
Як United Tech перетворили творчий хаос на систему: Реальний кейс масштабування циклу SDLC
«Знайдіть мотивованих спеціалістів, дайте їм усе необхідне і не заважайте працювати»
SDLC (Software Development Life Cycle) — це основа створення програмного забезпечення, яка допомагає структурувати процес розробки та забезпечувати якість продукту. В компанії з українським корінням United Tech впровадження SDLC стало одним із ключових кроків у вдосконаленні робочих процесів.
Зважаючи на попередній досвід успішної розробки ПЗ, команда вирішила підійти до процесу системно: проаналізувати основні елементи SDLC, визначити метрики ефективності та знайти точки росту. Головним завданням стало створення вимірюваної системи, що дає змогу ухвалювати обґрунтовані рішення.
Які ж труднощі виникли під час масштабування і чому впровадження SDLC — це циклічний процес, до якого доводиться повертатися знову і знову, розповідає COO United Tech Ігор Буц.

На старті в нас не було чітких «вимог до вимог» або єдиного стандарту до завдань — усе працювало за принципом: «А зробімо ось так!». Поставлені завдання не мали чіткої структури, процес не був централізованим та прописаним покроково, тож більше нагадував творчий хаос.
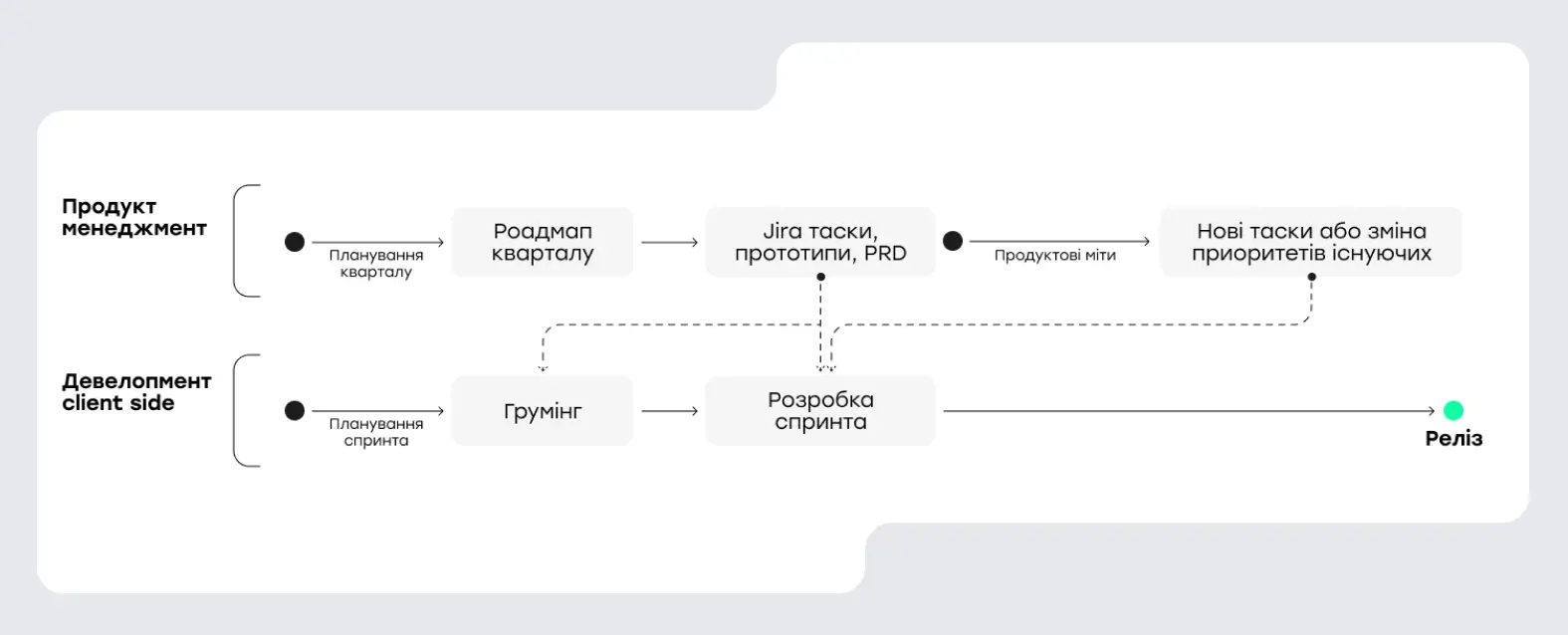
Для MVP чи тестування ринку такий підхід цілком виправданий: він дає швидкість і гнучкість. Ми оперативно ітерували ідеї, ухвалювали рішення за пів години на дзвінку й одразу бралися до роботи.
