
Чому ML-продукти не масштабуються без чіткої MLOps-архітектури
Та що робити, щоб моделі працювали стабільно в продакшені?
Машинне навчання (ML) стало невіддільною частиною бізнес-процесів у більшості компаній. Його застосовують у рекомендаційних системах, автоматизації обслуговування клієнтів, прогнозування попиту, виявлення шахрайства, персоналізації контенту. Скрізь, де є дані, — є потенціал для ML.
Компанії інвестують у ML-моделі з двома основними бізнес-цілями: збільшення доходів (через персоналізацію, рекомендації, оптимізацію конверсії) та зниження операційних витрат (через автоматизацію процесів, прогнозування). На етапі MVP в контрольованих умовах проєкти зазвичай демонструють позитивні результати. Проблеми починають виникати вже при масштабуванні, здебільшого через три критичних розриви:
- технічний — модель не витримує реального навантаження та інтеграції;
- операційний — команда не справляється з управлінням декількома моделями одночасно;
- якісний — моделі деградують через data й concept drift без систематичного контролю.
Як результат — технічний борг зростає швидше, ніж команда встигає його обслуговувати. Чому так відбувається, що саме заважає масштабуванню ML-рішень і як практики MLOps допомагають подолати ці обмеження — розповідає Анна Пастушко, AWS Solutions Architect в Intellias та лекторка курсу robot_dreams.

Як виглядає ML-модель у продукті
ML-система — це не лише модель. Це повноцінний інженерний продукт, у якому модель є лише одним із компонентів. ML-система складається з чотирьох основних компонентів: (1) дані та їхні версії, (2) код і метадата моделі, (3) пайплайни тренування та деплою, (4) обслуговування моделі та моніторинг.
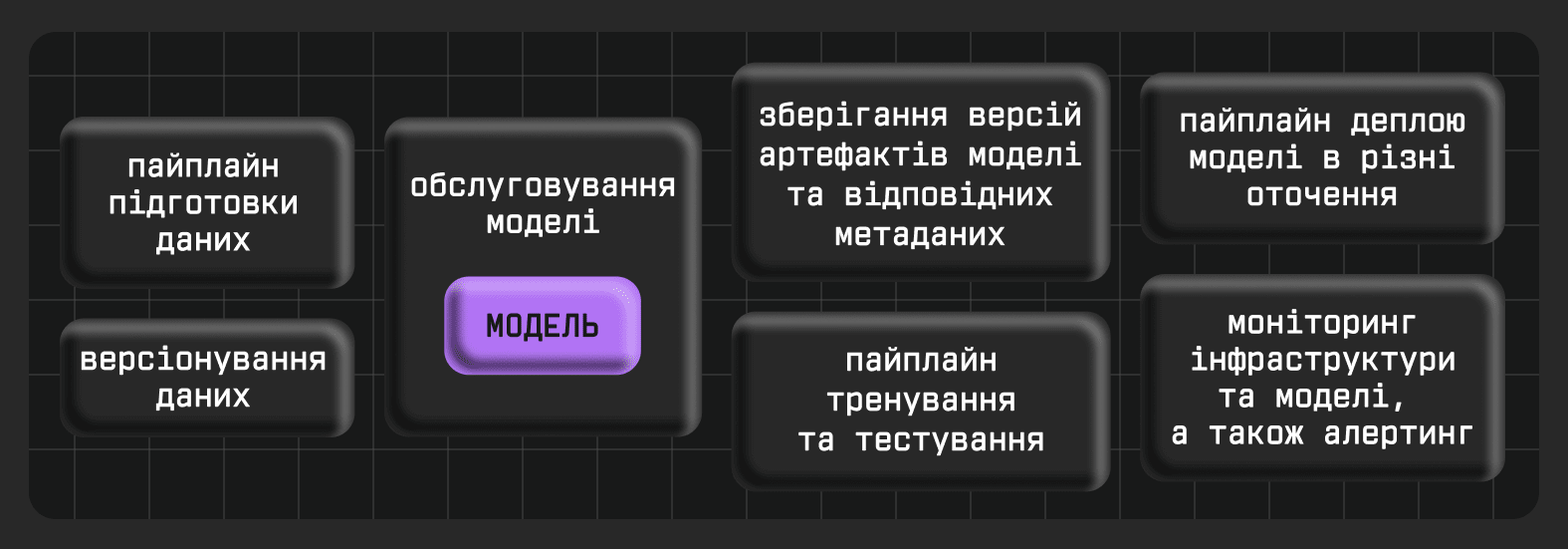
ML-модель у продакшені мусить:
- бути відтворюваною (тобто мати зв'язки з версією даних, кодом, гіперпараметрами, середовищем виконання);
- розгортатись через автоматизовані пайплайни;
- мати контроль якості й тестування перед деплоєм;
- бути інтегрованою з іншими компонентами продукту через стандартизовані API;
- мати моніторинг як бізнес-метрик, так і технічних показників роботи моделі після деплою.
