
Рекомендації Spotify: хто та як визначає, що ви слухаєте
Адаптація матеріалу Wall Street Journal
Сервіс Spotify відомий завдяки персоналізованим плейлістам, які формуються за допомогою алгоритмів рекомендацій. Їх слухає понад 500 млн людей щомісяця, і дані про це є вихідним матеріалом, на основі якого можна створювати моделі.
Wall Street Journal розібрав, як цей сервіс використовує ШІ та дата-аналіз для персоналізації взаємодії з користувачами. Публікуємо для вас адаптацію цього матеріалу.
Як працює базове фільтрування та чому воно неідеальне
Spotify вийшов на сцену 2008 року, а вже у 2014-му він придбав музичну аналітичну компанію The Echo Nest, яка поєднала машинне навчання й обробку природної мови, щоби наповнити базу даних пісень і виконавців. Spotify зазначає, що ця технологія стала важливим кроком в еволюції системи рекомендацій.
Створення цієї системи починається зі спільного фільтрування (collaborative filtering). Воно дає змогу виявити шаблони, щоби з’ясувати, наскільки часто композиції трапляються поряд у списку відтворення. Це можна назвати побудовою карти музики й подкастів (map of music and podcast). Карта має приблизно такий вигляд, але насправді в ній більше вимірів, ніж на цьому зображенні:
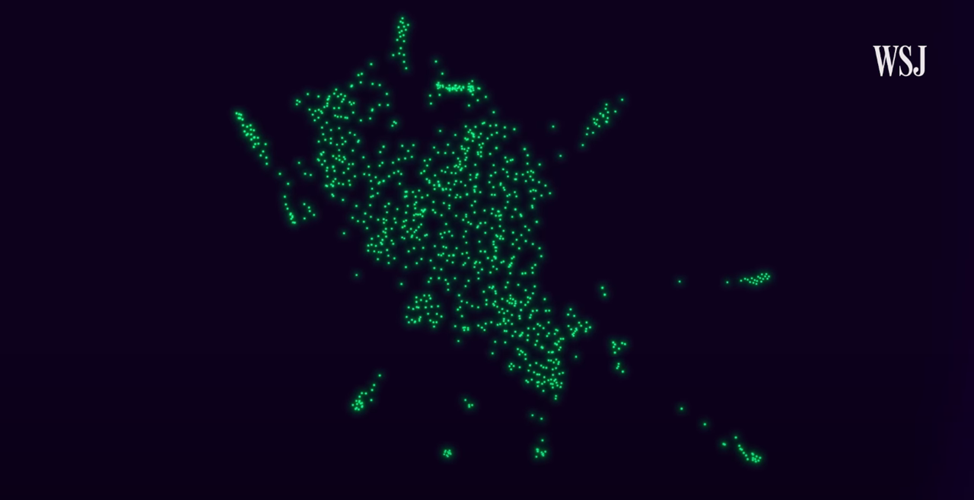
Карта музики та подкастів Spotify // Source: WSJ
Кожна точка представляє окремий трек у каталозі Spotify. Деякі треки трапляються поряд, тому що користувачі так розміщували їх у списках відтворення чи прослуховували один за одним. Отже, якщо дві пісні часто трапляються в одному й тому самому списку відтворення, то вони будуть розташовані близько одна до одної.
Але рекомендації, які засновано виключно на спільному фільтруванні, не є ідеальними.
Наприклад, під час свят пісня All I Want For Christmas Is You може потрапляти в список відтворення разом із Silent Night частіше — попри те що All I Want… звучить як pop-пісня:

…а Silent Night — як різдвяна:

Якби Spotify створював рекомендації з огляду лише на близькість треків на карті, то користувачам, яким подобається Мерайя Кері, могла б бути запропонована пісня Silent Night, хоча різдвяні пісні їх не цікавлять.
Додатковий рівень аналізу контенту
Аби запобігти цьому, Spotify додає ще один рівень аналізу, який називається фільтруванням на основі вмісту (content-based filtering). Цей алгоритм збирає метадані, зокрема про дату випуску та лейбл, і проводить аналіз необробленого аудіо. Щоб описати звукові характеристики треку, він використовує такі показники, як придатність для танців і гучність.
