
Нова ера в NLP: Як модель BERT усе змінила
Пояснює Data Scientist в YouScan
Два роки тому найкращі результати в обробці природної мови (NLP) показували багатошарові рекурентні або згорткові моделі. Як ембединги використовували вектори слів з наборів алгоритмів word2vec, fasttext або glove. Для кожного завдання тестували різний набір підходів, намагаючись підібрати найбільш відповідний.
Але відтоді в NLP-індустрії стався величезний прорив, завдяки якому сильно зросла якість на всіх типах завдань.

Віталій Радченко, Data Scientist в YouScan, розповідає, хто здійснив революцію в NLP, що таке трансформери й навіщо знадобився бенчмарк SuperGlue.
Типи NLP-завдань
Усі завдання в індустрії спрямовані на те, щоб спростити людям роботу. Наприклад, NLP використовують для автоматизації відповідей служби підтримки або визначення тональності згадки бренду в соцмережах.
Основні напрями NLP можна розділити на:
- завдання з класифікації (наприклад, визначення тематики тексту);
- завдання з машинного перекладу;
- відповідно-запитальні системи (чат-боти);
- summarization (для стислого викладу статей і автоматичної генерації прев’ю);
- пошук схожих текстів (наприклад, для визначення інфоприводів, перевірки запитань на Quora і подібних сервісах);
- складання тестів на основі наданого матеріалу та інші вузькоспеціалізовані завдання.
Найскладніше машинам розв’язувати завдання підтримання діалогу, розуміння контексту, відповідати на відкриті запитання (як на іспитах).
Ключові метрики NLP:
- Відсоток правильно проставлених міток для тексту. Мітки в цьому разі — будь-які теги (залежно від завдання). Наприклад, тональність, тематика, людина, географічні об’єкти.
- Правильне визначення меж відповіді у великому тексті. Алгоритму ставлять запитання, межі відповіді на яке потрібно знайти всередині тексту. Завдання має назву question answering. Його практичне застосування — пошук відповіді на юридичні запитання в тексті закону, на запитання про компанію в FAQ на сайті, пошук відповіді у «Вікіпедії».
- Схожість перекладу або згенерованого тексту із заданим, яку оцінюють за допомогою метрики BLUE. Що ближчий машинний переклад до людського, то краще.
Що таке трансформери
Трансформер — це архітектура, що ґрунтується на механізмі уваги (attention), завдяки чому модель звертає увагу на різні частини тексту і в такий спосіб краще вивчає закономірності, потрібні для розв’язання задачі.
У 2018 році розробник Джейкоб Девлін і його колеги з Google описали використання архітектури трансформерів для завдань NLP. Вони натренували велику мовну модель BERT і доопрацювали її для розв’язання різних завдань, у підсумку отримавши величезний приріст порівняно з попередніми SOTA-рішеннями. Це стало поштовхом для використання архітектури трансформерів у NLP.
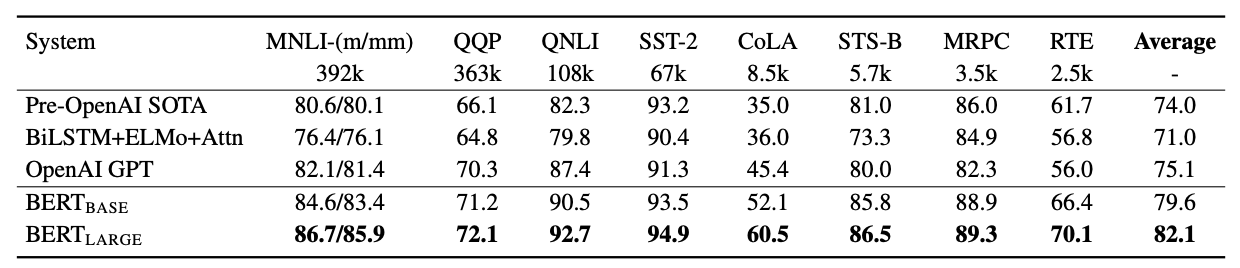
Результати BERT на бенчмарку GLUE / BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Безліч компаній і великих дослідницьких центрів почали розвивати технологію. З’явилися рішення від Facebook (Roberta), Baidu (Ernie), Google (T5) та інших. Вони відрізняються підходами до навчання мовних моделей, але в основі всіх із них — трансформери. Кожна дослідницька група намагається внести щось нове та вдосконалити попереднє найкраще рішення.
Наразі всі SOTA-розробки ґрунтуються на архітектурі трансформерів, тому що BERT спровокував інтерес і заклав фундамент для поліпшень. Старіші підходи, зокрема RNN і CNN, значно поступаються сучасним моделям.
За півтора року результати на GLUE-бенчмарку моделей перевершили результати людини. 87,1 % — середній показник для людей, а результати деяких моделей перевищують 90,5 %. До BERT’a ж найкращий показник становив близько 75 % (це середнє значення різних метрик, — ред.).
Але моделі досі недосконалі та в реальному житті справляються із завданнями гірше за людей. Тому розробники створили новий бенчмарк SuperGlue, до якого увійшли складніші завдання.
SuperGlue — основний opensource-бенчмарк для порівняння архітектур моделей. Він охоплює завдання на розуміння тексту і вживання слів у правильному контексті. Раніше для цих цілей використовували бенчмарк GLUE.


Крім того, завдяки бібліотеці Transformers від компанії Hugging Face поріг входу в NLP знизився. У Transformers є зручне API для використання сучасних pensource-архітектур, а також сховище ваг моделі. У ньому можна знайти ваги всіх відомих архітектур для різних мов і приклади їхнього використання. Наприклад, там є англійська GPT-2, українська Roberta або GPT-3 для російської мови.
Додаткова цінність цієї бібліотеки в тому, що ви можете подивитися реалізацію кожної з архітектур. Це допоможе розібратися в поліпшеннях, які зробили автори.
У майбутньому курсі ми, зокрема, розберемося в усіх SOTA-архітектурах і навчимося використовувати бібліотеку Transformers для різних NLP-завдань.
Обкладинка: Eleks Labs


