
Як застосувати multi-agent systems для вашого бізнесу: 5 напрямків у деталях
Вони вміють набагато більше, ніж ви думаєте
В сучасних компаніях реальні процеси стали занадто складними для одного алгоритму. Замість «суперагента», який намагається робити все, компанії будують команди спеціалізованих агентів, де кожен відповідає за свою задачу — і разом вони досягають результату.
З появою LLM концепція MAS отримала друге життя. Класичні агенти з FIPA ACL еволюціонували в LLM-based системи, які спілкуються природною мовою. Але фундаментальні принципи — автономність, реактивність, проактивність, соціальна взаємодія — залишилися незмінними. Змінилася лише реалізація.
В цій статті розберемо 5 кейсів та покажемо, як ваші знання з курсу про Multi-agent Systems втілюються в реальних сферах.
1. Автоматизація фінансової аналітики та прогнозування
До появи АІ-агентів фінансові аналітики мусили вантажити дані з кількох систем, звіряти суперечливі показники, будувати модель і писати звіти, витрачаючи на це пів дня. Команда AI-агентів здатна зробити це за 15 хвилин, причому краще — помічаючи кореляції, які людина пропустила б.
Так працюють сучасні системи в JPMorgan Chase, Goldman Sachs та хедж-фондах. Це не один бот, а команда:
- Агент-збирач витягує дані з API
- Агент-валідатор перевіряє якість
- Агент-аналітик будує моделі
- Агент-детектор шукає аномалії
- Координатор збирає все у звіт
Кожен спеціалізується на своїй задачі, разом створюючи конвеєр, який працює 24/7.
Blackboard architecture: дошка для колективного мислення
Центральна ідея — blackboard pattern. Це спільний простір пам'яті, куди агенти записують результати й читають дані від інших. Як whiteboard в офісі, на якому команда разом розв'язує проблему.
У фінансовій системі blackboard має шари:
- Raw Data: котирування, новини, соцмережі
- Processed Data: очищені, нормалізовані показники
- Analysis: технічні індикатори, метрики
- Insights: патерни, аномалії, прогнози
- Decisions: фінальні рекомендації
Працює це так:
Агент-збирач дістає дані, що акції Tesla впали на 3%. Валідатор перевіряє, позначає verified. Новинний агент додає контекст про затримку постачань. Технічний аналіз бачить пробиття рівня підтримки, додає potential downtrend. Інтегратор збирає все докупи: Tesla падає через новину X, технічні показники це підтверджують. Тому рекомендація — продавати.
Чому не передавати дані напряму? Blackboard пропонує opportunistic problem solving — агенти реагують на те, що з'являється, не чекаючи черги.


2. Управління ланцюгами постачання (Supply Chain)
За будь-якою доставкою стоїть складна хореографія: знайти товар на одному зі 175 складів, обрати маршрут, скоординувати з іншими замовленнями, передбачити затримки, та ще й в реальному часі для мільйонів інших замовлень. Одна централізована система не впорається. Тому Amazon, Walmart та інші великі маркетплейси переходять на multi-agent підхід.
Supply chain нагадує місто, де кожен склад, вантажівка, постачальник — автономний агент. Вони не чекають команд «зверху», а ухвалюють рішення та домовляються. Це розподілена координація, яка масштабується краще за централізоване планування.