Ось результати для пісні Uptown Funk — вона має рейтинг придатності для танців 0,856 (за шкалою від 0 до 1):
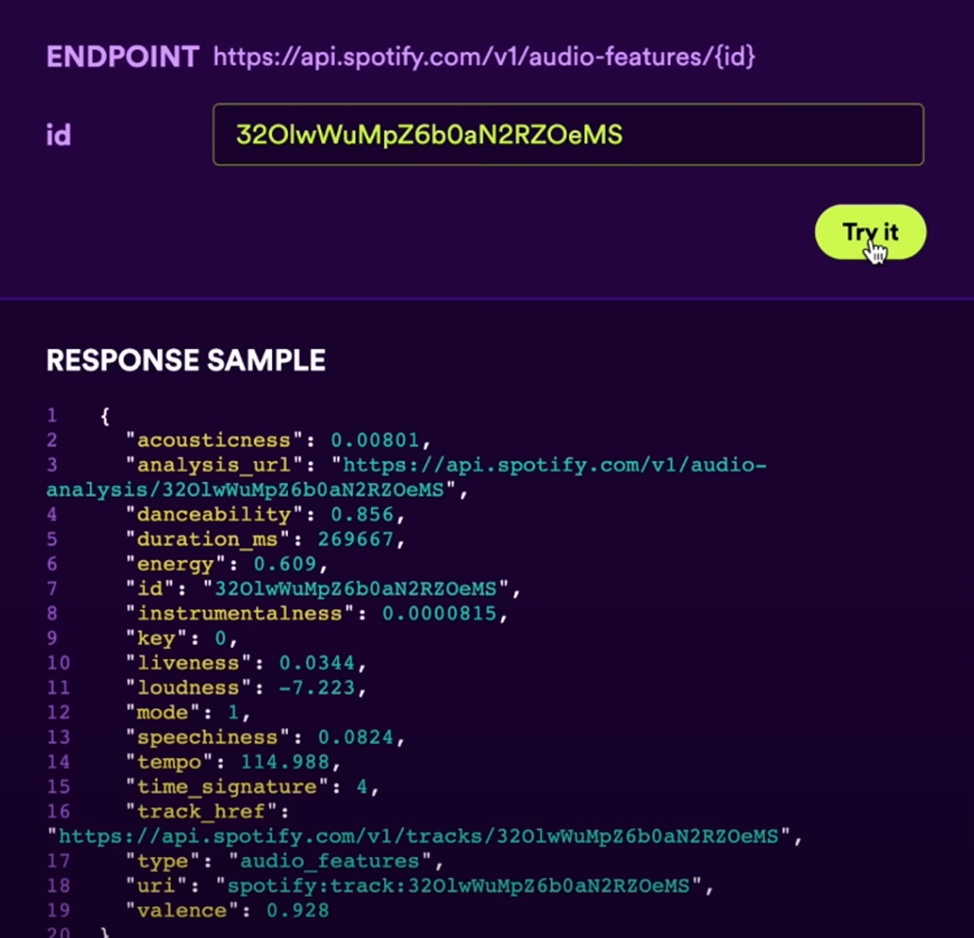
Source: WSJ
Також алгоритм аналізує часову структуру кожного треку. Ось візуальне представлення цього для пісні Taylor Swift Anti-Hero — на ньому зображені долі, такти й ноти:
Source: WSJ
Також під час фільтрування на основі вмісту враховується культурний контекст. Для цього вивчаються тексти пісень і здійснюється аналіз прикметників, які використовуються для опису треку в статтях і блогах.
Важливо! Ці методи фільтрування не є унікальними для Spotify. Те, що відрізняє платформу від інших, — це кількість користувацьких даних, які вона має, і продукти, які вона створює на основі цих даних.
Проблеми рекомендацій Spotify
Музикознавець та ШІ-дослідник Томас Годжсон (Thomas Hodgson) каже, що небезпека алгоритмів у тому, що вони можуть посилити наявні похибки. Наприклад, до певного музичного каталогу може увійти більше виконавців, ніж виконавиць. А коли слухачі починають взаємодіяти із цим каталогом, такі похибки збільшуються — і це створює так званий ланцюг зворотного зв’язку.
Також алгоритм Spotify не оптимізовано для нових виконавців — якраз через відсутність користувацьких даних. Це відомо як проблема холодного запуску. Голова Spotify з персоналізації Зіад Султан (Ziad Sultan) каже, що саме в цій ситуації редактори відіграють важливу роль у наданні рекомендацій:
«Вони, мабуть, одні з найкращих людей у світі, які намагаються зрозуміти нові релізи, культуру та те, що актуально».
