< собственный data pipeline >
Big Data: обработка и аналитика
Освойте Spark, Databricks, Kafka, dbt и Airflow, чтобы превращать большие данные в действенные решения.
Денис Кулемза
Senior Data Engineer в Intellias
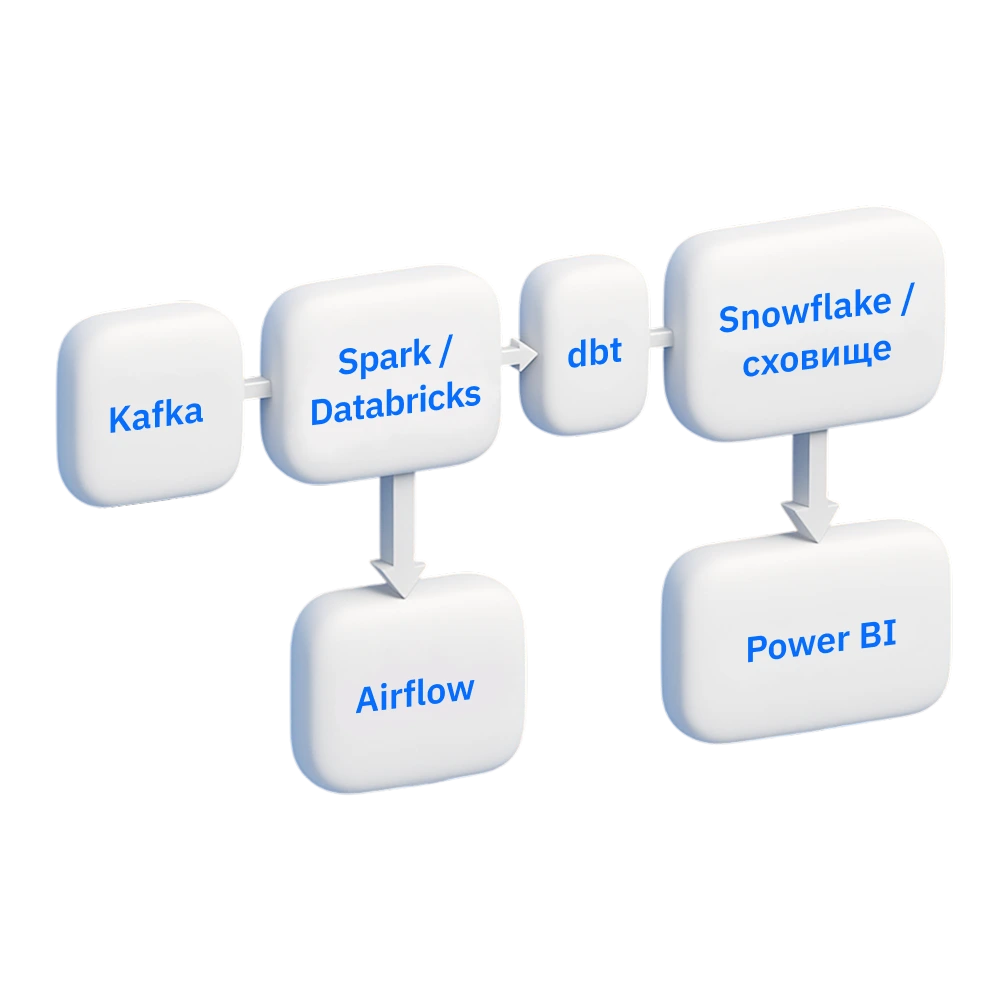
которые хотят строить более эффективные пайплайны со Spark, Kafka и dbt, ищут более стабильные флоу и возможности лучшей оркестрации через Airflow
которые хотят понять, как выглядят данные за кулисами: от потоков до моделирования, а также хотят получить больше контроля над данными, с которыми работают
которые хотят перейти в data-направление, прокачать работу с логами, событиями, схемами и лучше понимать архитектуру современных data-пайплайнов

- научитесь настраивать среду в Snowflake, сможете реализовывать ELT/ETL-сценарии
- будете автоматизировать процессы с помощью Kafka и Airflow
- поймете, как интегрировать инструменты Big Data в бизнес-процессы
- будете применять лучшие практики работы с Big Data на основе реальных кейсов
Освоите Apache Spark, Databricks, Kafka, Snowflake, dbt, Airflow, AWS Athena, Power BI, чтобы проектировать стабильные системы обработки данных — от сбора до визуализации.
Построите полный цикл обработки данных: сбор, трансформация, проверка качества, сохранение и визуализация.
Узнаете, как проверять данные на точность, настраивать тесты в dbt и автоматизировать контроль качества в пайплайнах.