З часом, із масштабуванням, нарощенням процесів і збільшенням кількості завдань та людей, мінуси поступово ставали очевидними. Програмісти змушені були самостійно розбиратися, що саме треба робити, а нові нюанси виявляли вже в процесі кодування. Це призводило до зайвих правок, суперечливих рішень і навіть переписування бекенду під дедлайни, які палають, що негативно відбивалося на якості коду й архітектури. Водночас це був природний еволюційний розвиток, який допоміг команді адаптуватися й удосконалити підходи.
Гнучкість процесів: Agile, Kanban, Scrum
Може здатися, що відсутність SDLC дає швидкість, а сам SDLC не підходить для стартапів. Але це не так — життєві цикли розробки бувають різними. «Швидко» — це теж SDLC, просто з іншою структурою.
Ми протестували різні підходи до менеджменту, і кожен має свої плюси. Тому й досі використовуємо методології залежно від етапу розробки.
Чи є тут місце для Agile?
У 1970-х роках домінував Waterfall — підхід, де команди працювали за довгостроковими планами, які часто коригували через зміну темпу розробки. Це породило запитання: «Навіщо планувати на 5 років, якщо можна працювати ітераціями та швидше отримувати результати?».
Так з’явився Agile — методологія, що робить ставку на швидкість і гнучкість. Вона наголошує: люди важливіші за процеси, а документація не настільки критична, як регулярні постачання продукту. Agile — це не просто набір правил, а ціла філософія, побудована на кількох ключових принципах. Один із моїх улюблених: «Знайдіть мотивованих спеціалістів, дайте їм усе необхідне і не заважайте працювати».

Kanban і Scrum
Це два підходи, які ми використовуємо в роботі. Kanban, який застосовуємо на бекенді, не має жорстких вимірів і добре працює в умовах невизначеності, коли бракує часу на детальний аналіз. Його суть — проста дошка з картками-завданнями, де ми контролюємо їхнє накопичення та працюємо над «розчищенням».

Scrum — більш структурований підхід із чіткими циклами роботи «початок-кінець». Команда оцінює завдання, прогнозує терміни та вимірює ефективність. Наприклад, ми можемо аналізувати час, який завдання проводить у багфіксі, порівнюючи витрачені на нього ресурси з тривалістю виправлення помилок. Якщо завдання «застрягає» в багах і виправленнях — це сигнал покращити якість коду й оптимізувати кількість ітерацій.
Перша спроба структурувати розробку
Коли ми перевіряємо гіпотезу, яка може приносити гроші, важливо діяти швидко. Але після масштабування хаотичний підхід стає проблемою: кожна зміна на основі неякісних попередніх рішень коштує дорожче, а дрібні завдання затягуються на тижні. Виникає production hell, коли виправлення помилок займають більше часу, ніж сама розробка.
Щоб уникнути цього, ми створили власний шаблон Project Requirement Document (PRD), який містив блоки «обов’язково» та «опційно». Спочатку додавали аналітику й ризики, але зрозуміли, що на цьому етапі важливо зосередитися на чіткості вимог. Нашою метою було стандартизувати процес, щоб команда могла самостійно реалізовувати фічі, тестувати їх, випускати та вкладатися у відведений час.
На практиці впровадження PRD вимагало глибшої трансформації. Адже шаблони були, але звички їх заповнювати — ні. Зупинити розробку заради перебудови ми не могли, тож вибудовували систему «на ходу». Це стало викликом, але нам вдалося.
Ключовим фактором була залученість всієї команди. Без розуміння важливості процесу навіть найкраща система не працюватиме. Ми стандартизували вимоги, створили документацію — і хоч деякі проблеми лишилися, процес став значно ефективнішим.
Вплив змін на команду
Перед реалізацією змін я проводив індивідуальні дзвінки з кожним програмістом. Оскільки розробники мислять аналітично, їм легше працювати з чітко сформульованими завданнями, а не з абстрактними технічними вимогами.
Однак є й спеціалісти з ownership mindset — вони не просто пишуть код, а глибоко занурюються в продукт, аналізують конкурентів і розуміють вплив функцій на користувачів. У стартапах такі розробники безцінні, але знайти їх непросто.
Більшість програмістів працює у класичному стилі: вони добре читають документацію, дотримуються дедлайнів і чітко заданого плану. А от фахівців, що мислять, як продуктові менеджери, та ухвалюють стратегічні рішення, набагато менше — як на ринку, так і в нашій команді.
