
Как научить AI понимать рекламу
Работа с Google Vision: кейс Perion.
AI в рекламе уже не удивить. «Умные» алгоритмы есть и у всех крупных платформ (Google, Facebook, Amazon, Snap), и у внешних вендоров (MakeMeReach, Kenshoo, Albert).
Машины решают, кому мы покажем рекламу и по какой цене. Но, Как отмечает исследование аналитиков Nielsen, ключевой фактор успеха рекламы — креатив. И он пока остается в руках человека. Рассчитать, насколько эффективной будет рекламная кампания почти невозможно, а многие решения принимаются интуитивно.
Но алгоритмы уже учатся предсказывать, какой креатив сработает лучше и помогают его выбрать или даже создать. Над подобной AI-системой работает израильская технологическая компания Perion.

Дмитрий Плешаков, кофаундер Captain Growth и Head of Engineering в Perion Network Kyiv, рассказывает, что такое creative intelligence и как использовать computer vision для анализа рекламы.
Алгоритмы vs креативность
Есть два подхода к AI в рекламных креативах:
#1. Автоматическое создание рекламы. Представьте, что генеративная нейронная сеть читает ваш бриф и сама ставит BMW на урбанистический фон, помещает рядом с авто только что сгенерированную модель в модном пальто, делает цветокоррекцию и вставляет продающий текст. Его нейронка тоже пишет сама.
Технологически мы близки к этому: такое решение можно собрать из Cycle GAN, GPT-3 и deepfake, которые уже есть на рынке. Многие рекламные продукты пробуют автоматизировать этот процесс частично, например, создают вариации для A/B тестов. Но соображения brand safety пока побеждают, а креатив от людей все еще выглядит круче.
#2. Условный pilot assistant, который оставляет за маркетологом креативную работу, но помогает делать ее эффективнее. В этом случае алгоритмы не создают картинки, а подсказывают идеи для новых креативов, предлагают, как улучшить имеющиеся, помогают учиться на прошедших рекламных кампаниях. Мы работаем над концептом такого AI и называем его creative intelligence.
Цель creative intelligence — сказать маркетологу, у каких креативов шансы на успех выше, и почему. Какую модель ставить на баннер? К какой ценности апеллировать? Показывать ли цену? С какого ракурса демонстрировать продукт? В какой цветовой гамме делать креатив? Данные об этом есть и у бренда, и у агентства, и у рекламной платформы, но их не используют, потому что они спрятаны глубоко в изображениях и видео.
Для создания такой intelligence, нужно, чтобы машина понимала контент. Рекламные объявления плохо подходят для того, чтобы просто передать их статистическим моделям. Сначала из каждого объявления нужно извлечь содержимое. Здесь на помощь и приходит computer vision.
Мы решили начать с определения элементов рекламы, которые могут влиять на performance: объектов, людей и животных, текстов, цветов и графических элементов. Зная эти признаки, можно моделировать их влияние на успех рекламы и давать пользователю инсайты и рекомендации, построенные на данных.

Как начать проект на основе computer vision
Чтобы сделать проект в области computer vision, еще лет 5 назад нужно было искать или готовить датасет, писать и тренировать под него свою модель. Порог входа в такие проекты был довольно высоким. Сегодня ситуация намного лучше. Есть 3 варианта:
#1. Учить модель с нуля под свои специфические задачи.
#2. Использовать opensource-модель, предобученную на ImageNet, дообучать ее под свои задачи по необходимости.
#3. Использовать облачный продукт, который предлагает computervision-решения as a service. Вендоров несколько: Google Vision, Amazon Rekognition, Microsoft Cognitive Services, Clarifai.
Облачные решения выигрывают по ряду причин:
- дают более высокую точность разметки по сравнению с бесплатными моделями и определяют десятки тысяч разных классов
- не требуют затрат на подготовку — подключение занимает минуты, решение работает «из коробки». Стоимость таких сервисов — около $1,5 за обработку 1000 изображений. Кост посильный даже для небольшой компании (если вы не оперируете десятками миллионов картинок)
- сервисы настолько просты, что ими можно пользоваться, не имея в команде data scientist'а. Обычное API — отправляешь фото, получаешь найденные для него признаки.
- вендоры сервисов для computer vision предлагают всю облачную инфраструктуру у них можно хостить файлы изображений, тренировать и деплоить свои кастомные модели.
Для себя мы выбрали облачный сервис Google Vision. Он опередил AWS Rekognition по точности лейблинга, хотя в целом решения похожи и дают сравнимые результаты. Есть несколько хороших обзоров, которые помогут выбрать вендора с учетом специфики проекта.
Что умеет Google Vision AI
#1. Label detection — основная фича. В ответ на каждую картинку Google возвращает теги, которые наилучшим образом описывают то, что на ней изображено. С каждым тегом приходит оценка уверенности модели. Всего Google умеет определять 20 000 классов и они разные по сути. Это и объекты (кресло, рубашка или собака), и категории (дизайн, инфраструктура, реклама), и очень детальные классы (марки автомобилей, модели телефонов, названия брендов). Иногда лейблом может быть цвет, часть тела, профессия.
Теги, как правило, точны, но дают неструктурированное описание изображения, характеризуя его с разных сторон, и часто дублируя друг друга.