- поймете разницу между хранилищами данных, data lakes и lakehouse-архитектурой
- узнаете о преимуществах и недостатках каждого подхода в зависимости от бизнес-сценария
- изучите паттерны обработки данных — пакетную и потоковую — и их влияние на архитектуру пайплайна
- поймете распределенную модель выполнения в Spark
- научитесь выполнять базовые трансформации и действия с DataFrame
- узнаете, когда лучше использовать DataFrame API, а когда — Spark SQL
- узнаете, как выявлять и устранять проблемы с производительностью в Spark
- научитесь использовать партицирование, кэширование и broadcast joins для оптимизации
- поймете, как читать Spark UI для улучшения выполнения задач и решения проблем со skew
- узнаете, из чего состоит AWS EMR и как работают его компоненты (Hadoop, Spark, Hive и т. д.)
- научитесь настраивать EMR-кластеры для удобной и масштабируемой работы со Spark
- научитесь настраивать рабочую среду Databricks в AWS
- поймете жизненный цикл кластеров и как оптимизировать расходы
- узнаете, как подключать Databricks к облачным хранилищам, в частности ADLS
- научитесь писать и выполнять SQL-запросы в Databricks
- узнаете, как использовать Databricks SQL для BI-аналитики
- поймете, как оптимизировать запросы и работать с производительностью
- узнаете, как Unity Catalog централизует управление данными в Databricks
- научитесь настраивать каталоги, схемы и доступы для безопасности данных
- поймете возможности аудита и отслеживания происхождения данных (data lineage)
- узнаете, как оценивать и оптимизировать расходы на Databricks
- научитесь улучшать производительность ноутбуков и придерживаться best practices
- сможете быстро находить и устранять проблемы с конфигурацией или производительностью
- поймете разницу между Star- и Snowflake-схемами
- научитесь выбирать соответствующий подход для моделирования
- будете уметь разрабатывать базовые аналитические схемы «звезда» и «снежинка»
- узнаете основные принципы работы Snowflake как облачного DWH
- научитесь настраивать среду, создавать таблицы и работать с Warehouse
- сможете загружать данные в Snowflake и выполнять SQL-запросы
- поймете ключевые преимущества Snowflake по сравнению с другими хранилищами
- узнаете, как автоматизировать процессы в Snowflake с помощью Tasks и Streams
- научитесь реализовывать сценарии ELT/ETL непосредственно в Snowflake
- ознакомитесь со способами шеринга данных и настройкой доступов
- поймете, как использовать Time Travel и Zero-Copy Cloning в проектах
- научитесь организовывать dbt-проект по рекомендованной структуре
- разберетесь с синтаксисом Jinja и созданием модульных SQL-шаблонов
- сможете создавать аналитические модели в формате схем звезды или снежинки с помощью dbt
- научитесь создавать тесты и макросы для проверки качества и целостности данных
- сможете автоматизировать документацию и оповещения для прозрачности процессов
- разберетесь с расширенным синтаксисом Jinja для сокращения повторяющегося кода
- научитесь описывать ключевые концепции Kafka — topics, partitions, offsets
- поймете, как Kafka обеспечивает обработку данных в реальном времени
- сможете интегрировать Kafka с другими системами для событийно-ориентированных архитектур
- узнаете, как реализовать инкрементную обработку данных в Spark Structured Streaming
- научитесь работать с неупорядоченными событиями с помощью watermarking и windowing
- сможете развернуть стриминговый конвейер от Kafka до Delta Lake
- поймете преимущества Kafka и Spark для real-time и stateful-обработки данных
- научитесь создавать и настраивать потоки в AWS через Amazon Kinesis Data Analytics
- сможете реализовать трансформации потоков: окна, состояния и checkpointing
- узнаете о моделях NoSQL: key-value, документную и колонковую
- научитесь проектировать ключи партиций для масштабируемости
- поймете суть CAP-теоремы и компромиссы между согласованностью и доступностью
- научитесь осуществлять SQL-запросы к данным в дата-озерах
- узнаете, как Athena масштабируется и как оценить ее стоимость
- поймете, как партицирование и внешние схемы ускоряют аналитику
- научитесь создавать DAG в Airflow для автоматизации ETL
- поймете, как управлять развертыванием через Git и CI/CD
- узнаете, как работать с расписаниями, бэкфилами и улучшать надежность
- научитесь управлять задачами Databricks через Airflow
- сможете запускать dbt-команды и настраивать переменные среды
- узнаете, как централизовать расписания, логирование и обработку ошибок
- научитесь подключаться к источникам, трансформировать и визуализировать данные в Power BI
- узнаете, в чем различия между DirectQuery, Import и Live Connection
- узнаете, как подключить Power BI к Databricks Lakehouse для аналитики в реальном времени
- научитесь настраивать расписания обновления и работать с потоковыми наборами данных
- освоите защиту доступа к данным через AWS IAM
- разберете все неточности и получите ответы на вопросы, возникшие во время прохождения курса Big Data
- реализуете и представите data pipeline на базе Lambda-архитектуры с использованием Databricks, dbt, Kafka, Snowflake и Power BI
Регистрация
Регистрируйтесь на курс, чтобы Big Data начали работать на вас:
от решения ежедневных задач до
профессионального роста на рынке.
СТАРТ ОБУЧЕНИЯ— В АПРЕЛЕ 2026 ГОДА