Contract Net Protocol: як склади торгуються за замовлення
Класичний CNP ідеально працює в логістиці. А працює він, власне, так:
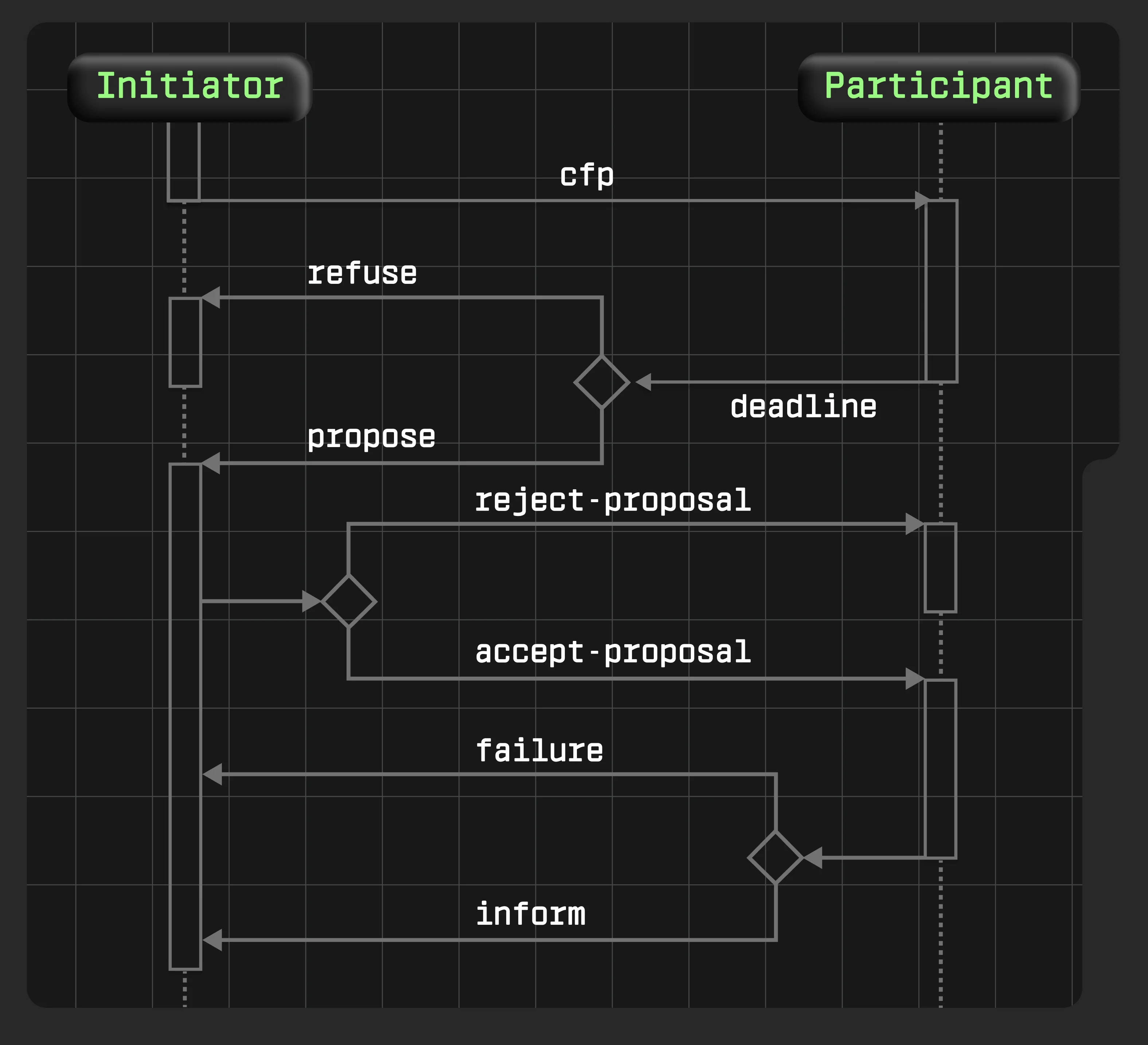
Джерело: Research Gate
Уявімо сценарій: юзер замовляє ноутбук у Києві.
1. Task Announcement: координатор оголошує тендер з параметрами (товар, локація, дедлайн).
2. Bidding: агенти-склади подають заявки:
- Львів: 36 годин, $180 (є запас, але далеко)
- Київ-Бориспіль: 8 годин, $85 (близько, але останній товар)
- Варшава: 48 годин, $250 (багато товару, але митниця)
3. Award: координатор оптимізує за кількома критеріями (швидкість 40%, вартість 30%, надійність 20%, запаси 10%). Київ виграє, але Варшаві йде signal: Prepare backup.
4. Execution: київський склад стає manager'ом для підзадач — запускає тендер для курʼєрів.
Децентралізація vs централізація
Виходить, що децентралізований підхід найкращий? В реальності найкращий підхід — це гібрид.
При централізованому плануванні одна система знає все, розраховує глобальний оптимум і працює для малих компаній з передбачуваним попитом. Втім, такі гіганти, як Amazon, обробляють понад мільйон замовлень на день — перерахунок після кожного нового займає занадто багато часу.
В децентралізований мультиагентній системі кожен агент знає тільки локальну інформацію та ухвалює рішення автономно. Тому таку систему легше масштабувати й адаптувати до змін.

3. Персоналізований маркетинг і customer journey
Рекомендації Netflix точно зчитують ваш смак, Amazon неначе знає, що вам потрібно, а Spotify — який плейлист підійде для пробіжки. В усіх цих сервісах задіяний не один алгоритм, а команда агентів, які спостерігають, планують і координуються, щоб створити персональний досвід.
