
Spotify, Netflix, YouTube: Откуда сервисы знают, какой контент нам понравится?
Как создают индивидуальные AI-алгоритмы для пользователей
Spotify предлагает музыку, основываясь на ваших предпочтениях, Netflix создает персонализированные обложки, YouTube знает, какова для вас оптимальная длительность видео.
Объясняем, как сервисы этому научились.
Когда все началось
Первые рекомендательные системы появились еще в 1990-х. Но прорыв случился в 2006. Компания Netflix тогда занималась прокатом DVD-дисков по почте. В то время она создала систему Cinematch. Ее задача — предсказывать оценки пользователей.
Отклонение у алгоритма составляло 0,9525. Примерно в то же время появилось The Echo Nest — агентство музыкального интеллекта при MIT Media Lab, которое применило передовой подход к персонализации музыки. Оно использовало алгоритмы для анализа аудио и текста, что позволяло идентифицировать музыку, рекомендовать треки, создавать плейлисты и проводить анализ.
Сейчас пользователи Netflix выбирают фильмы по другому принципу. Человек может поставить 10 баллов фильмам Феллини, но не готов смотреть похожий контент каждый день. Что же рекомендовать — боевики по вечерам и комедии на выходных?
В Netflix решили: чтобы рекомендация подошла человеку, она должна быть:
#1. Интересным: контент должен соответствовать предпочтениям пользователя, но при этом не быть предсказуемым.
#2. Неожиданным: рекомендации включают контент, который пользователь мог бы не найти самостоятельно, но который соответствует его скрытым предпочтениям.
#3. Своевременным: сервис учитывает время суток, день недели, праздники и даже тренды, чтобы предложить актуальные фильмы и сериалы.
Как работает алгоритм
Netflix применяет гибридный подход к рекомендациям, сочетая контентную фильтрацию, коллаборативную фильтрацию и глубокое обучение. Он анализирует десятки факторов:
- Что нравится пользователю — жанры, актеры, режиссеры, к которым он проявлял интерес.
- Что он уже посмотрел — насколько он досматривает фильмы и сериалы, ставит ли оценки.
- Какое у него настроение — выбор контента в разные дни и время суток.
- Что ему не нравится — фильмы и жанры, которые он игнорирует.
- Где он находится — в разных странах популярность контента отличается.
- Сколько ему лет — детям и взрослым показываются разные подборки.
Персонализированные обложки
Помимо рекомендаций, Netflix показывает пользователям разные варианты обложек для сериалов и фильмов. Все зависит от пола, возраста и интересов человека.

Обложки для сериала «Очень странные дела» / Netflix
Как выбираются обложки?
- A/B-тестирование — различные версии обложек показываются разным группам пользователей, анализируя их реакцию.
- Анализ предпочтений — если зритель любит определенного актера, его лицо может быть выведено на обложку.
- Поведенческий анализ — обложки адаптируются в зависимости от истории просмотров.
Например, для сериала «Очень странные дела» Netflix тестировал несколько обложек и оставил те, которые лучше всего привлекали внимание. Такой подход увеличивает вероятность выбора контента и делает пользовательский опыт более персонализированным.
Что такое коллаборативная фильтрация
Это самый популярный метод рекомендаций. Им пользуются Netflix, Last.fm, Amazon, eBay, AliExpress, YouTube и Facebook.
Вот как он работает:
Нужно составить матрицу оценок — таблицу, в которой будут перечислены все пользователи и их оценки.
