
Data-анализ и статистический анализ
Есть ли разница.
Обе эти отрасли используют данные, чтобы получить выводы о группах потребителей, населении или целевом рынке. Но конечная цель data-аналитика — понять, как результаты исследований способны помочь бизнесу. У статистика же такой необходимости нет.
Рассказываем, есть ли другие различия между направлениями.
Как все начиналось
В начале XVIII века англичанин Джон Арбетнот изучил соотношения полов при рождении. Он сравнил записи о рождении каждого человека в Лондоне в период с 1629 по 1710 год (все это время рождалось больше мужчин, чем женщин). Эти работы считаются первыми исследованиями о статистической значимости. Тогда ученые исследовали в основном демографические данные — к другим у них доступа почти не было.
Data-аналитика появилась почти 300 лет спустя. В 1980-х и 90-х годах ученые Международной ассоциации статистических вычислений и KDNuggets начали использовать компьютеры для обработки данных. Причина — информации стало гораздо больше, появились новые методы ее сбора и анализа. Это стало толчком для появления data-аналитики. Компаниям нужно было прогнозировать рынки и поведение потребителей. Поэтому data-аналитику стали использовать с коммерческой целью.


Для бизнеса или нет
Data-анализ чаще всего проводится с бизнес-целью и помогает разработать стратегии развития компании. Благодаря анализу данных компании могут узнать, как минимизировать траты, вывести новый продукт на рынок и повышает ли рекламная кампания продажи.
Среди методов data-аналитики:
#1. Регрессия. Она определяет влияния одной или нескольких независимых переменных на зависимую переменную.
#2. Сетевой анализ. Он находит связь между единицами данных, формируя пары взаимосвязанных наблюдений.
#3. Моделирование данных. Цель — дать возможность компании управлять данными как ресурсом.
Data-аналитика извлекает информацию из разных источников, включая инфопотоки в реальном времени. Например, неструктурированные данные (электронные письма, медицинские данные, веб-страницы). Алгоритмов, способных качественно обрабатывать неструктурированные данные, пока нет. Поэтому аналитики делают это сами. Подготовка неструктурированных данных к анализу — препроцессинг.
Одно из самых перспективных направлений data analysis — нейросетевая аналитика. С ее помощью можно не только найти закономерность, но и спрогнозировать, например, изменение цен на бирже или метеопрогноз. Этот процесс имеет 4 ступеней:
#1. Выбор архитектуры сети (многослойные персептроны, радиальные базисные функции, самоорганизующиеся карты признаков и т.д.)
#2. Настройка параметров обучения
#3. Само обучение
#4. Проверка обучения и анализ полученных результатов
Эти ступени цикличны. Если результаты не отвечают целям анализа, процесс возобновляется.
Статистический анализ же помогает предсказать характеристики или поведение многих на основе немногих. Главный метод — анализ ограниченного объема данных (выборки). Для ее исследования используют строгие величины описательных статистик. Например:
#1. Среднее значение — параметр или число, заключенное между наименьшим и наибольшим из совокупности значений.
#2. Корреляция — взаимосвязь двух или нескольких случайных параметров.
#3. Медиана — это показатель, который делит распределение пополам.
#4. Регрессионный анализ устанавливает зависимость одной переменной от другой (других).
#5. Дисперсионный анализ исследует важность различий в средних значениях.
Ключевые компетенции аналитика данных
Data-аналитик должен знать R и Python, SQL-подобные языки, владеть автоматизированным поиском data mining, понимать бизнес-модели и уметь визуализировать данные.