Проблеми взаємодії
Впровадження нового процесу стало викликом, особливо для розробників, оскільки їм бракувало відчуття справжньої команди. Формально вони працювали разом, але не мали внутрішнього зв’язку поза межами виконуваних завдань. Це була група окремих спеціалістів, а не єдиний механізм.
Реформуючи цикл розробки, ми змогли закласти основу командної культури. І поступово ця взаємодія почала працювати.
Хотілося б будувати команди за прикладом Spotify чи Netflix, але ці компанії мають великі ресурси та сильні HR-стратегії. Проте навіть у них це не відбувається швидко.
Тімліди відіграють ключову роль у цьому процесі. Вони не просто керують, а й стають наставниками для новачків, навчаючи їх не лише технічних навичок, а й любові до продукту. Це складний, але потрібний шлях, без якого неможливо побудувати сильну команду.
Виклики в процесі трансформації
Подолання scope creep
Однією з перших проблем, з якою ми зіткнулися, був scope creep — неконтрольоване розширення завдань під час спринтів. Ми домовлялися про конкретний обсяг роботи, але без чіткої системи фідбеку розробники не відстежували власну ефективність, що призводило до зривів дедлайнів.
Ситуація була типовою: спочатку команда затверджувала обсяг завдань, але під час спринту з’являлися нові вимоги, які всі приймали, не усвідомлюючи їхнього впливу на загальний процес. У підсумку частина роботи залишалася незавершеною.
Звинувачувати розробників у цьому було б неправильно — вони просто виконували поставлені завдання. Але відчуття відповідальності за кінцевий результат ще не сформувалося.
Наше завдання полягало в тому, щоб навчити команду бачити себе частиною великого механізму, де кожен не просто пише код, а впливає на загальний успіх продукту.
Організація urgent flow
Щоб уникнути хаосу термінових завдань, ми створили urgent flow — окремий процес для всіх нагальних запитів. Головне було пояснити команді відмінність між urgent і не urgent завданнями та узгодити загальні принципи роботи.
Без чітких критеріїв легко загрузнути в нескінченних «термінових» завданнях. Тому ми домовилися:
- Критичний баг у продакшні автоматично переходить в urgent flow, адже спричиняє збитки.
- Нова фіча, яка може приносити прибуток, але потребує покращень, вирішується топовим стейкхолдером. Якщо вона критично важлива, її допрацьовують одразу, якщо ні — переносять у наступний спринт.
Впровадження чіткої системи зменшило кількість термінових завдань на 90%. Якщо раніше вони з’являлися щодня, то зараз — раз на місяць. Це дає нам змогу захищати майлстоуни та ефективно керувати ресурсами, усвідомлюючи ціну кожного додаткового чи відкладеного завдання.


Побудова беклогу
Беклог став для нас єдиним джерелом актуальних завдань, яке потребує постійної пріоритезації. Економити на цьому час — означає втрачати контроль над процесом.
Раніше ми використовували квартальне планування, що більше підходить для стартапів. Але нам треба було централізоване місце, де зберігалися б усі завдання, фічі та активності — замість розкиданих таблиць і бордів.
Тому ми ввели чіткі правила:
- Як завдання потрапляють до беклогу.
- Як вони рухаються етапами.
- Хто відповідає за їхнє перенесення.
- Які дії виконує кожен учасник процесу.
Найскладнішим було не просто сформулювати ці домовленості, а домогтися їхнього безкомпромісного дотримання всією командою.
