
Функция потерь, n-граммы и эмбеддинг
Объясняем сложные термины из machine и deep learning.
Специалисты по data science занимаются «выпасом данных», создают жадные алгоритмы, считают функции потерь. Рассказываем, что это значит.
Классическое машинное обучение
#1. Data wrangling
Популярный вариант перевода — «выпас данных». Название появилось по созвучию с ковбоями (wrangler), которые ищут пропавших лошадей.
Data wrangling — это процесс, который включает:
- очистку данных (удаление ошибочных значений);
- приведение данных к одному формату (например, перевод в одинаковые единицы измерения);
- агрегацию данных (например, использование переменной «количество кликов у посетителя сайта» вместо информации по каждому клику);
- нормализацию данных;
- парсинг сложных структур данных (например, DOM-дерева сайтов);
- соединение разных групп данных по ключу;
- работу с пропущенными данными;
- дополнение данных из открытых источников (например, погодных данных);
Выполнять data wrangling можно с помощью разных инструментов, например, Pandas, OpenRefine и Trifacta Wrangler.
#2. Жадный алгоритм
Основной принцип алгоритма — выбор самого выгодного решения на каждом этапе работы. Он легко программируется, но подходит не для всех задач, потому что не просчитывает результаты следующих операций. Например, если нужно найти самый длинный путь на дереве, то жадный алгоритм на каждом шаге выбирает ветку с наибольшим весом.
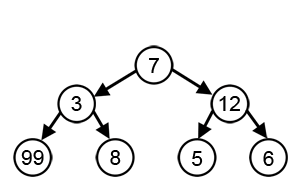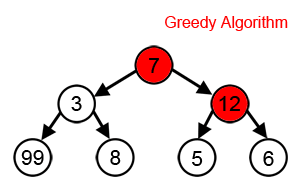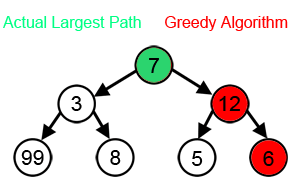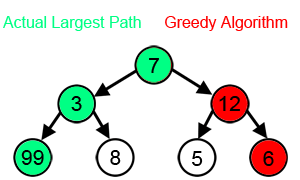
Источник: Wikipedia
При этом многие деревья решений построены на нем. Кроме того, жадный алгоритм крайне быстр и не требует больших вычислительных мощностей. Он применяется в системах обучения с подкреплением (reinforcement learning).
#3. Мета-алгоритм
Это часть мета-обучения — области ML, которая использует для обучения данные других алгоритмов. Алгоритм может придавать разный вес поведенческим моделям в зависимости от количества верных ответов или успешного выполнения задачи.
Простой пример мета-алгоритма — «комитет большинства», который используется для задач классификации. Результатом работы комитета считается тот вариант, за который проголосовало больше всего отдельных алгоритмов;
Основные классы мета-алгоритмов:
- бэггинг (тренировка большого количества моделей одинаковой архитектуры на разных подмножествах данных);
- бустинг (каждый следующий алгоритм учится находить слабые места предыдущего и исправлять их).
#4. Функция потерь
Чтобы оценить ML-алгоритм, нужно вычислить, насколько результат его работы далек от ожидаемого. Эту задачу решает функция потерь. Она определяет расстояние между фактическим выходом алгоритма и ожидаемым.
Чем меньше результат, который выдает функция потерь, тем лучше. Но если он близок к нулю, это значит, что результаты прогнозирования нейросети совпадают с ожидаемыми результатами. В реальности это невозможно.
При решении задач регрессии в качестве функции потерь используют среднюю квадратическую ошибку (MSE). Это разница между прогнозируемым значением и истинным, возведенная в квадрат и усредненная по всему набору данных. Самая простая функция потерь в задаче классификации — точность (процент правильно угаданных меток).
Deep learning
#1. N-грамма
Это непрерывная последовательность трех или более элементов. Элементы могут быть разными: звуки, символы, слоги, чаще всего — слова. С помощью n-грамм в нейролингвистике считают словосочетания или анализируют большие массивы текстов для обнаружения закономерностей и кластеризации данных. Также n-граммы используют при оценке уникальности текста.
Полезное применение n-грамм разработали в Google. Сервис Google Books Ngram Viewer визуализирует частоту применения n-грамм во всех оцифрованных источниках в Google Books.