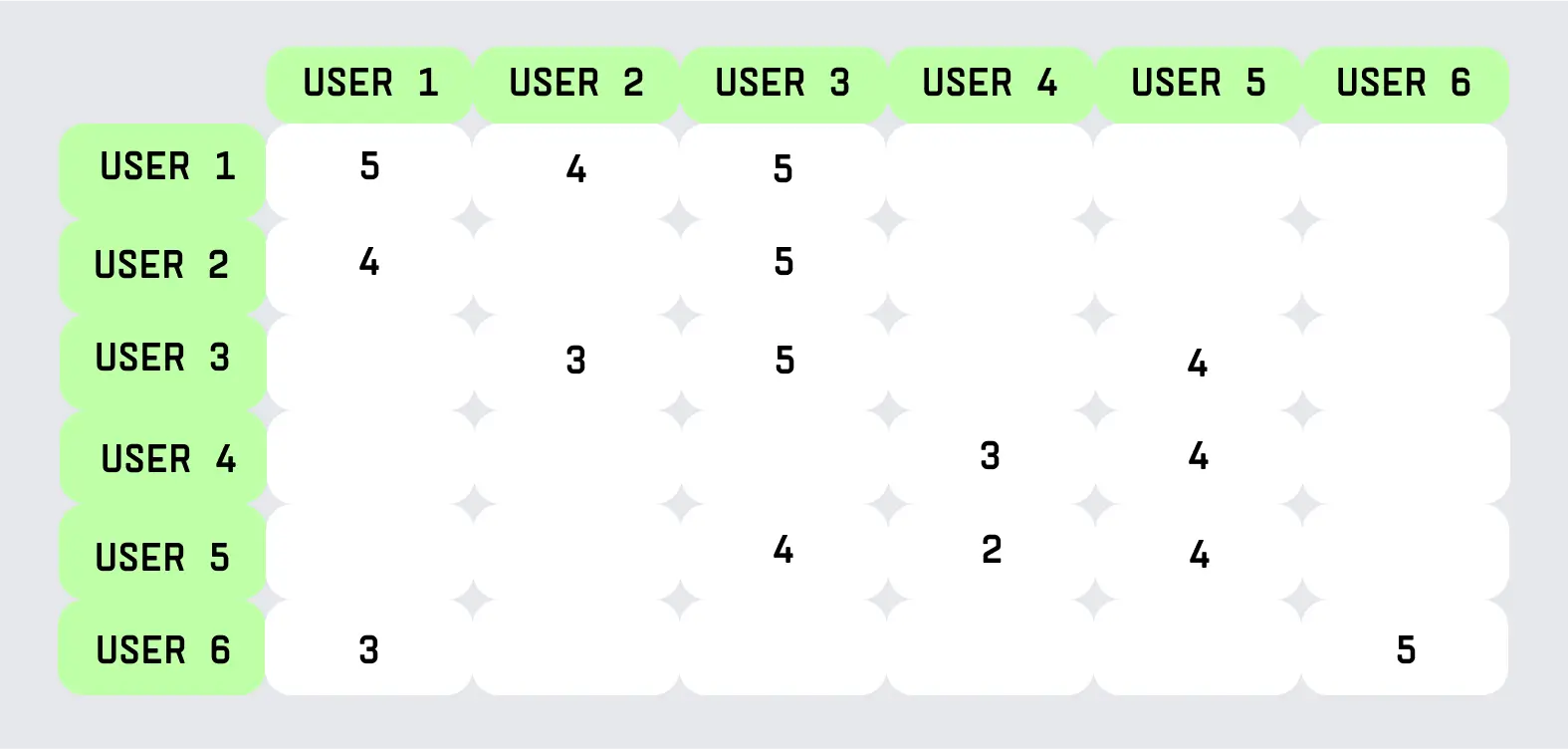
Если у разных пользователей схожие оценки, значит, их предпочтения совпадают. Если одному человеку нравится А и В, а другому А и С, то первому советуют С, второму — В.
Но у такого подхода есть минусы. Первый — огромный размер матрицы. Каждая строка — это пользователь, а столбец — объект оценки. Например, у сервиса Spotify более 130 млн треков, значит, столбцов должно быть столько же. Сложно работать с таким объемом в лайв-режиме.
Второй минус — непонятно, какие рекомендации будут полезны новым пользователям и тем, кто не ставит оценки.