Labels: Transport, Coca-Cola, Snow, Vehicle, Mode of transport, Cola, Christmas, Tree, Winter, Drink, Truck, Christmas eve.
#2. Object detection. Находит и локализует на изображении объекты. Они могут быть вложены друг в друга. Например, на фото с автомобилем Vision выделит и само авто, и колеса, и шины.

С каждым объектом приходит степень уверенности.
#3. Landmark detection. Возвращает геолокацию места, где сделано фото. Работает для туристических мест со всего мира.
#4. Facial detection. Локализует лицо человека, координаты ключевых точек (глаза, губы, брови, нос) и определяет 4 эмоции: радость, печаль, злость, удивление. Для каждой сервис возвращает оценку от very unlikely до very likely. Палитра эмоций не очень широкая, и в большинстве случаев сервис не определяет ни одной из них. В закрытой бете сейчас есть celebrity detection, который должен определять на фото знаменитостей.

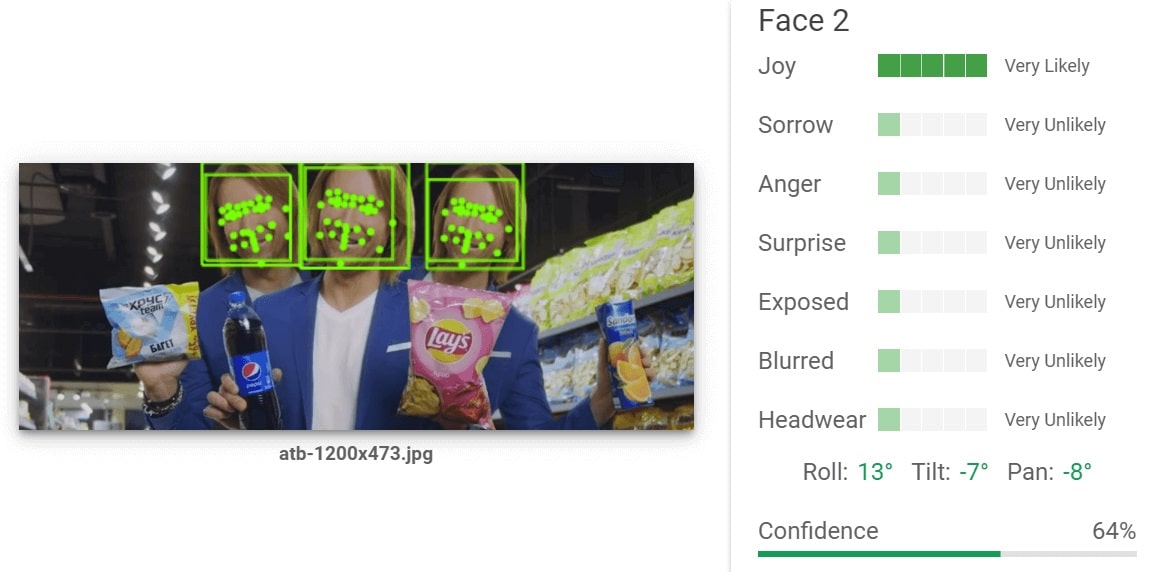
Google нашел здесь всех 3 Олегов Винников. Самый радостный из них — в центре. Вероятность — 64%.
#5. Text detection. У Google есть технология OCR, которая отлично распознает тексты на изображении в разных вариациях и на разных языках, включая украинский. Считываются и текстовые блоки, размещенные поверх фото, и сфотографированные вывески и ценники, и текст на экранах телефонов в кадре, и даже текст с водяных знаков.

Каждый текстовый блок локализуется на изображении, возвращаются его координаты.
#6. Web detection. Выполняет Google-поиск по вашей картинке и анализирует контент найденных сайтов. В результате можно получить некоторые контекстуальные лейблы, которых не было видно на самом фото. Кроме этого, Vision API предлагает best guess labels — текст из 2-3 слов, максимально точно описывающий картинку.