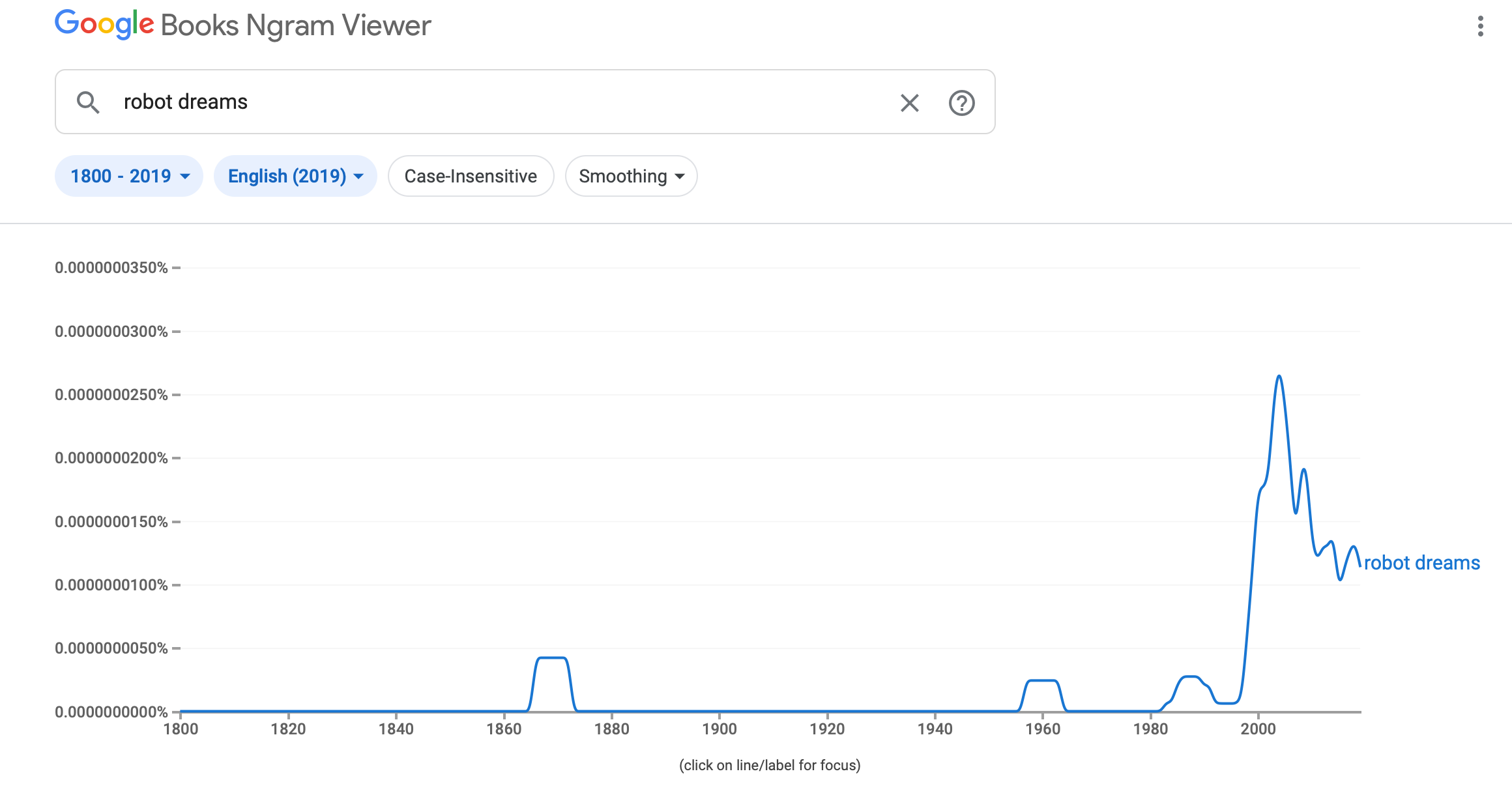
Пример работы сервиса
#2. Sequence-to-sequence
Специальный класс архитектур с периодической нейросетью, которые обычно используют для машинного перевода или создания чат-ботов. На входе seq2seq принимает одну последовательность элементов (чаще — слов), а на выходе — возвращает другую.
Sequence-to-sequence состоит из энкодера и декодера. Обычно это рекуррентные нейросети (RNN). Информация в RNN передается в разных направлениях и в произвольные временные отрезки. Энкодер обрабатывает входящую информацию и переводит в вектор контекста. После обработки информацию получает декодер, который генерирует выходную последовательность.
