
7 способов улучшить данные
Как выжать максимум из датасетов.
Из-за низкого качества данных компании теряют миллиарды долларов. Работая с плохой «датой», можно сделать ошибочные выводы и предложить неверное решение.
Единого стандарта качества нет. Но можно оценивать наборы данных, учитывая:
- точность (данные верно описывают объект или событие);
- полноту (данные описывают все параметры объекта);
- актуальность и своевременность (данные «свежие» и периодически обновляются);
- согласованность (записи сохранены в одинаковых форматах).
Рассказываем, как повысить качество данных.

#1. Определите критерии для данных вашего проекта
Специфические критерии качества нужны, чтобы понять, как должны выглядеть подходящие данные. Например, можно рассчитать:
- коэффициент пустых полей — отношение количества незаполненных полей к общему числу записей;
- показатель отказов при рассылке по электронной почте (можно рассчитать, разделив неудачные рассылки на общее число адресов в списке);
- затраты на хранение данных — большое количество дубликатов и устаревших резервных копий в конечном итоге может стоить компании кругленькую сумму.
#2. Создайте подробные метаданные
Метаданные — это информация о самих данных. Например, метаданные текстового документа: имя автора, размер и дата создания файла, ключевые слова.
Метаданные помогают обеспечить контекст, стандартизируют форматы и правила работы с данными. Полные метаданные помогают оценить качество данных и упрощают интеграцию записей из разных источников.

#3. Профилируйте данные
Профилирование — это анализ корректности и уникальности данных. Оно помогает систематизировать информацию, находя связи между БД (базами данных) или таблицами. Единого алгоритма профилирования нет, но можно выделить примерные этапы:
- сбор описательной статистики: минимум и максимум, среднее значений;
- сбор типов данных, длины значений и повторяющихся шаблонов в записях;
- разметка данных ключевыми словами или разделение на категории;
- обнаружение метаданных и оценка их точности;
- выявление связей и функциональных зависимостей между таблицами и переменными (например, связь между демографией клиентов и тенденцией их покупок можно использовать при проведении рекламных кампаний).
Профилирование данных позволило Департаменту парков и дикой природы Техаса узнать, что нужно целевой аудитории. Департамент отвечает за использование и сохранение парковых зон и водоемов штата. В 2016 году в организации заметили, что люди стали реже проводить время на природе.
После профилирования БД посетителей аналитики выяснили, что испаноязычные семьи среднего класса, живущие в пригороде Хьюстона, любят рыбалку. Это позволило департаменту включить озера вблизи Хьюстона в программу Neighborhood Fishin, которая разрешает ловить рыбу на озерах. Департамент повысил доходы благодаря продаже сертификатов на рыбную ловлю и сопутствующих товаров.


#4. Нормализуйте данные
Нормализация — приведение данных из разных источников и в разных форматах к одному виду. Данные могут включать в себя несхожие варианты написания полей. Например, скрипт импортирует данные о местоположении клиентов через веб-службы и файлы FTP. Одна локация может называться по-разному:
- Соединенные Штаты,
- Соединенные Штаты Америки,
- США.
Нормализация данных нужна для создания единых правил сохранения данных и устранения избыточности (случаев, когда один элемент хранится в разных таблицах базы данных).
#5. Уменьшайте количество данных произвольной формы
Заполняя анкеты, пользователи вводят информацию по-разному. Поэтому лучше фильтровать и форматировать данные на этапе ввода. Например, поле для номера телефона может подсказывать код страны и включать в себя разделители знаков.
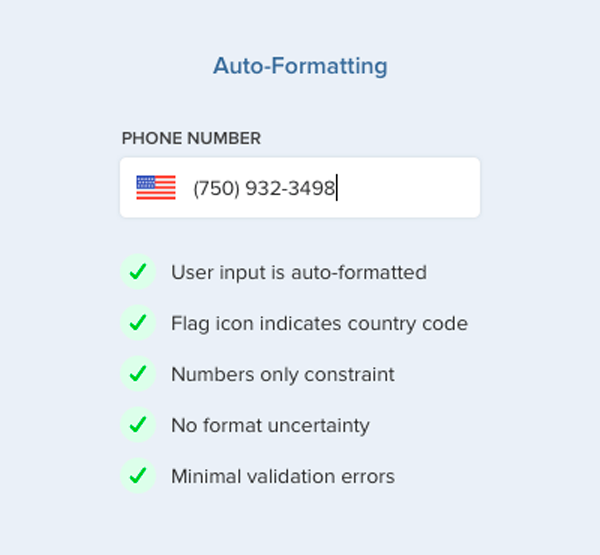
Источник: uxmovement.com
Нужно периодически проверять, не собирается ли избыточная и ненужная информация. Упрощайте заполнение полей и сокращайте их число, запрашивая только самые необходимые данные.
#6. Предотвращайте дублирование данных
Чтобы найти повторяющиеся записи в базе, можно:
- настроить триггеры, которые срабатывают, когда другие системы (Microsoft SQL Server, Oracle Database) пытаются записать дубликат,
- предлагать пользователю функцию слияния для объединения старых записей с новыми,
- периодически создавать отчеты для поиска дубликатов,
- проводить проверки при добавлении новых данных.
Не дублировать данные также поможет «умный» поиск по базе. Он умеет находить совпадения, несмотря на различия в написании, другой порядок слов, конкатенацию, использование синонимов и опечатки.

#7. Определите, кому принадлежат данные
Лучше назначить одного владельца данных — он будет отвечать за все операции и хранение. В зависимости от размера компании, это может быть CDO (директор по данным) или администратор БД. Когда за стратегию отвечает один человек, вырабатывается общая политика хранения и внесения данных. Это ускоряет бизнес-процессы.
Плюсы качественных данных
- Достоверность данных — основа для принятия решений в компании.
- Масштабирование системы, увеличение количества пользователей без краха базы и в автоматическом режиме.
- Простая интеграция и слияние данных из разных систем.
- Экономия времени и денег на поддержание качества данных.