Реклама продвигает Adidas, но по изображению это может быть неочевидно. Web Search помогает в таких случаях, добавляя полезный контекст. Сравните сами:
Label detection: Sports, Sports equipment, Player
Web search: Monatik, Adidas, Sport shoes, Shoe, Musician, Adidas Superstar, Sneakers
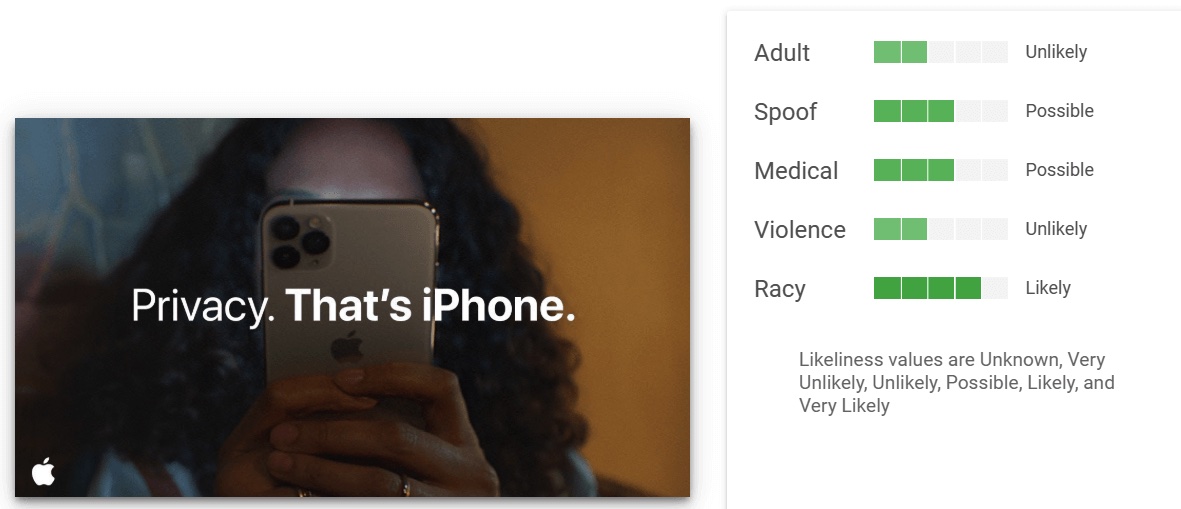
#7. Safe search detection. Проверяет, не относится ли изображение к одной из 5 нежелательных категорий: взрослый контент, мошенничество, медицина, жестокость и расизм. Для каждой категории приходит оценка по шкале от very unlikely до very likely. С большинством категорий все в порядке, но алгоритм часто видит расизм там, где на него нет даже намека.
От технологии — к продукту
Мы ожидали, что Vision API будет распознавать на изображениях все существенные объекты, и нам останется только пользоваться данными. На практике результаты нельзя просто взять и отправить в продакшн. В нашем случае нужна серьезная постобработка.
Основной недостаток — неструктурированность и разнородность лейблов. Например, на одном фото изображен художник, а на другом — фотограф. Vision API вернет 2 разных лейбла, а мы хотели бы понимать, что и там, и там — человек.
Сами лейблы часто повторяют друга, а иногда — конфликтуют между собой. Это особенно критично, когда доходит до характеристик продукта. Одни и те же автомобили довольно часто классифицировались у нас и как hatchback, и как SUV. Volkswagen Golf система перепутала с Volkswagen Polo. Наручные браслеты посчитала часами.
Чтобы справиться с этими проблемами, мы пробуем разные подходы, в том числе:
- NLP-кластеризацию лейблов в группы
- фильтрацию бессмысленных классов
- применение иерархической структуры для лейблов на основе классификатора IAB,
- введение своих высокоуровневых лейблов, которые строятся на основе данных от Vision API.

Последний способ — пока что самый эффективный. Теперь на основе информации из Vision API мы определяем, есть ли на изображении люди или животные, фото это или картинка, где сделан снимок (в помещении или на улице). Сырые ответы от Google сохраняем как дополнительную информацию.
Полезна и фильтрация. Самыми интересными для нас оказались категориальные лейблы средней глубины. Например,«гаджет», вместо абстрактного «технологии», и конкретного, но, вероятно, неточного «iPad Pro».
Ключевой фактор, влияющий на успех рекламы, — человек в кадре. Мы используем информацию о ракурсе, одежде, направлении взгляда, эмоции. В отношении самих людей Vision API немногословен и политкорректен — он не сообщает ни пол, ни возраст, ни расу человека на изображении.
Вообще решение от Google хорошо в определении универсальных вещей, но оно конечно не знает рекламной специфики. Например, не может определить какие графические элементы (рамки, плашки) используются на картинке. Распознавание таких объектов мы решаем с помощью собственных моделей.