Для решения этой проблемы пользователей могут объединять в кластеры по интересам. Но в таком случае рекомендации перестают быть индивидуальными.
Анализ аудиофайлов в Spotify
В Spotify в нейросеть загружают каждый трек. Он проходит через все слои. В результате мы видим разные характеристики трека: размер, темп, громкость, гармонию и другие. Это помогает Spotify уловить сходство песен и позволяет рекомендовать треки малоизвестных артистов с небольшим числом оценок.
Как работает Spotify Discover каждую неделю
Что такое Discover Weekly на Spotify?
Это персонализированный плейлист, который обновляется каждую неделю и содержит 30 песен, подобранных специально для каждого пользователя. Его основная цель — помочь слушателям открывать новую музыку, которая соответствует их вкусам, но которую они, вероятно, еще не слышали. Как работает Discover Weekly? Для создания этого плейлиста Spotify использует три основные алгоритмические модели: коллаборативную фильтрацию, обработку естественного языка (NLP) и анализ аудиофайлов.
Коллаборативная фильтрация (Collaborative Filtering)
Этот алгоритм Discover Weekly основан на анализе взаимодействия пользователей с музыкой. Spotify отслеживает, какие песни вы слушаете, добавляете в плейлисты, лайкаете или пропускаете. Затем сервис сравнивает вашу активность с другими пользователями, которые имеют схожие предпочтения, и предлагает вам треки, которые понравились им, но которых вы еще не слушали.
Для этого процесса применяется технология матричной факторизации (Matrix Factorization). Она помогает уменьшить огромное количество данных о пользователях и их прослушиваниях до более компактной матрицы, выявляя скрытые связи между слушателями и песнями. Например:
- Если у вас и у другого пользователя есть одинаковые любимые исполнители, но он слушает еще одного музыканта, которого вы не знаете, Spotify может порекомендовать вам этого исполнителя.
- Если вы часто слушаете альтернативный рок и добавляете песни The Killers и Arctic Monkeys в плейлист, а другие пользователи, которые делают то же самое, также часто слушают Cage The Elephant, вы, вероятно, получите песню от этой группы в свой Discover Weekly.


Обработка естественного языка (Natural Language Processing, NLP)
Рекомендация музыки на Spotify использует еще один мощный инструмент — анализ текстов с помощью обработки естественного языка (NLP). Алгоритмы просматривают миллионы музыкальных статей, блогов, рецензий и постов в соцсетях, чтобы понять, как и в каких контекстах упоминаются песни и исполнители.
Например:
- Если определенный новый трек часто упоминается в позитивном ключе в статьях об инди-роке, а вы часто слушаете инди-рок, Spotify может порекомендовать этот трек.
- Если в медиа появляются списки «Лучшие chill-out треки этого месяца», Spotify может использовать эти данные, чтобы дополнить ваши рекомендации.
Этот метод особенно полезен для новой или малоизвестной музыки, которая еще не получила много прослушиваний, но имеет высокий потенциал быть интересной для определенной аудитории.
Анализ аудиофайлов (Raw Audio Analysis)
Чтобы сделать рекомендации еще точнее, Spotify использует глубокий анализ самих аудиофайлов. Нейронная сеть (машинное обучение) анализирует каждую песню, определяя ее темп, тональность, ритм, энергичность и общую атмосферу.
Это помогает:
- Выявлять песни с подобной динамикой и настроением, даже если они принадлежат к разным жанрам.
- Рекомендовать новую музыку на основе аудиохарактеристик ваших любимых треков, даже если она еще не имеет много упоминаний в медиа или прослушиваний среди пользователей.
- Заполнять пробелы в рекомендациях, когда коллаборативная фильтрация и NLP не дают достаточно данных.
Например, если вы часто слушаете медленную, меланхоличную инструментальную музыку, алгоритм может найти треки с подобным темпом и тональностью, даже если они принадлежат к другим жанрам, например, пост-року или классической музыке.
