
Распознавание речи
Эволюция вместо революции.
Десять лет назад технологию speech recognition начали использовать для массовых коммерческих решений. Но распознавать речь так же хорошо, как люди, алгоритмы пока не могут. Им еще нужно научиться справляться с семантическими ошибками, различать контекст, определять акценты и работать быстрее.
Вместе с Александром Коноваловым, основателем сервиса видеозвонков DROTR, вспоминаем этапы развития технологии и говорим о потенциале систем автоматического распознавания речи.
Ключевые проекты прошлого
Человеческая речь — это серия звуков. А звук — это совмещение волн, у которых две характеристики: амплитуда и частота. Первые попытки создать механизм, способный различать звуки, исследователи предпринимали в 1920-х. Никаких нейросетей и машинного обучения, только огромные аналоговые машины и идейные ученые.

Робот «Телевокс» со своим создателем.
Источник: Acme Telepictures/NEA
В 1927 году в США инженер Вестингаузовской электрической компании Рой Уэнсли создал робота «Телевокс». Он распознавал речь благодаря собственным реле и камертонам. Все звуки разделялись на три тона, и за каждый отвечал свой камертон. В зависимости от того, какой камертон срабатывал, включалось определенное реле.
Через 25 лет двое ученых из исследовательского центра Bell Labs создали машину Audrey. При условии правильной адаптации к динамику и пауз между словами, Audrey выдавала точность 97-99% и была способна распознать строки цифр от 1 до 9.
Машина трансформировала сказанные ей слова в электрические импульсы и сопоставляла их с имеющимися в ее памяти паттернами. После этого на панели управления подсвечивалась правильная цифра.
Уникальная для своего времени Audrey впоследствии никак не использовалась: машина занимала почти всю комнату и потребляла уйму электроэнергии. Кроме того, она могла хорошо распознавать цифры, произносимые только одним человеком, поэтому коммерциализировать такое решение было почти невозможно.
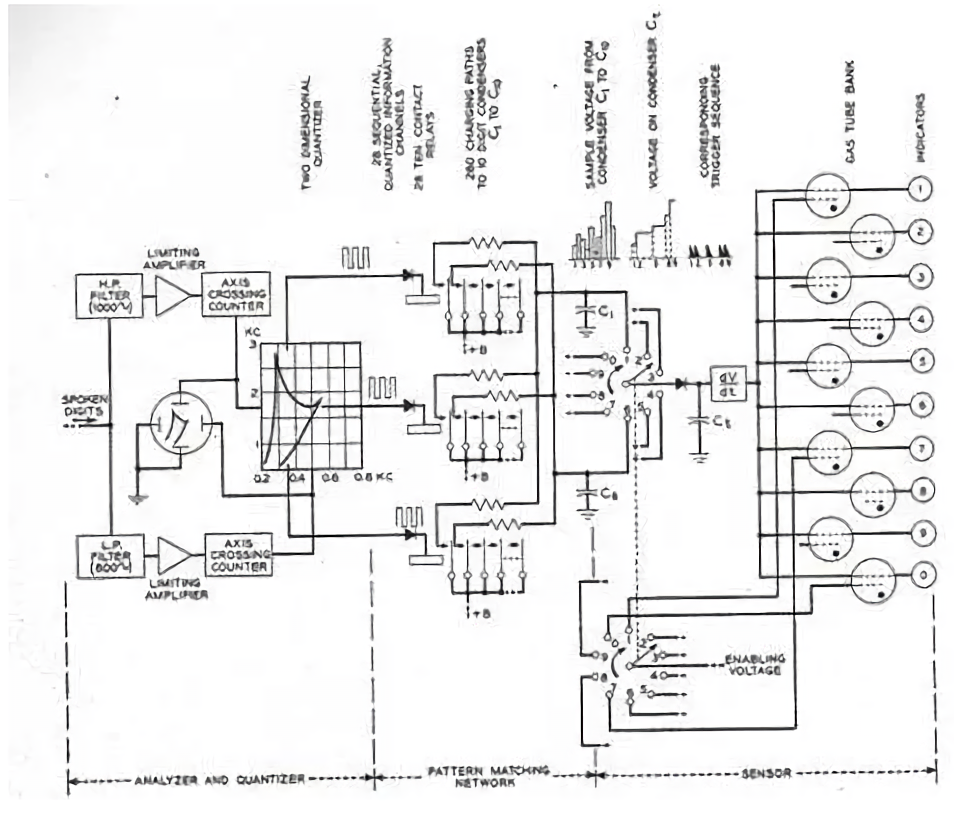
Схема работы Audrey / Bell Labs
В 60-х годах прошлого столетия ученые создали алгоритм, на базе которого выстроили систему, знающую 200 слов.