Одна з ключових відмінностей ML-продукту від звичайного програмного забезпечення — тісна залежність від даних. Навіть без змін у коді поведінка моделі змінюється, якщо змінюється вхідний розподіл даних (data drift) або контекст використання (concept drift). Ці зміни можуть поступово знижувати точність прогнозів моделі без явних помилок у системі. Без постійного нагляду й супроводу ML-система деградує: результати стають менш точними та передбачуваними.
Чому ML-продукти не масштабуються без MLOps
На ранніх етапах ML-продукти будуються переважно вручну: дані готуються локально в одноразових скриптах, моделі тренуються в Jupyter-ноутбуках, середовища не стандартизовані, а деплой виконується як одноразова дія, часто без належного тестування. Такий підхід може працювати в умовах MVP або вузької дослідницької задачі. Але коли зростає кількість моделей, збільшується частота оновлень або додаються нові джерела даних — система втрачає керованість. Без автоматизованих процесів кожне оновлення перетворюється на ризик для стабільності всієї системи.
Ще однією критичною проблемою є неможливість відтворення результатів. У разі відсутності контролю версій даних, моделей, гіперпараметрів та конфігурацій — команда не може гарантувати, що модель, розгорнута в продакшн, дійсно є тією, яка пройшла тестування. Навіть сам автор моделі через кілька тижнів може не відтворити її, якщо дані або залежності змінились. Це призводить до фрагментації знань і втрати контролю над якістю моделей.
Не менш важливим є розрив між командами, які залучені до життєвого циклу ML-рішення. Дата-саєнтисти зосереджені на розробці моделей та експериментах, тоді як DevOps або ML-інженери відповідають за продакшен-середовище, масштабування та стабільність систем. Відсутність єдиних стандартів, зрозумілих контрактів між командами та інтегрованих пайплайнів призводить до того, що моделі «застрягають» у проміжному стані — створені, але не розгорнуті, або розгорнуті, але нестабільні.
Щойно модель потрапляє в продакшн, важливо розуміти не лише те, що вона працює, але й те, як саме вона поводиться з часом. Відсутність моніторингу — ще одна причина, чому ML-системи деградують. Якщо не відстежуються зміни у вхідних даних, якість прогнозів чи бізнес-метрики, команда може не помітити, що модель більше не відповідає реальності. В такій ситуації модель може працювати без технічних проблем, але її бізнес-цінність знижується.
І нарешті, нестабільність і ненадійність ML-систем — прямий наслідок усіх вищезгаданих проблем. Зміни у форматі даних, оновлення бібліотек, відсутність ізоляції середовищ або спонтанне зникнення залежностей можуть спричинити повне припинення роботи моделі. У великих системах це може викликати лавиноподібні збої. Якщо немає інструментів для швидкого виявлення та локалізації таких змін — час на усунення проблеми вимірюється не годинами, а днями.
Ці технічні недоліки не лише заважають масштабуванню — вони прямо конвертуються у фінансові втрати через простої системи, втрату довіри з боку користувачів через неточні прогнози та зниження швидкості розвитку продукту через ручні процеси. Саме тому без системного підходу до керування ML-продуктами — тобто без MLOps — побудова стабільної, надійної та масштабованої системи машинного навчання неможлива.
курсы по теме:
AI Solutions Architect
Виталий Козинский
Senior DevOps Engineer в SoftServe

Як MLOps розв’язує ці проблеми
MLOps (Machine Learning Operations) — це сукупність інженерних практик, інструментів автоматизації та культурних змін, що дозволяє ефективно впроваджувати, оновлювати й масштабувати моделі машинного навчання в продакшн-середовищі.