Візуалізація процесів та оптимізація
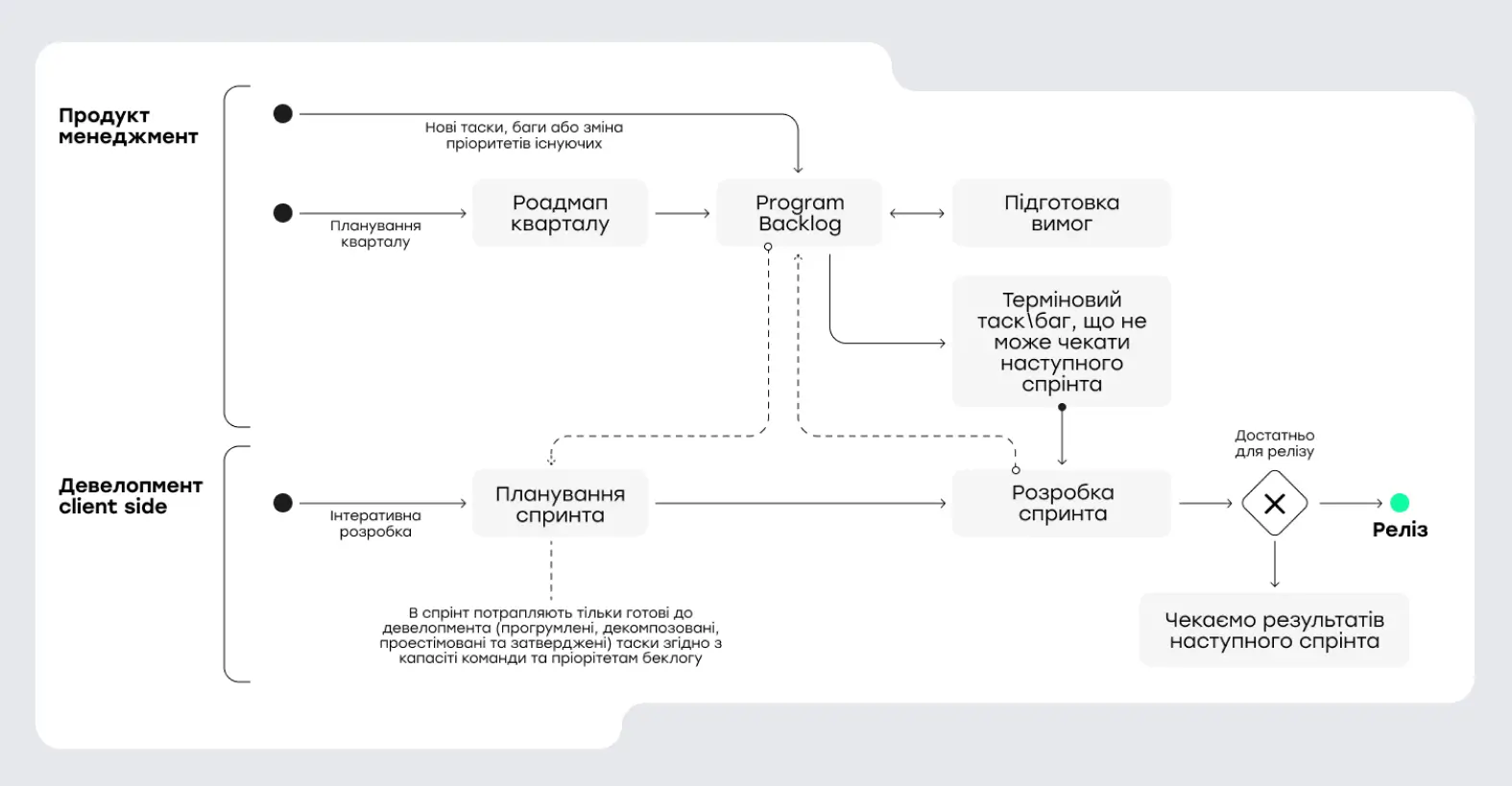
Під час роботи над беклогом ми вирішили візуалізувати процеси через BPMN (Business Process Model and Notation) — стандартний інструмент для опису бізнес-процесів. Я створив схему життєвого циклу розробки, порівнявши два варіанти: як було раніше та як має працювати надалі.
Спочатку ми мали три окремі гілки: продуктовий менеджмент, клієнтська розробка та бекенд. Що більше потоків, то більше проблем із комунікацією. Ми спростили модель до двох ключових напрямів: продуктовий менеджмент і розробка.
Намалювати схему було легко, а от донести її до команди й забезпечити реальне впровадження — вже виклик. Головне — не нав’язувати, а показати цінність змін і досягти єдиного розуміння.
Без підтримки СЕО чи СОО такі зміни важко втілити — вони просто загубляться в рутині. Ми провели багато мітингів і 1-на-1 розмов, щоб подолати упередження та покращити взаємодію між командами.
Сьогодні кожен спеціаліст знає свою зону відповідальності та дотримується спільних принципів роботи. Це потребувало (знову ж таки) часу, але тепер команда працює як єдиний злагоджений механізм.
Спроба структурувати розробку 2.0
Ми зробили все, щоб система запрацювала: намалювали схему, поділили ролі, створили беклог. Але коли повернулися до реалізації PRD, виникла нова проблема — поєднати їх написання з постійними релізами в умовах development hell.
Команда ледве встигала випускати кілька PRD на місяць, їхня якість була низькою, і розробники постійно хотіли повернутися до звичного стилю роботи. Після кількох невдалих спроб ми категорично домовилися підійти до цього процесу серйозно. Спільними зусиллями вдалося налагодити регулярний потік PRD.