В это время над созданием систем распознавания речи работали в СССР, Америке, Англии и Японии. Но у всех этих систем был общий недостаток — если произносимые слова были сказаны с любым изменением в скорости, тембре или четкости, то база шаблонных паттернов становилась бесполезной. Нужно было разбивать слова на фреймы и фонемы, чтобы иметь возможность менять диктора.

Неоднородность звучания фонем в разных словах
Источник: «Распознавание речи: современные подходы» / Machinelearning
В 80-х годах ХХ века IBM создали Tangora — машину, которая после 20-минутного тренинга понимала любого спикера. В процессе этого тренинга Tangora накапливала в базe образцы фонем и виды их реализации. Ее «лексикон» составлял 20 тысяч слов. Еще через десять лет IBM разработали MedSpeak/Radiology — программу для медиков, которая стенографирует результаты рентгенов. Ее до сих пор точечно используют в медицине.
Наше время: нейронные сети, САРР и ML
Большинство современных систем распознавания (идентификация изображений и объектов на них, машинный перевод, определение границ, распознавание речи) построены на базе рекуррентных нейросетей. RNN могут понимать контекст предложения благодаря внутренней памяти и обратным связям. Это позволяет предсказывать слова в предложениях, учитывая предыдущие слова.
Выглядит это так: звуковая волна дробится на фреймы, после чего из них вытягивают самые важные характеристики. Затем нейросеть дает прогноз и угадывает вероятность того, какая фонема прозвучала на фрейме. Декодирование выдает гипотезы. Например, выражение «Тарас Шевченко — украинский поэт» намного вероятнее, чем «Тарас Шевченко — украинский поем».
В среднем RNN может обработать пять слов.
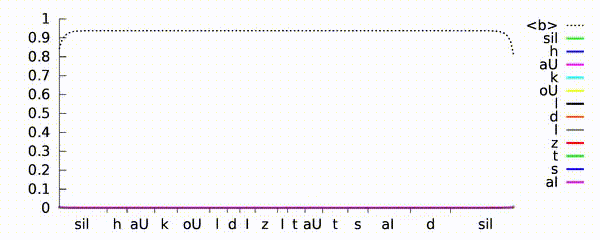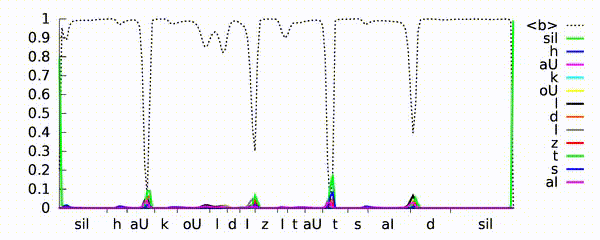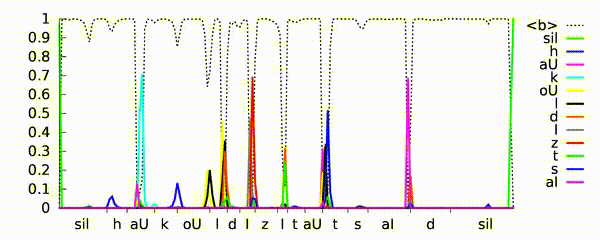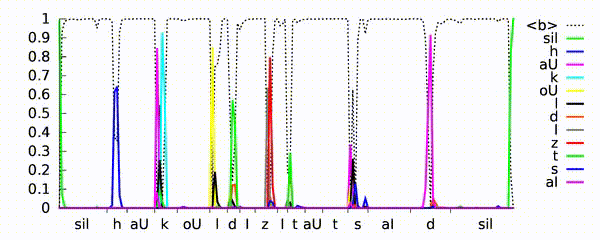
Рекуррентная нейронная сеть учится предсказывать фонемы для высказывания «как холодно на улице». Нейросетевая темпоральная классификация модели (CTC) выводит пики, поскольку идентифицирует различные фонемы (показанные разными цветами) во входном речевом сигнале. Ось X показывает синхронизацию акустического входа для фонем, а ось Y — вероятности, предсказанные нейросетью. Пунктирная линия демонстрирует, где модель предпочитает не выводить фонему.