#3. Сверточные нейросети (CNN)
Это класс алгоритмов глубинного обучения, главные элементы которых — сверточный слой и слой пулинга. Сверточный слой можно представить как функцию, принимающую на вход небольшую квадратную часть изображения, (обычно 3х3 или 5х5), и возвращающую число, которое рассчитывается как сумма значений пикселей, умноженных на определенные веса. Такая функция называется функцией свертки. Она последовательно проходит по всем зонам исходного изображения (от квадрата 3х3 в левом верхнем углу до такого же квадрата в правом нижнем), и формирует новое, «подсвечивающее» детали, определяемые видом конкретной функции свертки.
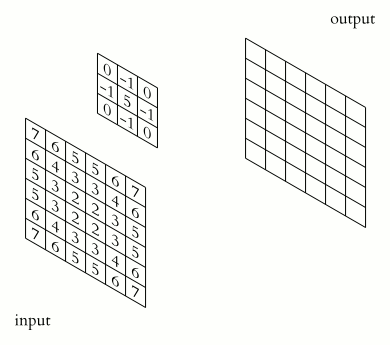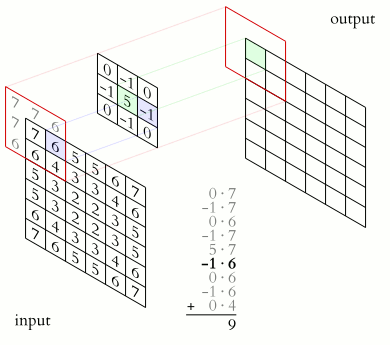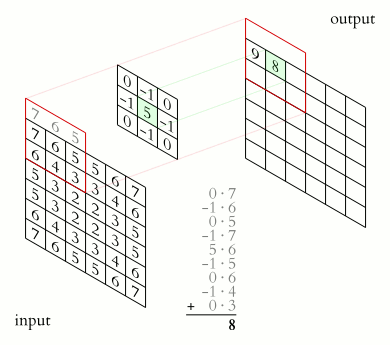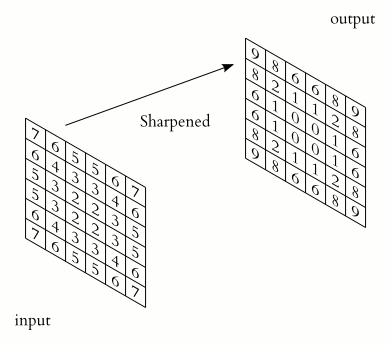
Источник: Wikipedia
Пулинг-слой разбивает картинку, полученную от сверточного слоя, на небольшие области (например, квадраты 2х2), и оставляет только пиксель с наибольшим значением. В результате количество пикселей уменьшается в несколько раз.
Ключевое преимущество CNN — значительное уменьшение числа настраиваемых весов. Если полносвязный слой между двумя цветными картинками размером 100х100 пикселей содержит 900 млн весов, то сверточный слой может содержать всего 9. При этом в пулинг-слое весов вообще нет.
То есть, сверточная сеть обучается несравнимо быстрее полносвязной.
Несколько лет назад сверточные сети совершили революцию в задачах распознавания изображений, а сейчас элементы их архитектуры применяются во всех сферах машинного обучения.
#4. Стемминг
Это процесс поиска основы слова. Алгоритмы стемминга используют для нормализации текста. К примеру, во время обработки речи компьютер обучают понимать различия между формой глаголов «играть» и «играют». Примеры алгоритмов, по которым работает стемминг — поиск по таблицам флексий, а также удаление суффиксов и окончаний слов.
#5. Лемматизация
Это алгоритм, который ищет лемму (словарную форму слова). Его используют для поиска связи между словами, например, «хороший» и «лучший».
Этот подход обработки текстовых данных сложнее, чем стемминг, но отличается большей точностью. Однако для работы алгоритму нужно правильно определять, к какой части речи относится каждое слово. Лемматизация работает намного медленнее, чем стемминг, и требует больших вычислительных ресурсов.


#6. Эмбеддинг
Научить компьютер понимать семантически близкие слова можно с помощью векторной (дистрибутивной) модели. Проанализировав большой массив текстов, компьютер установит схожесть контекста употребления слов с близким значением. Например, поймет, что слова «кафе» и «ресторан» встречаются в похожих предложениях.
Векторные модели — наборы чисел, которые отражают контекст употребления слова. Эти числа и есть word embedding. Нейросеть на входе получает сжатые векторные характеристики слов (embedding), а затем решает, какое из слов лучше подходит по контексту.
Instagram использует эту функцию для подбора похожих профилей. Приложение анализирует слова, которые используют клиенты, и формирует новые рекомендации.