- Відтворюваність експериментів
Aвтоматичне зберігання результатів експериментів з усіма параметрами та версією даних. Це дає змогу в будь-який момент відтворити модель з точно такими ж характеристиками — незалежно від того, скільки часу минуло або хто з команди проводив експеримент. - Автоматизація доставки
Моделі інтегруються в продакшн за допомогою автоматизованих процесів тестування та деплою. Це усуває людські помилки, гарантує працездатність моделі, скорочує час доставки та дозволяє одночасне розгортання великої кількості моделей. - Моніторинг якості в реальному часі
Система автоматично відстежує ефективність моделі після її впровадження та нотифікує в разі проблем. Якщо показники роботи моделі знижуються (наприклад, через зміну вхідних даних або поведінки користувачів), команда розробників отримує повідомлення та приймає рішення про перетренування моделі або повернення до попередньої версії. Це дозволяє керувати роботою моделі в реальному часі та вчасно реагувати на проблеми. - Повторне використання компонентів
Замість того щоб кожного разу будувати нове рішення з нуля, MLOps передбачає створення модульної архітектури: стандартизовані етапи обробки даних, навчання, валідації та розгортання. Це дозволяє швидко починати розробку нових моделей та інтегрувати їх до наявних пайплайнів деплою.
З чого почати впровадження MLOps
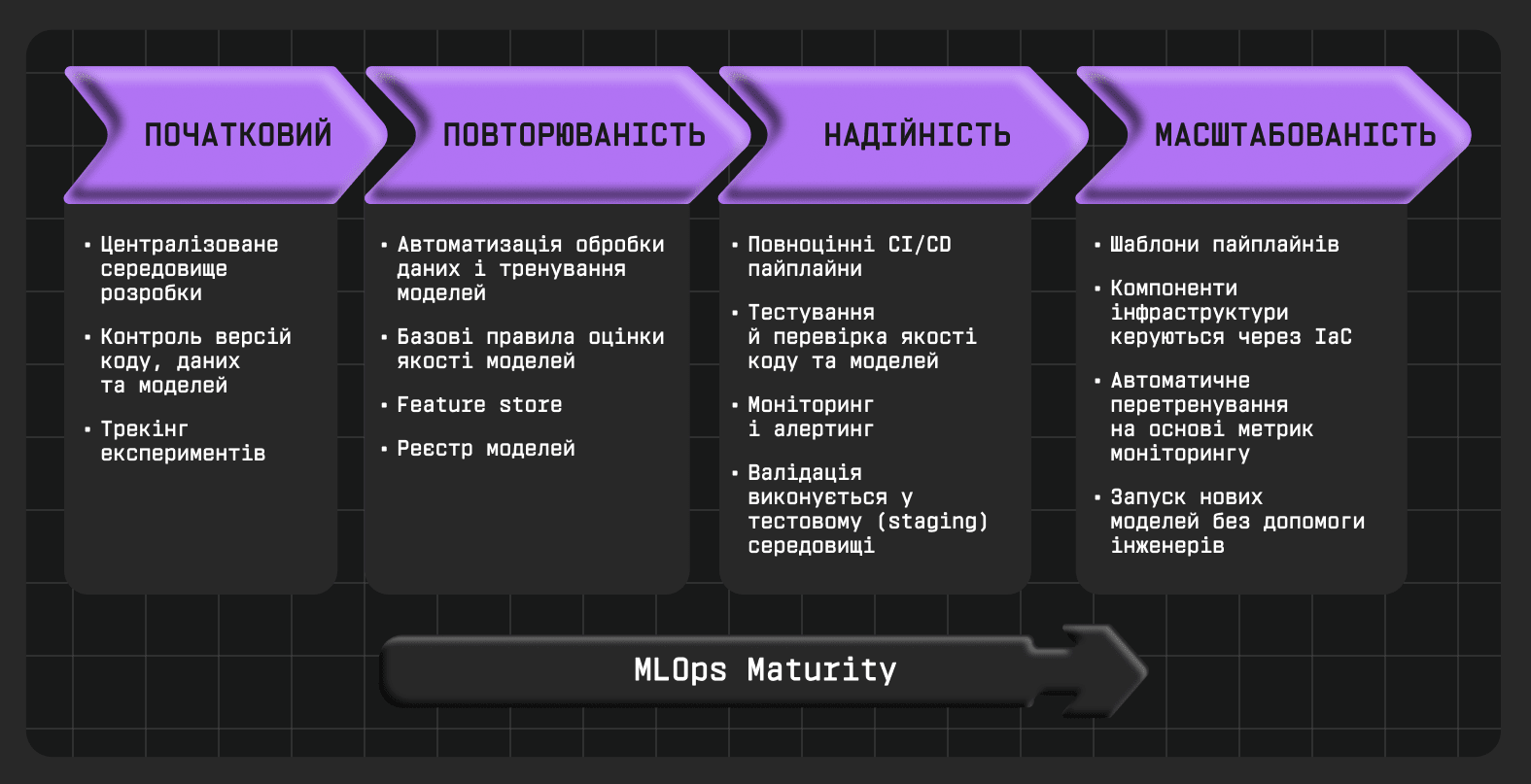
Впровадження MLOps — це не миттєвий перехід до складної платформи з повною автоматизацією, а поступовий розвиток практик, що дозволяє командам ефективніше працювати з моделями та масштабувати рішення в продакшн. Багато організацій проходять цей шлях поетапно, рухаючись від хаотичного експериментування до системного підходу, який охоплює весь життєвий цикл моделі. На практиці, цей процес можна умовно поділити чотири етапи.