Источник: Hasim Sak’s YouTube channel
Решить проблему ограниченного контекста способна сеть с долговременной и кратковременной памятью (LSTM) и управляемый рекуррентный блок (GRU).
При использовании обычных RNN каждый шаг обучения вносит в память новую информацию, но сеть быстро теряет ее с течением времени.
LSTM-модули запоминают значения на короткие и длинные временные отрезки, не размывая информацию во времени. По мере тренировки сети, она не исчезает. У каждого нейрона есть ячейка памяти и три вентиля: входящий, выходящий и забывающий. Они защищают информацию. Входящий вентиль устанавливает, сколько данных из предыдущего слоя сохраняется в ячейке. Выходящий вентиль определяет, сколько получат следующие слои. Функция третьего вентиля — вычислить то, что уже можно забыть.
У GRU нет выходного вентиля, поэтому, по сравнению с LSTM, у него меньше параметров.
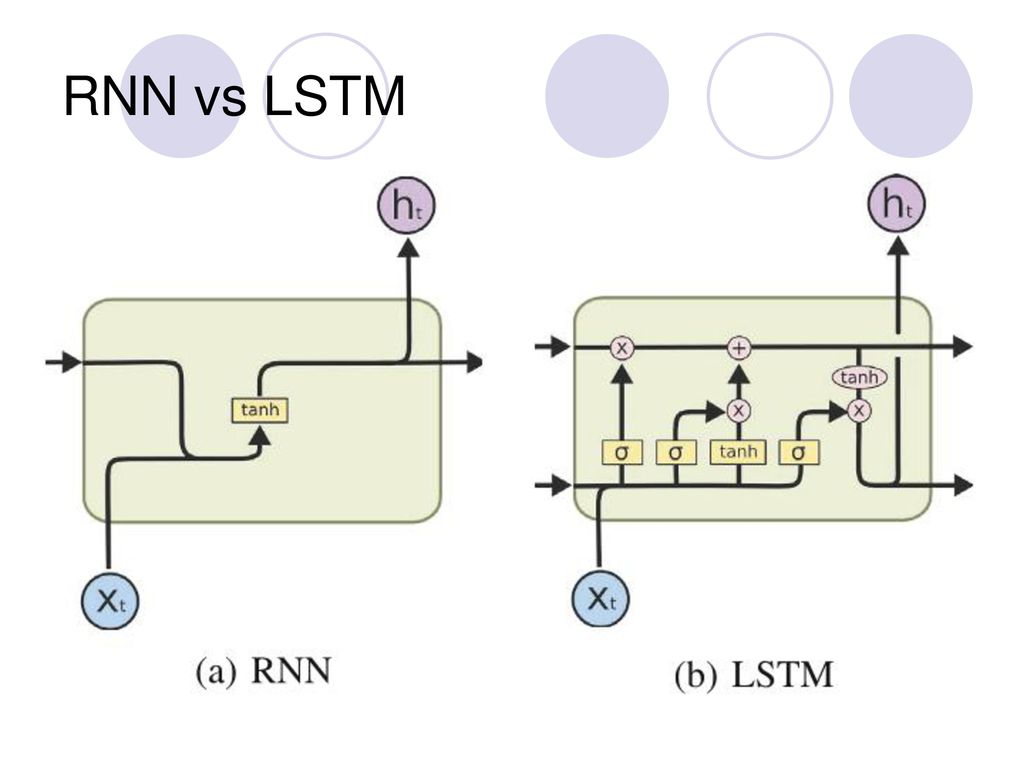
Источник: Slideplayer
Окей, Google. Как услышать каждого
За последнее десятилетие методы ML позволили алгоритмам обучаться на больших объемах речевых данных и усовершенствовать распознавание акцентов. Во многом это заслуга Google, создавших приложение Google Voice Search для iPhone. Миллиарды поисковых запросов позволили провести крупнейший анализ данных В 2010 году «персонализированное распознавание» появилось в голосовом поиске на телефонах Android, а потом — и в браузере Chrome. В Apple создали Siri, а в Microsoft — Cortana.
В 2012 году голосовой поиск Google стал использовать глубокие нейросети. Корпорация инвестирует $6 млрд в построение собственного Центра речевых технологий. В 2016 она открыла доступ к программным интерфейсам Cloud Speech API. Это дало возможность интегрировать голосовое управление от Google в любые программы.
До разработок Google монополистом на рынке была компания Nuance, чья технология применялась в пользовательских интерфейсах (например, телевизоров и автомобилей).