Сучасні маркетингові платформи (HubSpot, Salesforce Marketing Cloud, Adobe Experience) використовують MAS, де кожен агент відповідає за частину customer journey: один аналізує поведінку на сайті, другий — обирає контент для email, третій — оптимізує час відправки, четвертий — координує кросканальну комунікацію.
BDI-архітектура: агенти з цілями та переконаннями
BDI (Beliefs-Desires-Intentions) — класична архітектура з теорії агентів, яка ідеально підходить для маркетингу.
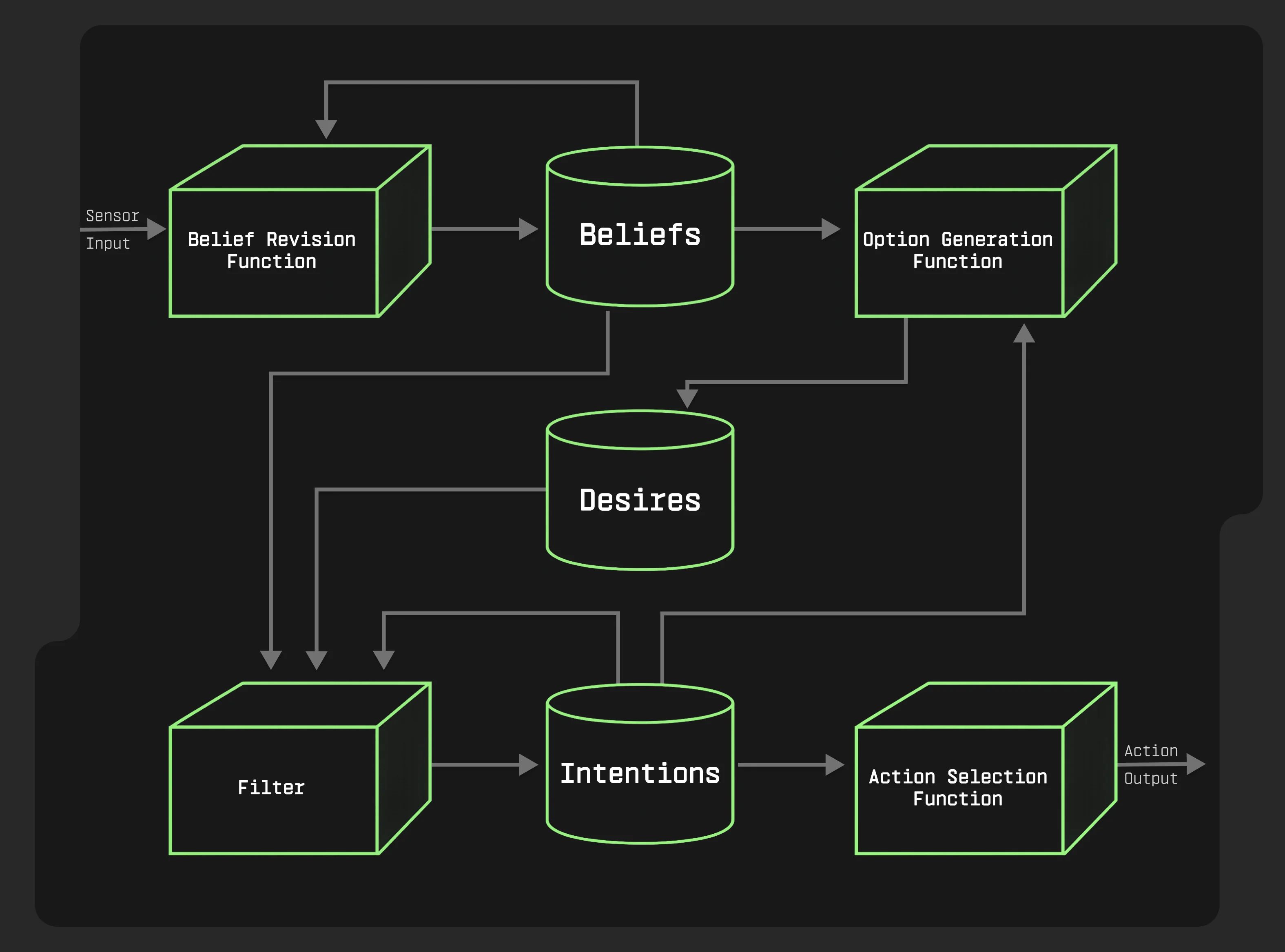
Вона має три компоненти:
1. Beliefs (переконання) — що агент знає про клієнта:
{
"user_id": "12345",
"browsing_history": ["laptops", "gaming mice", "mechanical keyboards"],
"purchase_history": ["budget laptop 6 months ago"],
"engagement": "high (clicked 5 emails last month)",
"likely_gamer": 0.87,
"price_sensitivity": "medium"}
2. Desires (бажання) — можливі цілі агента:
- Збільшити engagement
- Конвертувати в покупку
- Утримати клієнта
- Upsell до premium-продуктів
3. Intentions (наміри) — обрані цілі та план дій:
Goal: Convert to purchase (gaming laptop)
Plan:
1. Send personalized email with gaming laptop recommendations
2. If clicked → show retargeting ads with 10% discount
3. If added to cart but not purchased → send abandonment email in 24h
4. If purchased → trigger upsell sequence (gaming accessories)
Агент постійно оновлює beliefs (нові дані про поведінку), переоцінює desires (чи актуальна мета?) і коригує intentions (план працює чи треба змінити?).