1. Початковий рівень: контроль та відтворюваність
Команда закладає фундамент системного підходу: впроваджується контроль версій коду, даних та моделей. Використовуються інструменти для трекінгу експериментів, централізоване середовище розробки (наприклад, SageMaker Studio або IDE з підключенням до Git та MLflow). Мета — забезпечити прозорість, повторюваність і базову узгодженість між командами дата-саєнтистів та інженерів. Результати експериментів можна порівнювати, а найуспішніші — відтворювати.
2. Повторюваність: автоматизація тренування
Впроваджується автоматизація ключових кроків — обробки даних, тренування та базової валідації — за допомогою пайплайнів (Azure ML Pipelines, Vertex Pipelines, SageMaker Pipelines). Використовуються контрольовані джерела фіч (feature store), модельні артефакти додаються до централізованого реєстру моделей (Model Registry). Формуються базові правила для оцінки якості моделей, однак деплой ще часто виконується вручну. Цей рівень — перехід від «моделі як коду» до «моделі як артефакту», який готовий до масштабування.
3. Надійність: CI/CD, тестування, моніторинг
Розгортання моделей стає автоматизованим та контрольованим: впроваджуються повноцінні CI/CD пайплайни для ML (наприклад, з використанням GitHub Actions, CodeBuild, Azure DevOps, CodePipeline). Автоматично тестуються як код, так і самі моделі. Перед релізом проходить продакшн-валідація в тестовому (staging) середовищі. Моделі деплояться через керовані сервіси (Vertex AI Endpoint, SageMaker Endpoint, Azure Online Endpoint). Додається моніторинг у продакшені: трекаються метрики, логуються запити, автоматично виявляється data/concept drift, можливі алерти. Це забезпечує надійність, безпеку та швидке реагування на зміну умов.
4. Масштабованість: автономія та шаблонізація
Компанія переходить до стандартизованої MLOps-платформи з шаблонами для пайплайнів, деплою та моніторингу. Всі компоненти — від тренування до оновлення моделей — керуються через IaC (Terraform, CDK, Pulumi). За потреби додається автоматичне перенавчання на основі даних моніторингу. Команди можуть самостійно запускати розробки моделі без участі MLOps-інженерів, використовуючи шаблони. Це дозволяє масштабувати MLOps без втрати якості та контролю, трансформуючи його на рівень платформи.
Починаючи з невеликих кроків, компанія інвестує не лише в довгострокове масштабування, але й в щоденну ефективність, прозорість та якість рішень. Найголовніше — не прагнути досконалості одразу, а рухатись поступово, формуючи стійкий процес замість тимчасових рішень.
Висновок
Моделі машинного навчання не живуть у вакуумі. Щоб вони працювали стабільно, ефективно й масштабовано, їм потрібно MLOps-середовище. Без MLOps ML-продукти залишаються експериментами. Вони не витримують змін, не масштабуються, не відповідають вимогам реального світу.
Якщо ви будуєте ML-рішення не заради досліду, а для бізнесу, — почніть з фундаменту. MLOps — це той фундамент, який дозволить моделі стати частиною ефективного та прибуткового продукту.