Именно к этой компании Apple обратились в первые дни существования Siri. Технология Nuance основана на методах статистического анализа; для распознавания слова сервис обращается к фонемам и контексту. Сегодня компания сосредоточена на разработке чат-ботов для корпоративных клиентов. С помощью ML в Nuance автоматизируют создание диалоговых моделей.
Решение от Nuance Dragon Professional остается одним из лучших на рынке. Оно способно обрабатывать 160 слов в минуту с точностью 99% (сразу после завершения обучения). Сначала программа адаптируется к голосу и словам, которые обычно используете спикер.

Александр: «Несколько лет назад мы создали программу для видеозвонков, голосовых сообщений и групповых чатов с синхронным переводом.Технология позволяла передавать и оригинал речи, и перевод, который следовал за оригиналом через секунду. Сначала мы использовали Bing от Microsoft. Для разработки iOS-версии в 2014-м году мы вообще не смогли использовать Google Voice, потому что он умел распознавать только поток и только на Android, и были вынуждены "прикручивать" Nuance. Это сделало решение довольно дорогим».
курсы по теме:
Математика и статистика для Data Science
Кеес Наталия
Data Scientist в Airbus

Когда наступит завтра
Следующий скачок стоит ожидать с появлением систем, понимающих слитную человеческую речь. Скорее всего, их авторами станут инженеры и математики из корпорации Google.
Александр: «Беда Google в том, что они делают сразу все языки, а каждый из них имеет свою специфику, структура речи, акценты, диалекты. Да и сами люди говорят по-разному. Поэтому понадобится еще лет 10, чтобы технология распознавания речи speech-to-text работала совершенно.
Есть и другой вопрос — а используют ли нейросети на самом деле те, кто об этом заявляет? Тот же Apple говорит, что в основе Siri — нейросети, но сама компания размещала множество вакансий на должность редактора диалогов для Siri».
Автоматическое распознавание речи по-прежнему работает хуже, чем человеческое ухо. Но теперь проблема технологии — не данные, а модели.
Нужно решить задачи, связанные с морфологией, акцентами, высотой звука, темпом, громкостью, сливающимися словами, артикуляцией, лингвистической информацией.
Этим заняты Facebook, Amazon, Microsoft, Google и Apple.