Аналитик данных работает с HIVE и PIG, фреймворками Hadoop и Apache Spark, разбирается в машинном обучении, статистическом анализе и математике. Сам процесс работы аналитика зачастую состоит из таких этапов:
- сбор информации
- препроцессинг данных: выборка, очистка, сортировка
- поиск закономерности
- визуализация
- выдвижение гипотез о том, как повысить бизнес-показатели
- аргументация гипотез
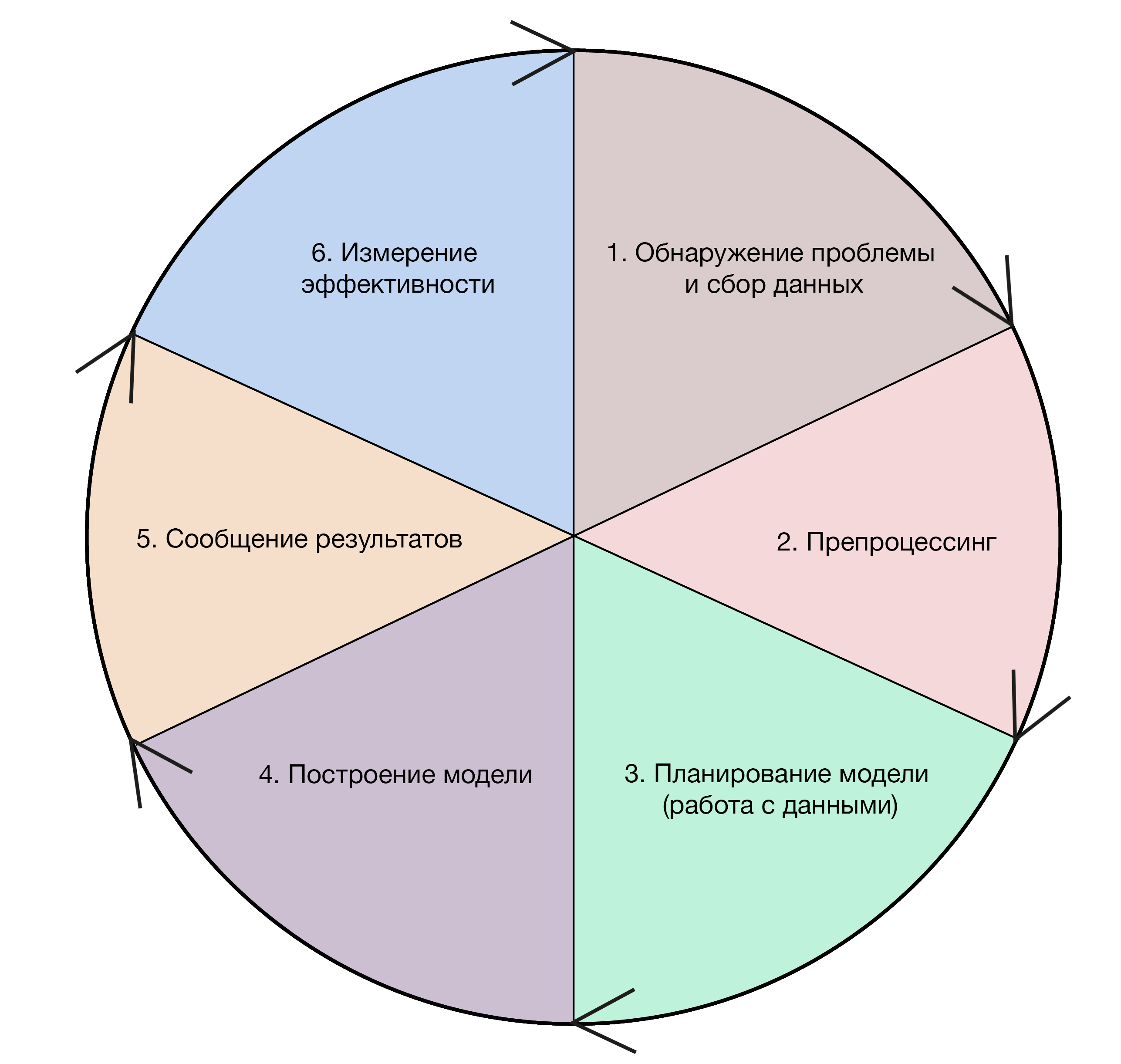 Этапы работы data-аналитика / Data Science Central
Этапы работы data-аналитика / Data Science Central
Наука, не подвластная времени
Статистический анализ обычно использует математические методы (проверка гипотез и вероятности), а также теоремы. Основные — теорема Чебышева, теорема Бернулли и теорема Ляпунова.