До прикладу, якщо користувач раптово почав дивитися бюджетні опції замість gaming-категорії, агент оновлює belief "price_sensitivity": "high" і змінює intention — замість premium laptop пропонує mid-range з акцією.
Планування дій: від цілей до конкретних кроків
Маркетинговий агент не просто реагує діями на дії користувача, а планує послідовність дій для досягнення мети. Для цього існує Hierarchical Task Network (HTN) планування.
Мета розбивається на підзадачі:
Goal: Increase customer lifetime value
├─ Sub-goal 1: Complete first purchase
│ ├─ Action: Send welcome email with 15% discount
│ ├─ Action: Show testimonials on product page
│ └─ Action: Retarget on social media
├─ Sub-goal 2: Encourage repeat purchase
│ ├─ Action: Send "You might also like" email after 2 weeks
│ └─ Action: Offer loyalty points
└─ Sub-goal 3: Prevent churn
├─ Monitor engagement (if drops → re-engagement campaign)
└─ Send personalized offers on anniversary
Якщо один action не спрацював (email не відкрили), агент переплановує, пробує інший канал звʼязку або змінює повідомлення.
4. Розробка софту через MAS
Стартапи на кшталт Devin, Sweep чи AutoGPT вже створюють MAS для автоматизації software engineering. У цій системі може бути багато агентів, кожен з яких відповідає за конкретну функцію. Працюють паралельно, координуються через Git, як звичайна dev-команда.
Агенти-спеціалісти
- Code Writer Agent отримує завдання implement user authentication, генерує код, комітить у feature branch.
Code Review Agent аналізує pull request:
Issues found:
- Security: Password stored in plaintext (CRITICAL)
- Performance: N+1 query in user lookup (MEDIUM)
- Style: Missing type hints (LOW)
Recommendation: Request changes
- Testing Agent генерує тести на основі коду:
def test_authentication():
# Generated test cases:
- Valid credentials → success
- Invalid password → error
- SQL injection attempt → blocked
Coverage: 87%
- Documentation Agent читає код, пише docstrings і README:
## Authentication Module
Handles user login/logout with JWT tokens.
Security: bcrypt hashing, rate limiting.
Usage: See examples/auth_demo.py
- Refactoring Agent виявляє code smells, пропонує покращення:
Detected: Duplicate logic in login/register functions
Suggestion: Extract to validate_credentials() helper
Estimated improvement: -45 lines, +15% readability
Координація через Git
Спільний репозиторій на Git виступає таким собі координаційним механізмом, фактично замінюючи blackboard для агентів. Замість спеціального протоколу комунікації вони використовують звичні механізми:
- Branches. Кожен агент працює в окремій гілці, як developer. Code writer — у feature/auth, tester — у test/auth, refactorer — у refactor/optimize.
- Pull requests. Агенти створюють PR, інші агенти роблять review:
PR #142: Implement authentication
Author: code-writer-agent
Reviewers:
- code-review-agent: ❌ Requested changes (security issues)
- test-agent: ✅ Approved (tests pass)
- doc-agent: 💬 Comment (needs usage examples)
- Issues / Tasks. Координатор (або user) створює issues, агенти claim'ять їх через labels:
Issue #45: Add password reset
Labels: claimed-by:code-writer-agent, status:in-progress
Linked PR: #150
- CI/CD Integration. Коли агент комітить, запускаються автоматичні перевірки. Якщо тести падають, testing agent аналізує логи, комітить фікс або повертає writer'у.
