в строках, и в столбцах записаны переменные.
Пример: в строках каталога, где содержится информация о названии книги, ошибочно указано издательство. Таким образом, сопоставляются две переменные, а не наблюдение и переменная. - В одном столбце — несколько показателей.
Пример: в столбце «автор книги» также есть информация о годе печати. - Заголовки столбцов — это значения, а не имена переменных.
Пример: в списке книг созданы столбцы «1997» и «1998», которые можно объединить в одну переменную — «год».


Как улучшить данные: R vs Python
Есть разные плагины для нормализации данных. Tidyverse — в десятке самых популярных библиотек для R. Ее тоже создал Хэдли Уикем.
Это библиотека с простым синтаксисом. Она похожа на язык SQL.
Tidyverse состоит из восьми пакетов: ggplot2, dplyr, tidyr, readr, purrr, tibble, strinf, forcatcs. Пакеты отличаются функционалом исполнения задач, но имеют общий дизайн, грамматику и структуру.
Например, ggplot2 используют для создания графики и визуализации данных, purrr — для работы с функциями и векторами, а tidyr — для нормализации опрятных данных.
Кроме того, у R есть собственный репозиторий с открытым кодом CRAN (Comprehensive R Archive Network) с 17 тыс. пакетов.
Основные функции для очистки данных в tidyr:
#1. Pivotting — функция преобразования данных из широкого формата в длинный и наоборот (с помощью команд pivot_longer() и pivot_wider()).
Функцию используют, например, в случаях, когда заголовки столбцов — не переменные, а их значения (в таблице — двенадцать столбцов с названием месяцев, хотя это одна переменная — год или дата). Используем команду pivot_longer(), чтобы «удлинить» таблицу и сократить число столбцов.
pivot_wider() применяют, если несколько переменных находится в одном столбце (например, данные о росте и весе не разделены). С помощью этой команды можно «расширить» таблицу.
#2. Fill — функция заполнения пробелов значениями из существующих записей столбца. Команда — Fill(). Для функции также можно задавать направление «вверх» или «вниз». Тогда автозаполнение будет использовать предыдущий или следующий показатель в столбце.
#3. Unite — функция, которая объединяет несколько клеток в одно поле, команда — unite().
#4. Separate — функция, противоположная unite. Команда separate() разделяет поле на несколько клеток.
#5. Nested data
Команда nest() создает столбец-список с фреймом данных из одной группы или таблицы. Таким образом можно сравнивать наборы данных, получить быстрый доступ к датасету или краткую справку об информации в нем. Команда unnest() раскрывает всю информацию о наборе.
В Python тоже можно структурировать данные, работая с библиотекой pandas.
Основные функции для очистки данных в pandas:
#1. Drop() — удаление лишних столбцов и рядов. Также с помощью функции можно удалять выборочную информацию. Для этого нужно прописать команду, чтобы устранить поля, которые содержат определенные метки. Например, числовые или текстовые показатели.
#2. Merge() — объединение информации из нескольких таблиц в одну.
#3. Stack() — это команда для «раскрытия» таблицы и конвертирования колонок в строки. Обратной является команда Unstack(), которая «сворачивает» строки в колонки.
#4. Melt() — функция, которая преобразует формат данных — из широкого в длинный.
#5. Pivot() — создание сводных таблиц. Применяя эту команду, можно группировать данные по переменным, создавая многоуровневые таблицы. Например, отобрать из каталога печатных изданий только ежегодные британские журналы о географии, используя параметры переменных.
Какой бы язык вы ни выбрали, создание опрятных данных сэкономит ваше время.