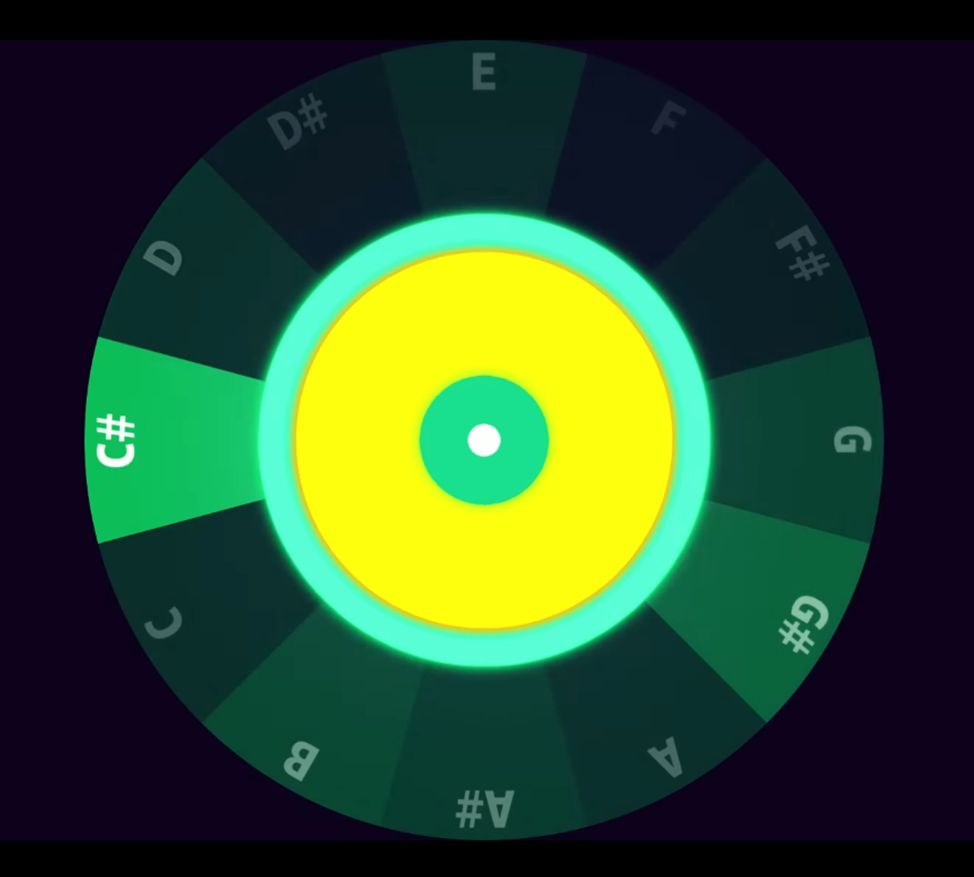
Але Годжсон зазначає: найбільше занепокоєння спричиняє те, що на певні показники, які використовуються для аудіоаналізу, можуть впливати культурні похибки. У різних частинах світу музичні системи та музичні культури зовсім різні. За приклад можна взяти північноіндійську мелодію:
Алгоритм Spotify визначає її тональність як мі мінор, що, на думку Годжсона, не підходить для цієї музичної традиції. Проте музика, яка народжена в Південній Азії, виявляється зрозумілою для алгоритмів за західною шкалою з розділенням октави на рівні інтервали.
Також деякі галузеві експерти вказують на проблеми з тим, як система розуміє метадані для класичної музики — вони можуть містити не лише назву твору та ім’я виконавця, а й темп, номер опусу та ім’я диригента, проте алгоритм Spotify для цього не оптимізовано.
До речі! Apple Music, яка в останні роки стала конкурентом Spotify, у березні випустила новий застосунок — Apple Music Classical, який розроблено для розв'язання цієї проблеми.
Плани Spotify щодо ШІ на майбутнє
У лютому Spotify торкнувся нещодавній шум навколо генеративного ШІ. Було створено віртуального діджея, який надає алгоритму людський голос і пропонує слухачам додатковий контекст для рекомендації:

Султан каже, що компанія досліджує і навчання з підкріпленням — технологію, яка дозволить системі рекомендацій навчатися автоматично на основі відгуків. Це допоможе забезпечити різноманітність рекомендацій і довгострокове утримання слухачів.


