
Новая эра в NLP: как модель BERT все изменила
Объясняет Data Scientist в YouScan.
Два года назад лучшие результаты в обработке естественного языка (NLP) показывали многослойные рекуррентные или сверточные модели. В качестве эмбеддингов использовались векторы слов из наборов алгоритмов word2vec, fasttext или glove. Для каждой задачи тестировали разный набор подходов, стараясь подобрать самый подходящий.
Но с тех пор в NLP-индустрии произошел огромный прорыв, благодаря которому сильно возросло качество на всех типах задач. Кроме того, технологии стали более доступными. Теперь даже с минимальной подготовкой можно получить передовые результаты.

Виталий Радченко, Data Scientist в YouScan рассказывает, кто совершил революцию в NLP, что такое трансформеры и зачем понадобился бенчмарк SuperGlue.
Типы NLP-задач
Все задачи в индустрии направлены на то, чтобы упростить людям работу. Например, NLP используют для автоматизации ответов службы поддержки или определения тональности упоминания бренда в соцсетях.
Основные направления NLP можно разделить на:
- задачи по классификации (например, определение тематики текста);
- задачи по машинному переводу;
- ответно-вопросные системы (чат-боты);
- summarization (для краткого изложения статей и автоматической генерации превью);
- поиск похожих текстов (например, для определения инфоповодов, проверки вопросов на Quora и подобных сервисах);
- составление тестов на основе предоставленного материала и другие узкоспециализированные задачи.
Сложнее всего машинам решать задачи поддержания диалога, понимания контекста, отвечать на открытые вопросы (как на экзаменах).
Ключевые метрики NLP:
- Процент правильно проставленных меток для текста. Метки в этом случае — любые теги (в зависимости от задачи). Например, тональность, тематика, человек, географические объекты.
- Правильное определение границ ответа в большом тексте. Алгоритму задают вопрос, границы ответа на который нужно найти внутри текста. Задача называется question answering. Ее практическое применение — поиск ответа на юридические вопросы в тексте закона, на вопросы о компании в FAQ на сайте, поиск ответа в «Википедии».
- Схожесть перевода или сгенерированного текста с заданным, которая оценивается с помощью метрики BLUE. Чем ближе машинный перевод к человеческому, тем лучше.
Что такое трансформеры
Трансформер – это архитектура, основанная на механизме внимания (attention), благодаря чему модель обращает внимание на разные части текста и таким образом лучше выучивает закономерности, необходимые для решения задачи.
В 2018 году разработчик Джейкоб Девлин и его коллеги из Google описали использование архитектуры трансформеров для задач NLP. Они натренировали большую языковую модель BERT и доработали ее для решения разных задач, в итоге получив огромный прирост по сравнению с предыдущими SOTA-решениями. Это стало толчком для использования архитектуры трансформеров в NLP.
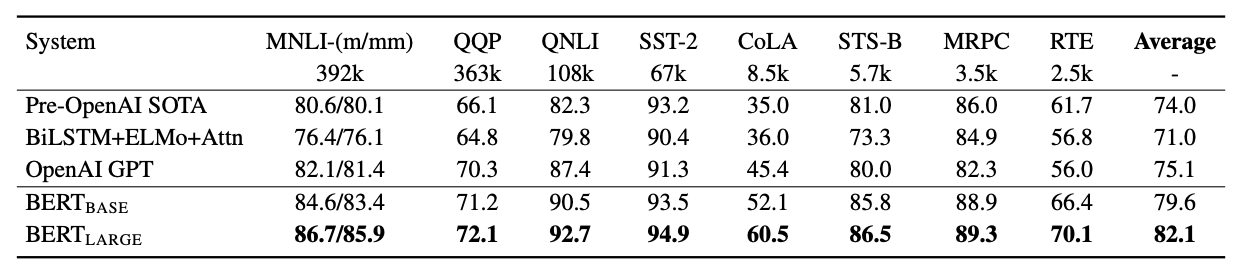
Результаты BERT на бенчмарке GLUE / BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Множество компаний и больших исследовательских центров начали развивать технологию. Появились решения от Facebook (Roberta), Baidu (Ernie), Google (T5) и других. Они отличаются подходами к обучению языковых моделей, но в основе всех из них — трансформеры. Каждая исследовательская группа старается привнести что-то новое и усовершенствовать предыдущее лучшее решение.
Сейчас все SOTA-разработки основаны на архитектуре трансформеров, потому что BERT спровоцировал интерес и заложил фундамент для улучшений. Более старые подходы, в частности, RNN и CNN, значительно уступают современным моделям.
За полтора года результаты на GLUE-бенчмарке моделей превзошли результаты человека. 87,1% — средний показатель для людей, а результаты некоторых моделей превышают 90,5%. До BERT’a же лучший показатель составлял около 75% (Это среднее значение разных метрик — Ред.).
Но модели все еще несовершенны, и в реальной жизни справляются с задачами хуже людей. Поэтому разработчики создали новый бенчмарк SuperGlue, в который вошли более сложные задачи.
SuperGlue – основной opensource-бенчмарк для сравнения архитектур моделей. Он включает задачи на понимание текста и употребление слов в правильном контексте. Ранее для этих целей использовали бенчмарк GLUE.


Кроме того, благодаря библиотеке Transformers от компании Hugging Face порог входа в NLP снизился. В Transformers есть удобное API для использования современных opensource-архитектур, а также хранилище весов модели. В нем можно найти веса всех известных архитектур для разных языков и примеры их использования. Например, там есть английская GPT-2, украинская Roberta или GPT-3 для русского языка.
Дополнительная ценность этой библиотеки в том, что вы можете посмотреть реализацию каждой из архитектур. Это поможет разобраться в улучшениях, которые сделали авторы.
В предстоящем курсе мы, в том числе, разберемся во всех SOTA-архитектурах и научимся использовать библиотеку transformers для разных NLP-задач.
Обложка: Eleks Labs