Що відбувається, коли агенти не згодні
Якщо, скажімо, два агенти змінили одну функцію, Git показує конфлікт, але хто має його розв’язувати — незрозуміло. Для цього є negotiation protocol:
- Detect. Система помічає конфлікт у PR
- Analyze. Обидва агенти пояснюють свої зміни
- Resolve. Створюють компромісний варіант
Якщо протокол не спрацював, decision agent може задіяти механізм голосування і збирати голоси агентів:
- Security agent: Prioritize writer's version (security > readability)
- Performance agent: Refactorer's version is 20% faster
- Coordinator: ухвалює виважене рішення обʼєднати writer's security й refactorer's library approach
Якщо ж агенти не можуть вирішити (dead-lock), вони ескалюють проблему до людини через GitHub issue з тегом needs-human-review.

5. Fraud detection і кібербезпека
Одна централізована система не встигає виявляти шахрайство або кібератаку в реальному часі. Тому Visa, Mastercard, а також tech-гіганти типу Google та Microsoft використовують MAS.
Distributed Sensing: спостерігачі всюди
В кібербезпеці MAS має зонування відповідальності. Так, замість одного монолітного детектора є десятки спеціалізованих агентів. Скажімо, для виявлення шахрайства у банкінгу є:
- Transaction Monitor Agent, який аналізує патерни витрат кожного користувача
- Geolocation Agent, який відстежує локаційні аномалії (покупка в Києві, через 10 хвилин — у Лондоні)
- Merchant Profile Agent, який моніторить ризикові категорії merchant'ів (gambling, crypto)
- Velocity Agent, який виявляє аномальну частоту транзакцій
- Device Fingerprint Agent, який перевіряє, чи транзакція з нового пристрою
Кожен агент знає тільки свій шматок даних і спеціалізується на своєму типі аномалій.
Information Fusion: складання пазла
За всіма агентами ж стоїть fusion agent, який збирає локальні спостереження в єдине рішення.
Anomaly Scores:
- Transaction: 0.78 (weight: 0.3)
- Geolocation: 0.95 (weight: 0.4)
- Device: 0.62 (weight: 0.2)
- Merchant: 0.15 (weight: 0.1)
Weighted Sum = 0.78*0.3 + 0.95*0.4 + 0.62*0.2 + 0.15*0.1 = 0.729
Threshold = 0.7 → FRAUD DETECTED
Фінальна оцінка базується на історичній точності кожного агента. Альтернативно є Bayesian Fusion. Це складніший підхід комбінування через теорему Баєса:
P(Fraud | All Evidence) = P(Evidence | Fraud) * P(Fraud) / P(Evidence)
Кожен агент надає likelihood ratio, fusion agent обчислює posterior probability. Якщо > 0.9 — транзакція блокується. Також fusion agent використовує аргументаційний фреймворк — оцінює не тільки те, чи є аномалія, але й те, чому агент так вважає. Сильніші аргументи отримують більшу вагу.
Adversarial MAS: захисники vs атакувальники
Компанії тренують системи через змагальні сценарії в симуляціях. Їх ділять на команди:
Команда А (агенти, що атакують):
- SQL Injection Agent, який намагається втілити різні варіанти injection
- DDoS Agent, який генерує flood traffic
- Phishing Agent, який надсилає зловмисні лінки
- Privilege Escalation Agent, який шукає вразливості в системі доступів
Команда Б (агенти, що захищаються):
- WAF Agent, який фільтрує підозрілі запити
- Rate Limiter Agent, який блокує аномальний трафік
- Anomaly Detector Agent, який виявляє незвичні патерни
- Patch Agent, який автоматично закриває вже відомі вразливості
Симуляція запускається в ізольованому середовищі. Агенти, що атакують, пробують різні стратегії, а захисні — адаптуються.
Таким чином система вчиться на атаках, які ще не трапилися в реальності, та еволюціонують разом. Успішні стратегії атаки «розмножуються» (використовуються частіше), неуспішні — вимирають. Агенти в захисті також адаптуються, адже якщо атака X спрацювала, вони оновлюють правила. Це еволюційна гонка озброєнь, як у природі.