Как все это комбинируется в Discover Weekly
Spotify комбинирует результаты всех трех моделей для создания уникального плейлиста Discover Weekly для каждого пользователя. Это позволяет учитывать не только статистическую вероятность того, что вам понравится песня, но и контекст того, как она звучит, как ее описывают в медиа и что о ней думают слушатели с похожими предпочтениями.
Эта многоуровневая рекомендательная система помогает Spotify оставаться одним из лучших сервисов для открытия новой музыки, создавая рекомендации, которые кажутся естественными, интересными и максимально персонализированными.
Bandits for Recommendations as Treatments (BaRT)
Еще Spotify задействует AI-систему BaRT (Bandits for Recommendations as Treatments). Ее задача — создать для каждого пользователя индивидуальный домашний экран. На основе этой системы работают рекомендации сервиса. Их составление включает два этапа. Первый использует информацию о человеке: какую музыку он слушает, что пропускает, а что лайкает, какие плейлисты создает и даже где находится.
На втором этапе система анализирует информацию о мире: музыканты и песни, которые похожи на тех, что слушаете вы, их популярность и востребованность.
Также сервис объясняет людям свой выбор. Созданные плейлисты имеют названия. Например, «Вернуться в прошлое». Это говорит человеку, почему ему рекомендуют конкретный плейлист и что он там услышит. Согласно исследованию Spotify, именно эти объяснения играют главную роль в выборе пользователей.


Рекомендации YouTube
Система платформы получает миллионы роликов, но пользователю рекомендует лишь несколько десятков. Над этим работают две сверточные нейросети — candidate generation и ranking. Первая сверточная нейронная сеть выбирает из всех видео только те, которые понравятся пользователю. Вторая распределяет их — от более интересных к менее.
Алгоритм учитывает всю историю поведения пользователя на платформе, а также контекст. То есть время, возраст, пол и местонахождение человека. Кроме того, система проводит A/B-тестирование. Человеку показывают разные подборки. Если какая-то понравилась больше других, система адаптирует рекомендации, понимая, что подходит пользователю.
Также важен CTR (Click-Through Rate, кликабельность) — отношение количества людей, которые начали смотреть видео, к людям, которые увидели его в рекомендациях. Согласно справке YouTube, средний показатель CTR для половины видео составляет от 2% до 10%.
Но это не самая важная метрика: если бы YouTube учитывал только ее, нам бы показывали кликбейтные видео. Нейросети используют для ранжирования expected watch time (ожидаемое время просмотра видео). Чем оно больше, тем выше шансы ролика попасть в рекомендации.
Как YouTube совершенствует рекомендательный алгоритм?
- Задействование глубокого обучения и нейросетей для анализа поведения пользователей.
- Постоянное обновление моделей машинного обучения на основе новых данных.
- Учет этических аспектов и борьба с манипуляциями (например, фильтрация вредоносного контента).
- Персонализация рекомендаций на основе сходства между зрителями и их интересами.
Таким образом, YouTube не просто анализирует поведение пользователей, но и пытается предсказать их интересы, подбирая контент, который обеспечит максимально долгий и увлекательный просмотр.
Выводы
Сервисы, такие как YouTube, Spotify и Netflix, стали мастерами персонализации, применяя сложные алгоритмы и машинное обучение. Они анализируют предпочтения пользователей, историю просмотров и поведенческие паттерны, чтобы предлагать контент, который идеально соответствует интересам человека. Коллаборативная фильтрация, обработка естественного языка и анализ аудиофайлов помогают предсказывать музыкальные предпочтения, формировать плейлисты и даже адаптировать обложки фильмов. Такие технологии не только улучшают пользовательский опыт, но и удерживают аудиторию, делая взаимодействие с платформами максимально интуитивно понятным и увлекательным.
Авторы: Алексей Симончук, Ольга Мельник