Наступний виклик — прогнозовані спринти. Частину завдань естимували та декомпозували, а частину брали в роботу просто тому, що це було необхідно. Перші два-три спринти були найскладнішими: доводилося одночасно впроваджувати нові процеси, покращувати якість роботи й випускати релізи.
Оптимізоване планування спринтів
Раніше sprint planning займало 1–2 години, перетворюючись на розбір проблем, грумінг і суперечки. Тепер у нас є чітко підготовлений беклог, де всі завдання проестимовані, декомпозовані та пріоритезовані. Ми відкриваємо його, визначаємо капасіті команди, розподіляємо завдання — і все. Рекордне планування зайняло 15 хвилин.
Культура відповідальності
Розробники навчилися захищати свої кордони — більше не беруть зайві завдання просто тому, що їх ставлять. Це знизило напругу та покращило прогнозованість. Тепер вони відповідають за свої результати та дотримуються планування.
Баланс ресурсів і прогнозованість
Вимірювання всіх процесів стало рушієм змін. Раніше ми рахували капасіті через календарний час та кількість девелоперів, що не давало справжньої картини. Тепер аналізуємо дані попередніх релізів та ухвалюємо рішення на основі реальної ефективності команди.
Ми також виявили, що овертайми — це не показник ефективності, а симптом проблеми. Оптимізувавши процеси, вдалося знайти корінь причин, які змушували команду працювати понаднормово.
Data-driven підхід
Завдяки статистиці за кожним аспектом роботи ми оцінюємо ефективність не суб’єктивно, а мовою цифр. Програмісти мають власні метрики, які впливають на перегляд гонорарів. Очікувані показники визначені, і тепер кожен бачить реальні результати своєї роботи.
Експеримент з RACI-матрицею та розподілом ролей
Ми протестували RACI-матрицю та вирішили контролювати розробку через тімлідів, а не проєктних менеджерів. Це звучить нестандартно, але такий підхід вже успішно використовують у багатьох компаніях.
Ми помітили, що тімліди витрачали занадто багато часу на менеджмент, хоча їхня година роботи коштує вдвічі дорожче, ніж у PM. Тому мінімізували їхні управлінські завдання, щоб вони могли більше часу приділяти технічній роботі. Тепер розробники автономні, отримують завдання з PRD, а тімлід лише дає фідбек за потреби.
- Техлід відповідає за технічні питання: аналіз, декомпозицію, інтеграцію, технічний дизайн.
- Тімлід керує командою загалом, має ширші повноваження та глибше розуміє навантаження, проблеми та успіхи.
Ця структура допомагає оптимізувати процеси без залучення HR, оскільки тімлід сам у контексті всіх процесів. Ми автоматизували рутинні функції та полегшили контроль за спринтами. Чи було б нам краще з проєктним менеджером? Важко сказати, але зараз наша модель працює ефективно і ми не відчуваємо потреби в додатковому управлінському рівні.
Ownership-підхід та автономність команди
Відсутність «командира» дає змогу інженерам самостійно контролювати розробку, а не просто виконувати «накази». Спочатку це може бути схожим на додаткове навантаження, але коли команда розуміє «навіщо», вона працює ефективніше. Продуктові менеджери визначають пріоритети, а команда самостійно планує завдання та коригує навантаження.
З таким підходом легше масштабувати команду. Тімлід сам оцінює ресурси: якщо потрібно подвоїти темпи, він скаже, скільки фахівців потрібно та як розподілити завдання.
Після впровадження RACI-матриці тімліди почали переговори про підвищення, і в підсумку ми домовилися про справедливий рейз. Тепер на співбесідах одразу обговорюємо: «Більше відповідальності — вища оплата».
Це забезпечує прозорий та справедливий розподіл ролей.
Якщо підсумувати
Шляхом експериментів та спроб ми створили win-win систему, дотримуючись одного з головних принципів Agile — дали вмотивованій команді правильні інструменти, і це спрацювало.
Ще не все працює на 100% так, як задумано, але ми постійно вдосконалюємо процеси. В United Tech одна з ключових цінностей – розвиток і адаптація, тому ми свідомо йдемо цим шляхом. Замість сліпого наслідування практик ми оцінюємо власні ресурси та підлаштовуємо підходи під реальні потреби команди. Це дає змогу працювати ефективніше, ніж «за методичкою», зберігаючи гнучкість і результативність.
Автор: Ігор Буц