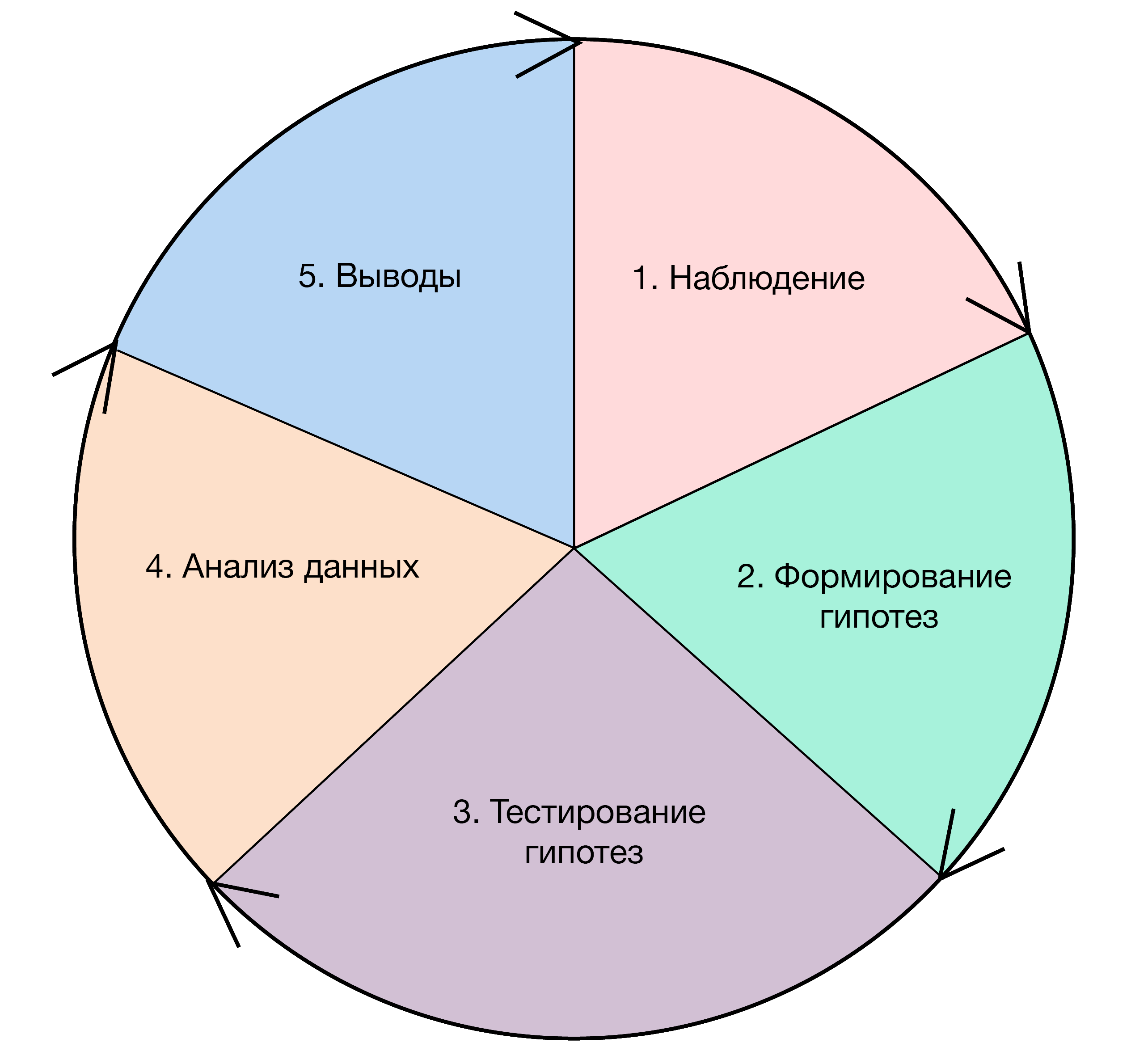
Этапы работы статистика / Data Science Central
Статистический анализ более последователен, чем data-анализ, и направлен на понимание одного конкретного аспекта выборки за раз. Например, среднего, стандартного отклонения или доверительного интервала.
Есть несколько десятков основных методов статистического анализа. Среди них — корреляционный, регрессионный и кластерный анализы.
Регрессионный анализ определяет связи между переменными, корреляционный — дает понимание о схожести их поведения.
Для кластерного анализа нужно не только собрать данные, но и решить, на сколько кластеров их нужно разделить и как в них определять feature selection. Например, все заводы Украины можно разделить на 15 кластеров по территориальному признаку. Тогда feature selection может стать близость их друг к другу.
Нельзя точно сказать, где кончается статистика и начинается data-аналитика. Потому что в основе аналитики данных — статистические методы. Но для data-анализа не так важна математическая строгость. Он чаще ошибается, но при этом находит более интересные инсайты в информации.


